
Just a short note to say that I’m moving my blogging to https://www.thebanners.uk/standard8/
-
Recent Posts
Related Links
Tags
Archives
Meta
Just a short note to say that I’m moving my blogging to https://www.thebanners.uk/standard8/
A while ago, Dave Townsend wrote a commit hook for Mercurial for ESLint. I’ve just extended the code to create a commit hook for Git users.
To install the Git hook, go into the top-level of your mozilla-central Git repository, and enter (assuming you don’t already have a pre-commit hook):
ln -s ../../tools/git/git-lint-commit-hook.sh .git/hooks/pre-commit
That’s all you need to do. If you do have an existing pre-commit hook, then you’ll need to incorporate running git-lint-commit-hook.sh as well.
This will run ESLint on the affected files when committing and print warnings if they fail. The commit will still happen, but you should fix the issues up before pushing them for review.
Coming soon:
As Jared has been posting, we have gradually been enabling ESLint rules for the Firefox code base.
We’ve created a page on devmo for ESLint help & hints.
In particular, there’s links to details on how to integrate it into your editor and also hints and tips for fixing issues.
If you have questions or comments, feel free to join us in the #eslint channel on IRC.
I’ve created an example repository for how you might set up tools to help development of a WebExtension. Whilst there are others around, I’ve not heard of one that includes examples of tools for testing and auditing your extension.
It is based on various ideas from projects I’ve been working alongside recently.
The repository is intended to either be used as a starting point for constructing a new WebExtension, or you can take the various components and integrate them into your own repository.
It is based around node/npm and the web-ext command line tool to keep it simple as possible. In addition it contains setup for:
All of these are also run automatically on landing or pull request via Travis Ci with Coveralls providing code coverage reports.
Finally, there’s a tool enabled on the repository for helping to keep modules up to date.
If you find it helpful, let me know in the comment section. Please raise any issues that you find, or submit pull requests, I welcome either.
This is the third of some posts I’m writing about how we implement and work on the desktop and standalone parts of Firefox Hello. You can find the previous posts here.
The Showcase
One of the most useful parts of development for Firefox Hello is the User Interface (UI) showcase. Since all of the user interface for Hello is written in html and JavaScript, and is displayed in the content scope, we are able to display them within a “normal” web page with very little adjustment.
So what we do is to put almost all our views onto a single html page at representative sizes. The screen-shot below shows just one view from the page, but those buttons at the top give easy access, and in reality there’s lots of them (about 55 at the time of writing).
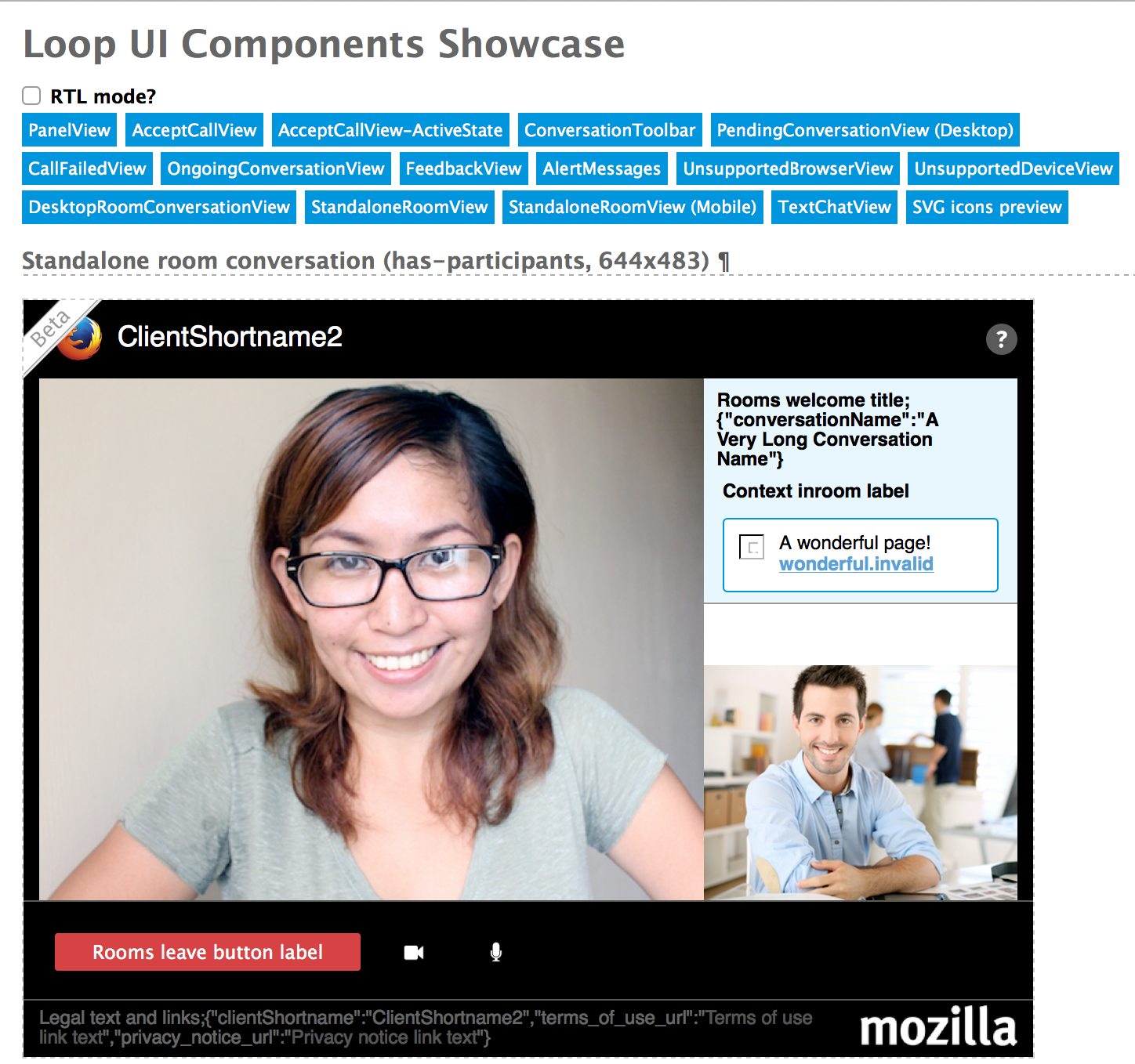
UI Showcase showing a standalone (link-clicker) view
Faster Development
The showcase has various advantages that help us develop faster:
There’s one other “feature” of the showcase as we’ve got it today – we don’t pick up the translated strings, but rather the raw string label. This tends to give us longer strings than are used normally for English, which it turns out is an excellent way of being able to detect some of the potential issues for locales which need longer strings.
Structure of the showcase
The showcase is a series of iframes. We load individual react components into each iframe, sometimes loading the same component multiple times with different parameters or stores to get the different views. The rest of the page is basically just structure around display of the views.
The iframes does have some downsides – you can’t live edit css in the inspector and have it applied across all the views, but that’s minor compared to the advantages we get from this one page.
Future improvements
We’re always looking for ways we can improve how we work on Hello. We’ve recently improved the UI showcase quite a bit, so I don’t think we have too much on our outstanding list at the moment.
The only thing I’ve just remembered is that we’ve commented it would be nice to have some sort of screen-shot comparison, so that we can make changes and automatically check for side-effects on other views.
We’d also certainly be interested in hearing about similar tools which could do a similar job – sharing and re-using code is definitely a win for everyone involved.
Interested in learning more?
If you’re interested in learning more about the UI-showcase, then you can find the code here, try it out for yourself, or come and ask us questions in #loop on irc.
If you want to help out with Hello development, then take a look at our wiki pages, our mentored bugs or just come and talk to us.
This is the second of some posts I’m writing about how we implement and work on the desktop and standalone parts of Firefox Hello. The first post was about our use of Flux and React, this second post is about the architecture.
In this post, I will give an overview of the Firefox browser software architecture for Hello, which includes the standalone UI.
User-visible parts of Hello
Although there’s many small parts to Hello, most of it is shaped by what is user visible:
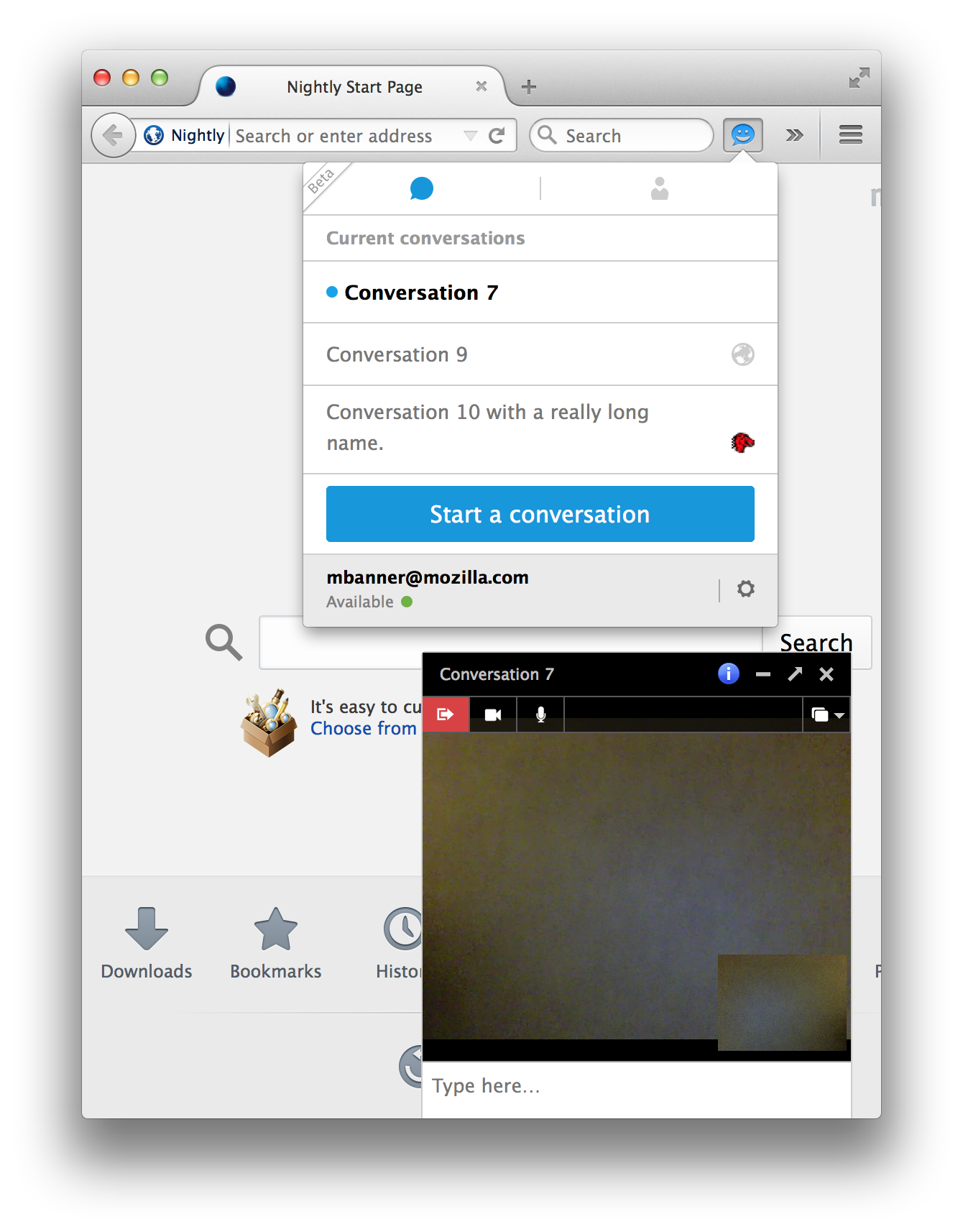
Firefox Hello Desktop UI (aka Link-Generator)

Hello Standalone UI (aka Link-clicker)
Firefox Browser Architecture for Hello
The in-browser part of Hello is split into three main areas:
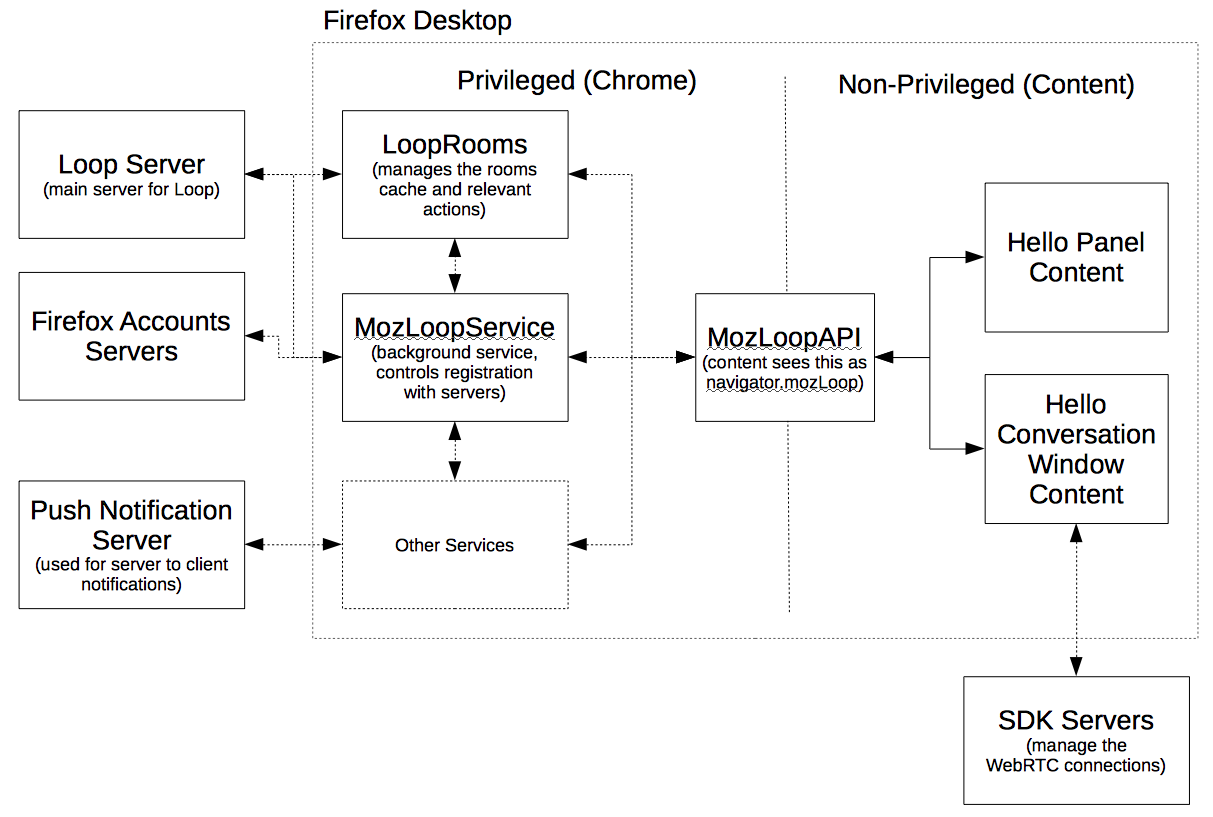
Outline of Hello’s Desktop Architecture
MozLoopAPI is our way of exposing small bits of the privileged gecko (link) code to the about: pages running in content. We inject a navigator.mozLoop object into the content pages when they are loaded. This allows various functions and facilities to be exposed, e.g. access to a backend cache of the rooms list (which avoids multiple caches per window), and a similar backend store of contacts.
Standalone Architecture
The Standalone UI is simply a web page that’s shown in any browser when a user clicks a conversation link.
The conversation flow is in the standalone UI is very similar to that of the conversation window, so most of the stores and supporting files are shared. Most of the views for the Standalone UI are currently different to those from the desktop – there’s been a different layout, so we need to have different structures.
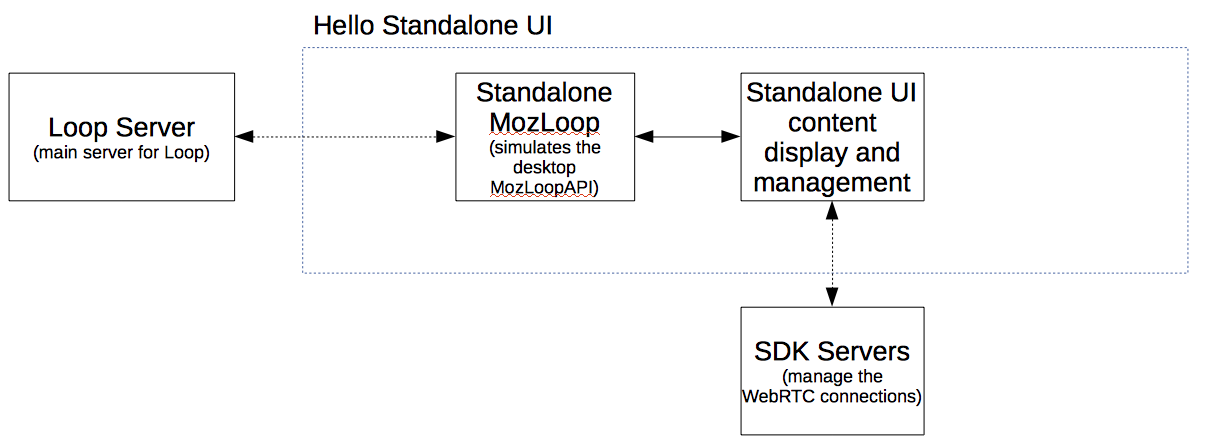
Outline of Hello’s Standalone UI Architecture
File Architecture as applied to the code
The authoritative location for the code is mozilla-central it lives in the browser/components/loop directory. Within that we have:
Future Work
There’s a couple of likely parts of the architecture that we’re going to rework soon.
Firstly, with the current push to electrolysis, we’re replacing the current exposed MozLoopAPI with a message-based RPC mechanism. This will then let us run the panel and conversation window in the separated content process.
Secondly, we’re currently reworking some of the UX and it is moving to be much more similar between desktop and standalone. As a result, we’re likely to be sharing more of the view code between the two.
Interested in learning more?
If you’re interested in learning more about Hello’s architecture, then feel free to dig into the code, or come and ask us questions in #loop on irc.
If you want to help out with Hello development, then take a look at our wiki pages, our mentored bugs or just come and talk to us.
On Firefox Hello, we recently added the eslint linter to be run against the Hello code base. We started of with a minimal set of rules, just enough to get us something running. Now we’re working on enabling more rules.
Since we enabled it, I feel like I’m able to iterate faster on patches. For example, if just as I finish typing I see something like:
 I know almost immediately that I’ve forgotten a closing bracket and I don’t have to run anything to find out – less run-edit-run cycles.
I know almost immediately that I’ve forgotten a closing bracket and I don’t have to run anything to find out – less run-edit-run cycles.
Now I think about it, I’m realising it has also helped reduced the amount of review nits on my patches – due to trivial formatting mistakes being caught automatically, e.g. trailing white-space or missing semi-colons.
Talking about reviews, as we’re running eslint on the Hello code, we just have to apply the patch, and run our tests, and we automatically get eslint output:
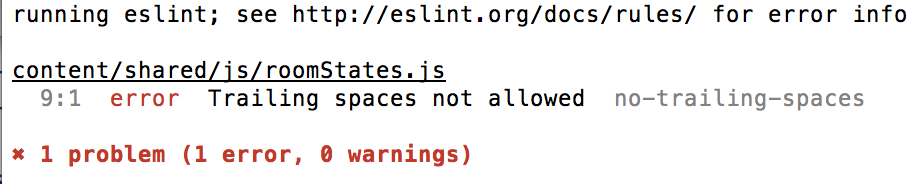 Hopefully our patch authors will be running eslint before uploading the patch anyway, but this is an additional test, and a few less things that we need to look at during review which helps speed up that cycle as well.
Hopefully our patch authors will be running eslint before uploading the patch anyway, but this is an additional test, and a few less things that we need to look at during review which helps speed up that cycle as well.
I’ve also put together a global config file for eslint (see below), that I use for outside of the Hello code, on the rest of the Firefox code base (and other projects). This is enough, that, when using it in my editor it gives me a reasonable amount of information about bad syntax, without complaining about everything.
I would definitely recommend giving it a try. My patches feel faster overall, and my test runs are for testing, not stupid-mistake catching!
Want more specific details about the setup and advantages? Read on…
My Setup
For my setup, I’ve recently switched to using Sublime. I used to use Aquamacs (an emacs variant), but when eslint came along, the UI for real-time linting within emacs didn’t really seem great.
I use sublime with the SublimeLinter and SublimeLinter-contrib-eslint packages. I’m told other editors have eslint integration as well, but I’ve not looked at any of them.
You need to have eslint installed globally, or at least in your path, other than that, just follow the installation instructions given on the SublimeLinter page.
One configuration I change I did have to make to the global configuration:
{
"extensions":
[
"jsm",
"jsx",
"sjs"
]
}
This makes sure sublime treats the .jsm and .jsx files as javascript files, which amongst other things turns on eslint for those files.
Global Configuration
I’ve uploaded my global configuration to a gist, if it changes I’ll update it there. It isn’t intended to catch everything – there’s too many inconsistencies across the code base for that to be sensible at the moment. However, it does at least allow general syntax issues to be highlighted for most files – which is obviously useful in itself.
I haven’t yet tried running it across the whole code base via eslint on the command line – there seems to be some sort of configuration issue that is messing it up and I’ve not tracked it down yet.
Firefox Hello’s Configuration
The configuration files for Hello can be found in the mozilla-central source. There’s a few of these because we have both content and chrome code, and some of the content code is shared with a website that can be viewed by most browsers, and hence isn’t currently able to use all the es6 features, whereas the chrome code can. This is another thing that eslint is good for enforcing.
Our eslint configuration is evolving at the moment, as we enable more rules, which we’re tracking in this bug.
Any Questions?
Feel free to ask any questions about eslint or the setup in the comments, or come and visit us in #loop on irc.mozilla.org (IRC info here).
This is the first of a few posts that I’m planning regarding discussion about how we implement and work on the desktop and standalone parts of Firefox Hello. We’ve been doing some things in different ways, which we have found to be advantageous. We know other teams are interested in what we do, so its time to share!
Content Processes
First, a little bit of architecture: The panels and conversation window run in content processes (just like regular web pages). The conversation window shares code with the link-clicker pages that are on hello.firefox.com.
Hence those parts run very much in a web-style, and for various reasons, we decided to create them in a web-style manner. As a result, we’ve ended up with using React and Flux to aid our development.
I’ll detail more about the architecture in future posts.
The Flux Pattern
Flux is a recommended pattern for use alongside React, although I think you could use it with other frameworks as well. I’ll detail here about how we use Flux specifically for Hello. As Flux is a pattern, there’s no one set standard and the methods of implementation vary.
Flux Overview
The main parts of a flux system are stores, components and actions. Some of this is a bit like an MVC system, but I find there’s better definition about what does what.
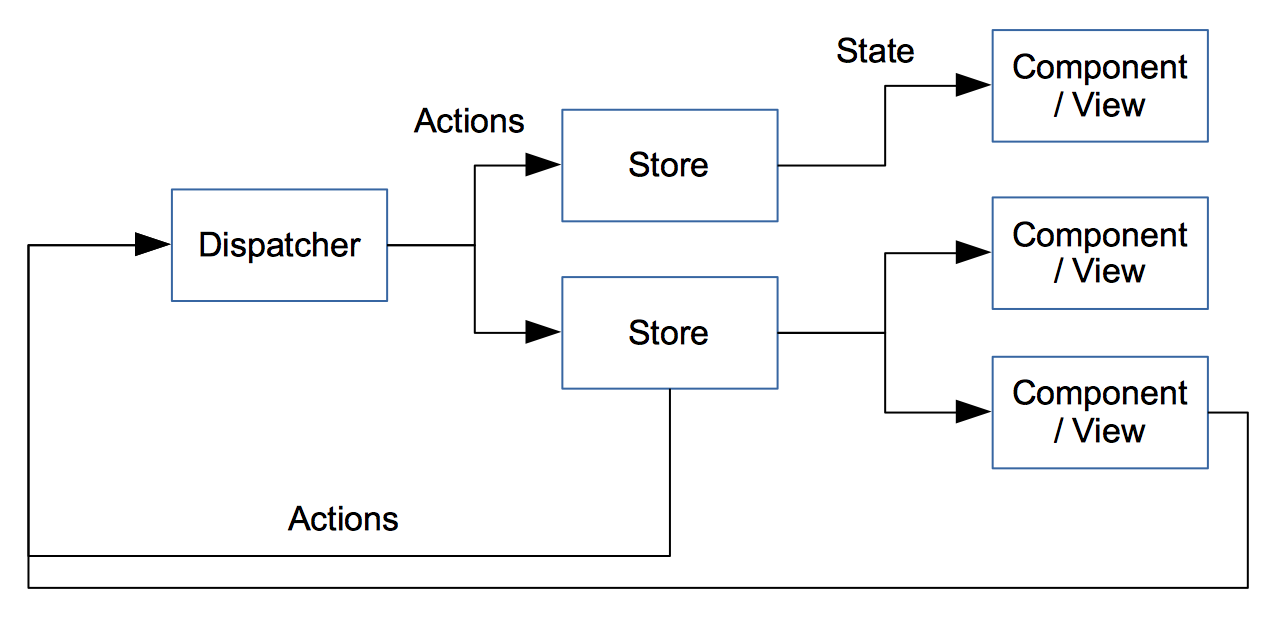 An action is effectively a result of an event, that changes the system. For example, in Loop, we use actions for user events, but we also use them for any data incoming from the server.
An action is effectively a result of an event, that changes the system. For example, in Loop, we use actions for user events, but we also use them for any data incoming from the server.
A store contains the business logic. It listens to actions, when it receives one, it does something based on the action and updates its state appropriately.
A component is a view. The view has a set of properties (passed in values) and/or state (the state is obtained from the store’s state). For a given set of properties and state, you always get the same layout. The components listen for updates to the state in the stores and update appropriately.
We also have a dispatcher. The dispatcher dispatches actions to interested stores. Only one action can be processed at any one time. If a new action comes in, then the dispatcher queues it.
Actions are always synchronous – if changes would happen due to external stimuli then these will be new actions. For example, this prevents actions from blocking other actions whilst waiting for a response from the server.
What advantages do we get?
For Hello, we find the flux pattern fits very nicely. Before, we used a traditional MVC model, however, we kept on getting in a mess with events being all over the place, and application logic being wrapped in amongst the views as well as the models.
Now, we have a much more defined structure:
React provides the component structure, it has defined ways of tracking state and properties, and the re-rendering on state change gives much automation. Since it encourages the separation of immutable properties, a whole class of inadvertent errors is eliminated.
There’s also many advantages with debugging – we have a flag that lets us watch all the actions going through the system, so its much easier to track what events are taking place and the data passed with them. This combined with the fact that actions have limited scope, helps with debugging the data flows.
Simple Unit Testing
For testing, we’re able to do unit testing in a much simpler fashion:
it("should render a muted local audio button", function() {
var comp = TestUtils.renderIntoDocument(
React.createElement(sharedViews.MediaControlButton, {
scope: "local",
type: "audio",
action: function(){},
enabled: false
}));
expect(comp.getDOMNode().classList.contains("muted")).eql(true);
});
it("should set the state to READY", function() {
store.setupRoomInfo(new sharedActions.SetupRoomInfo(fakeRoomInfo));
expect(store._storeState.roomState).eql(ROOM_STATES.READY);
});
We therefore have many tests written at the unit test level. Many times we’ve found and prevented issues whilst writing these tests, and yet, because these are all content based, we can run the tests in a few seconds. I’ll go more into testing in a future post.
References
Here’s a few references to some of the areas in our code base that are good example of our flux implementation. Note that behind the scenes, everything is known as Loop – the codename for the project.
Conclusion and more coming…
We’ve found using the flux model is much more organised than we were with an MVC, possibly its just a better defined methodology, but it gave us the structure we badly missing. In future posts, I’ll discuss about our development facilities, more about the desktop architecture and whatever else comes up, so please do leave questions in the comments and I’ll try and answer them either direct or with more posts.
As part of tidying up some of our websites we’re moving the existing planet.mozillamessaging.com to planet.mozilla.org/thunderbird.
Both sites are currently functional and show the same blogs, however planet.mozillamessaging.com will become a redirect very soon. When the redirect happens, you’ll hopefully be fine, but you may want to update your links and feed urls now.
I was going to write this post yesterday, didn’t quite complete it and so it gets an updated with activities of the last 24 hours as well.
Some people had noticed the extra long delay between the first and second betas of Thunderbird 13. Whilst we sometimes don’t publish a beta every week, in this case we were busy finishing off a transition that had started some months previously.
The transition has merged the Thunderbird build automation system onto the same system used by Firefox – we are now running side-by-side, using the same hardware.
The whole transition has been a big benefit to Thunderbird, we’ve brought the Thunderbird build systems up to date, removing a lot of the hacks that were specific to our comm-central based builds. In doing so, we’ve picked up lots of new things: an up to date tinderboxpushlog, self-serve build apis to allow any developer to request new builds and cancel running ones, the hg share extension reducing check out and build times, the latest release automation which includes automatic emails and better parallelism. I’m sure that’s just a small selection.
Ongoing this will help keep Thunderbird much more up to date, we’ll be able to keep in sync with Firefox a lot easier when it comes to the mechanics of building, signing etc. I’ve also got some ideas for where we can add/improve automation for both Firefox and Thunderbird, so I’ll be putting those forward soon.
Back to the events over the last 24 hours. Yesterday we finished shipping the second beta of Thunderbird 13, this was the first release that had been run on the Firefox system, and took about a week or two to complete as many parts had been missing or not quite there. A few hours after that I sent the go for the third beta, and guess what, we’ve just pushed that build out to the beta channel. Apart from a couple of minor hiccups, the automation worked fine. Wow, awesome!
This is a great achievement, and Thunderbird build and release is now in much better shape than it was a few months ago. I’d like to thank John O’Duinn and Chris Cooper for making this happen, and a huge thanks to John Hopkins who I know spent many hours working on the actual transition and the rest of the release engineering team who have been helping out with questions, solutions and fixes.