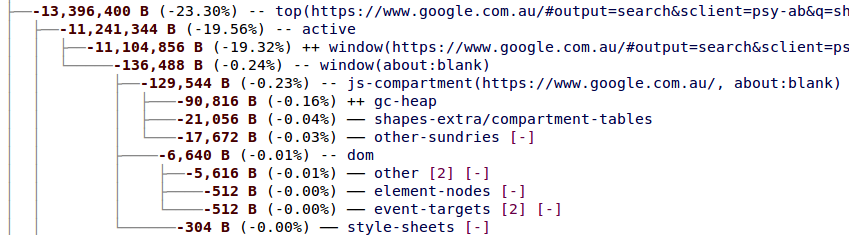
Lots of important MemShrink stuff has happened in the last 27 days: 22 bugs were fixed, and some of them were very important indeed.
Images
Timothy Nikkel fixed bug 847223, which greatly reduces peak memory consumption when loading image-heavy pages. The combination of this fix and the fix from bug 689623 — which Timothy finished earlier this year and which shipped in Firefox 24 — have completely solved our longstanding memory consumption problems with image-heavy pages! This was the #1 item on the MemShrink big ticket items list.
To give you an idea of the effect of these two fixes, I did some rough measurements on a page containing thousands of images, which are summarized in the graph below.
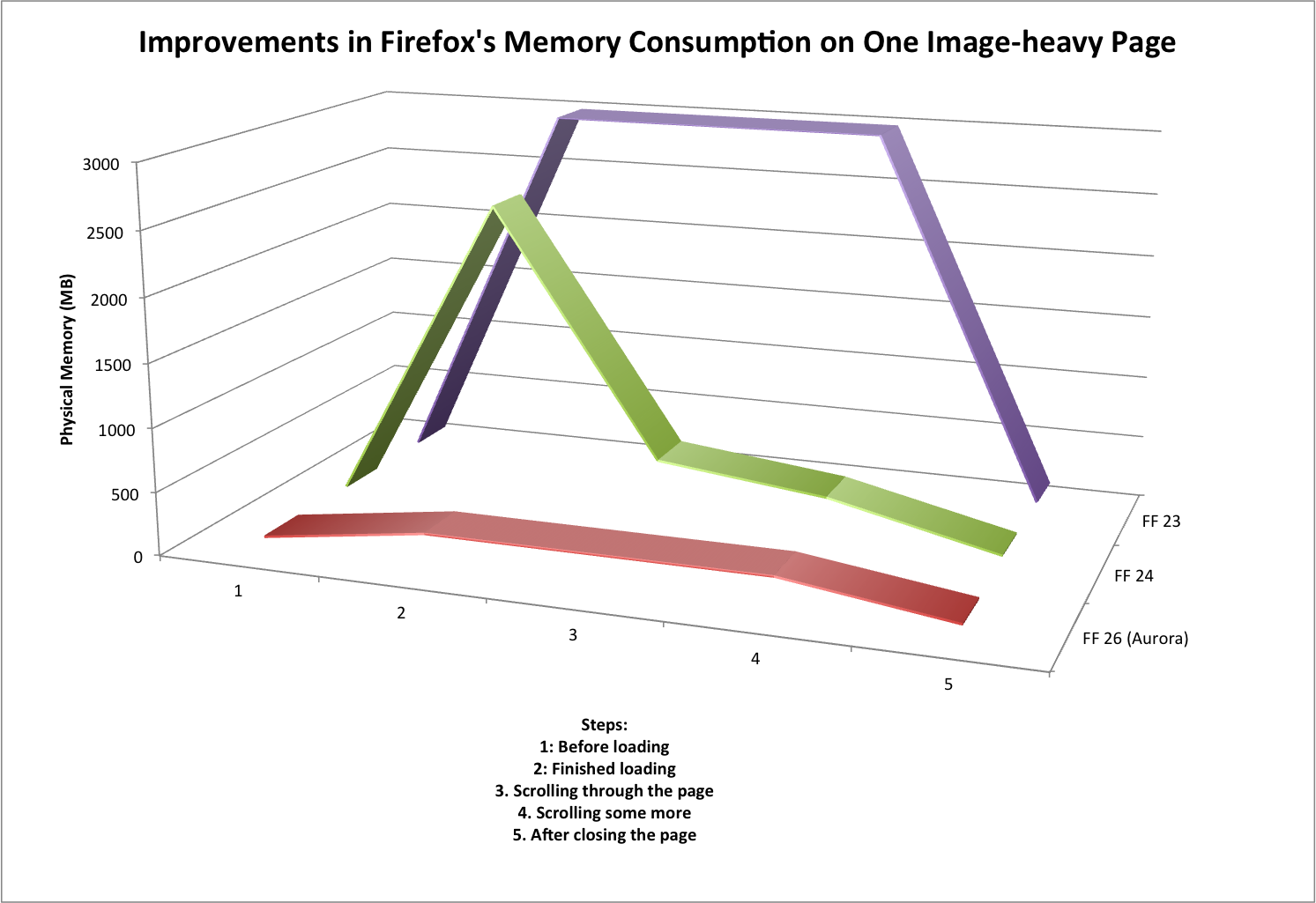
First consider Firefox 23, which had neither fix, and which is represented by the purple line in the graph. When loading the page, physical memory consumption would jump to about 3 GB, because every image in the page was decoded (a.k.a. decompressed). That decoded data was retained so long as the page was in the foreground.
Next, consider Firefox 24 (and 25), which had the first fix, and which is represented by the green line on the graph. When loading the page, physical memory consumption would still jump to almost 3 GB, because the images are still decoded. But it would soon drop down to a few hundred MB, as the decoded data for non-visible images was discarded, and stay there (with some minor variations) while scrolling around the page. So the scrolling behaviour was much improved, but the memory consumption spike still occurred, which could still cause paging, out-of-memory problems, and the like.
Finally consider Firefox 26 (currently in the Aurora channel), which has both fixes, and which is represented by the red line on the graph. When loading the page, physical memory jumps to a few hundred MB and stays there. Furthermore, the loading time for the page dropped from ~5 seconds to ~1 second, because the unnecessary decoding of most of the images is skipped.
These measurements were quite rough, and there was quite a bit of variation, but the magnitude of the improvement is obvious. And all these memory consumption improvements have occurred without hurting scrolling performance. This is fantastic work by Timothy, and great news for all Firefox users who visit image-heavy pages.
[Update: Timothy emailed me this: “Only minor thing is that we still need to turn it on for b2g. We flipped the pref for fennec on central (it’s not on aurora though). I’ve been delayed in testing b2g though, hopefully we can flip the pref on b2g soon. That’s the last major thing before declaring it totally solved.”]
[Update 2: This has hit Hacker News.]
NuWa
Cervantes Yu landed Nuwa, which is a low-level optimization of B2G. Quoting from the big ticket items list (where this was item #3):
Nuwa… aims to give B2G a pre-initialized template process from which every subsequent process will be forked… it greatly increases the ability for B2G processes to share unchanging data. In one test run, this increased the number of apps that could be run simultaneously from five to nine
Nuwa is currently disabled by default, so that Cervantes can fine-tune it, but I believe it’s intended to ship with B2G version 1.3. Fingers crossed it makes it!
Memory Reporting
I made some major simplifications to our memory reporting infrastructure, paving the way for future improvements.
First, we used to have two kinds of memory reporters: uni-reporters (which report a single measurement) and multi-reporters (which report multiple measurements). Multi-reporters, unsurprisingly, subsume uni-reporters, and so I got rid of uni-reporters, which simplified quite a bit of code.
Second, I removed about:compartments and folded its functionality into about:memory. I originally created about:compartments at the height of our zombie compartment problem. But ever since Kyle Huey made it more or less impossible for add-ons to cause zombie compartments, about:compartments has hardly been used. I was able to fold about:compartments’ data into about:memory, so there’s no functionality loss, and this change simplified quite a bit more code. If you visit about:compartments now you’ll get a message telling you to visit about:memory.
Third, I removed the smaps (size/rss/pss/swap) memory reporters. These were only present on Linux, they were of questionable utility, and they complicated about:memory significantly.
Finally, I fixed a leak in about:memory. Yeah, it was my fault. Sorry!
Summit
The Mozilla summit is coming up! In fact, I’m writing this report a day earlier than normal because I will be travelling to Toronto tomorrow. Please forgive any delayed responses to comments, because I will be travelling for almost 24 hours to get there.