How do you reason about a codebase the size of Firefox’s? How do you figure out who calls the function you’re messing with, without losing your context in an endless stream of false-positive-infested greps?
You bust out DXR, Mozilla’s code search and static analysis tool.
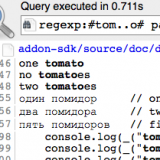
DXR begins with the technology that powered the much-missed Google Code Search: inverted trigram indices which turbo-charge a fast regex implementation. It then adds a static analysis engine that rides sidecar with the C++ compiler, noting the location and relationship of code constructs. As a result, you can not only do regex searches that return as fast as you can type, but you can also ask “Who subclasses this?” “Where is this macro defined?” and “Where are all the references to this type?”
Last week saw the first production push of DXR since its major redesign early this year. It now rides on a modern foundation of Flask and WSGI; blocks regressions with a looser-coupled, higher-coverage test harness; and delivers a glut of new features and fixes. Here are some highlights.
Indexing and Search
- Faster, index-accelerated performance on many kinds of queries
- Querying for callers and callees
- Ability to find callers of constructors
- Recognition of typedefs
- Links to macro references
- Links from class declarations to class definitions
- Better detection of JS symbols
- Differentiation between a const and a non-const function of the same name
- Handy-dandy path breadcrumbs so you can tell what file you’re reading and move around in the source tree
- Sorted folder listings
- First-class support for mobile and WebKit
Infrastructure
- Several thousand lines less code
- Slimmer builds which consist of only data, not Python code, making development easier and deployment cleaner
- Replacement of our ad hoc process pooling implementation with Python 3’s concurrent.futures (knocking off about 200 lines)
- Flask-powered WSGI instead of old-school CGI
- Redesigned URLs for MXR parity and future extensibility
- A Vagrant box to ease the spin-up of new contributors
- A brand new test harness, exercised by a Vagrant-based Jenkins job
Bug Fixes
- Trouble-free entry of queries. (Bad JS! Go sit in the corner.)
- A fix for a crash when doing negated phrase matching
- Fixes for URL- and HTML-escaping bloopers, including shameful XSSes
- No more duplicate result lines in some types of queries
What’s Next?
I am pleased to announce that the next release is scheduled for one minute from now. Yes, DXR is now under continuous deployment: if it passes tests, it goes up on the servers, eliminating human bottlenecks and errors and letting us deliver goodies—and get feedback—promptly. A great many UI and capability enhancements are on deck next, along with speedy new server hardware to make queries even snappier.
Want to look under the hood of DXR? Check out https://wiki.mozilla.org/DXR, and join us in #static on irc.mozilla.org. Happy hacking!
Nicholas Nethercote wrote on
:
wrote on
:
Erik Rose wrote on
:
wrote on
:
aleth wrote on
:
wrote on
:
Erik Rose wrote on
:
wrote on
: