TL;DR, An Introduction
This post originally appeared on Mozilla Hacks.
Fuzzing, or fuzz testing, is an automated approach for testing the safety and stability of software. It’s typically performed by supplying specially crafted inputs to identify unexpected or even dangerous behavior. If you’re unfamiliar with the basics of fuzzing, you can find lots more information in the Firefox Fuzzing Docs and the Fuzzing Book.
For the past 3 years, the Firefox fuzzing team has been developing a new fuzzer to help identify security vulnerabilities in the implementation of WebAPIs in Firefox. This fuzzer, which we’re calling Domino, leverages the WebAPIs’ own WebIDL definitions as a fuzzing grammar. Our approach has led to the identification of over 850 bugs. 116 of those bugs have received a security rating. In this post, I’d like to discuss some of Domino’s key features and how they differ from our previous WebAPI fuzzing efforts.
Fuzzing Basics
Before we begin discussing what Domino is and how it works, we first need to discuss the types of fuzzing techniques available to us today.
Types of Fuzzers
Fuzzers are typically classified as either blackbox, greybox, or whitebox. These designations are based upon the level of communication between the fuzzer and the target application. The two most common types are blackbox and greybox fuzzers.
Blackbox Fuzzing
Blackbox fuzzing submits data to the target application with essentially no knowledge of how that data affects the target. Because of this restriction, the effectiveness of a blackbox fuzzer is based entirely on the fitness of the generated data.
Blackbox fuzzing is often used for large, non-deterministic applications or those which process highly structured data.
Whitebox Fuzzing
Whitebox fuzzing enables direct correlation between the fuzzer and the target application in order to generate data that satisfies the application’s “requirements”. This typically involves the use of theorem solvers to evaluate branch conditions and generate data to intentionally exercise all branches. In doing so, the fuzzer can test hard-to-reach branches that might never be tested by blackbox or greybox fuzzers.
The downside of this type of fuzzing—it is computationally expensive. Large applications with complex branching may require a significant amount of time to solve. This greatly reduces the number of inputs tested. Outside of academic exercises, whitebox fuzzing is often not feasible for real-world applications.
Greybox Fuzzing
Greybox fuzzing has emerged as one of the most popular and effective fuzzing techniques. These fuzzers implement a feedback mechanism, typically via instrumentation, to inform decisions on what data to generate in the future. Inputs which appear to cover more code are reused as the basis for later tests. Inputs which decrease coverage are discarded.
This method is incredibly popular due to its speed and efficiency in reaching obscure code paths. However, not all targets are good candidates for greybox fuzzing. Greybox fuzzing typically works best with smaller, deterministic targets that can process a large number of inputs quickly (several hundred a second).
We often use these types of fuzzers to test individual components within Firefox such as media parsers. If you’re interested in learning how to leverage these fuzzers to test your code, take a look at the Fuzzing Interface documentation here.
Unfortunately, we are somewhat limited in the techniques that we can use when fuzzing WebAPIs. The browser by nature is non-deterministic and the input is highly structured. Additionally, the process of starting the browser, executing tests, and monitoring for faults is slow (several seconds to minutes per test). With these limitations, blackbox fuzzing is the most appropriate solution.
However, since the inputs expected by these APIs are highly structured, we need to ensure that our fuzzer generates data that is considered valid.
Grammar-Based Fuzzing
Grammar-based fuzzing is a fuzzing technique that uses a formal language grammar to define the structure of the data to be generated. These grammars are typically represented in plain-text and use a combination of symbols and constants to represent the data. The fuzzer can then parse the grammar and use it to generate fuzzed output.

The examples here demonstrate two simplified grammar excerpts from the Domato and Dharma fuzzers. These grammars describe the process of creating an HTMLCanvasElement and manipulating its properties and operations.
Issues with Traditional Grammars
Unfortunately, the level of effort required to develop a grammar is directly proportional to the size and complexity of the data you’re attempting to represent. This is the biggest downside of grammar-based fuzzing. For reference, WebAPIs in Firefox expose over 730 interfaces with approximately 6300 members. Keep in mind, this number does not account for other required data structures like callbacks, enums, or dictionaries, to name a few. Creating a grammar to describe these APIs accurately would be a huge undertaking; not to mention error-prone and difficult to maintain.
To more effectively fuzz these APIs, we wanted to avoid as much manual grammar development as possible.
WebIDL as a Fuzzing Grammar
typedef (BufferSource or Blob or USVString) BlobPart;
[Exposed=(Window,Worker)]
interface Blob {
[Throws]
constructor(optional sequence blobParts,
optional BlobPropertyBag options = {});
[GetterThrows]
readonly attribute unsigned long long size;
readonly attribute DOMString type;
[Throws]
Blob slice(optional [Clamp] long long start,
optional [Clamp] long long end,
optional DOMString contentType);
[NewObject, Throws] ReadableStream stream();
[NewObject] Promise text();
[NewObject] Promise arrayBuffer();
};
enum EndingType { "transparent", "native" };
dictionary BlobPropertyBag {
DOMString type = "";
EndingType endings = "transparent";
};A simplified example of the Blob WebIDL definition
WebIDL, is an interface description language (IDL) for describing the APIs implemented by browsers. It lists the interfaces, members, and values exposed by those APIs as well as the syntax.
The WebIDL definitions are well known among the browser fuzzing community because of the wealth of information contained within them. Previous work has been done in this area to extract the data from these IDLs for use as a fuzzing grammar, namely the WADI fuzzer from Sensepost. However, in each example we investigated, we found that the information from these definitions was extracted and re-implemented using the fuzzer’s native grammar syntax. This approach still requires a significant amount of manual effort. And further, the fuzzing grammars’ syntax make it difficult, if not impossible in some instances, to describe behaviors specific to WebAPIs.
Based on these issues, we decided to use the WebIDL definitions directly, rather than converting them to an existing fuzzing grammar syntax. This approach provides us with a number of benefits.
Standardized Grammar
First and foremost, the WebIDL specification defines a standardized grammar to which these definitions must adhere. This lets us leverage existing tools, such as WebIDL2.js, for parsing the raw WebIDL definitions and converting them into an abstract syntax tree (AST). Then this AST can be interpreted by the fuzzer to generate testcases.
Simplified Grammar Development
Second, the WebIDL defines the structure and behavior of the APIs we intend to target. Thus, we significantly reduce the amount of required rule development. In contrast, if we were to describe these APIs using one of the previously mentioned grammars, we would have to create individual rules for each interface, member, and value defined by the API.
ECMAScript Extended Attributes
Unlike traditional grammars, which only define the structure of data, the WebIDL specification provides additional information regarding the interface’s behavior via ECMAScript extended attributes. Extended attributes can describe a variety of behaviors including:
- The contexts where a particular interface can be used.
- Whether the returned object is a new or duplicate instance.
- If the member instance can be replaced.
These types of behaviors are not typically represented by traditional grammars.
Automatic Detection of API Changes
Finally, since the WebIDL files are linked with the interfaces implemented by the browser, we can ensure that updates to the WebIDL reflect updates to the interface.
Transforming IDL to JavaScript

In order to leverage WebIDL for fuzzing, we first need to parse it. Fortunately for us, we can use the WebIDL2.js library to convert the raw IDL files into an abstract-syntax tree (AST). The AST generated by WebIDL2.js describes the data as a series of nodes on a tree. Each of these nodes defines some construct of the WebIDL syntax.
Further information on the WebIDL2 AST structure can be found here.
Once we have our AST, we simply need to define translations for each of these constructs. In Domino, we’ve implemented a series of tools for traversing the AST and translating AST nodes into JavaScript. The diagram above demonstrates a few of these translations.
Most of these nodes can be represented using a static translation. This means that a construct in the AST will always have the same representation in JavaScript. For example, the constructor keyword will always be replaced with the JavaScript “new” operator in combination with the interface name. There are however, several instances where the WebIDL construct can have many meanings and must be generated dynamically.
Generic Types
The WebIDL specification lists a number of types used for representing generic values. For each of these types, Domino implements a function that will either return a randomly generated value matching the requested type or a previously recorded object of the same type. For example, when iterating over the AST, occurrences of the numeric types octet, short, and long will return values within those numeric ranges.
Object References
In places where the construct type references another IDL definition and is used as an argument, these values require an object instance of that IDL type. When one of these values is identified, Domino will attempt to create a new instance of the object (via its constructor). Or, it will attempt to do so by identifying and accessing another member which returns an object of that type.
Callback Handlers
The WebIDL specification also defines a number of types which represent functions (i.e., promises, callbacks, and event listeners). For each of these types, Domino will generate a unique function that performs random operations on the supplied arguments (if present.
Of course the steps above only account for a small fraction of what is necessary to fully translate the IDLs to JavaScript. Domino’s generator implements support for the entire WebIDL specification. Let’s take a look at what our output might look like using the Blob WebIDL as a fuzzing grammar.
Zero Configuration Fuzzing
> const { Domino } = require('~/domino/dist/src/index.js')
> const { Random } = require('~/domino/dist/src/strategies/index.js')
> const domino = new Domino(blob, { strategy: Random, output: '~/test/' })
> domino.generateTestcase()
…
const o = []
o[2] = new ArrayBuffer(8484)
o[1] = new Float64Array(o[2])
o[0] = new Blob([o[1]])
o[0].text().then(function (arg0) {
o[0].text().then(function (arg1) {
o[3] = o[0].slice()
o[3].stream()
o[3].slice(65535, 1, ‘foobar’)
})
})
o[0].arrayBuffer().then(function (arg2) {
o[3].text().then(function (arg3) {
O[4] = arg3
o[0].slice()
})
})As we can see here, the information provided by the IDL is enough to generate valid testcases. These cases exercise a fairly large portion of the Blob-related code. In turn, this allows us to quickly develop baseline fuzzers for new APIs with zero manual intervention.
Unfortunately, not everything is as precise as we would prefer. Take, for instance, the values supplied to the slice operation. After reviewing the Blob specification, we see that the start and end arguments are expected to be byte-order positions relative to the size of the Blob. We’re currently generating these numbers at random. As such, it seems unlikely that we’ll be able to return values within the limits of the Blob length.
Furthermore, both the contentType argument of the slice operation and the type property on the BlobPropertyBag dictionary are defined as DOMString. Similar to our numeric values, we generate strings at random. However, further review of the specification indicates that these values are used to represent the media type of the Blob data. Now, it doesn’t appear that this value has much effect on the Blob object directly. Nevertheless, we can’t be certain that these values won’t have an effect on the APIs which consume these Blobs.
To address these issues, we needed to develop a way of differentiating between these generic types.
Rule Patching with GrIDL
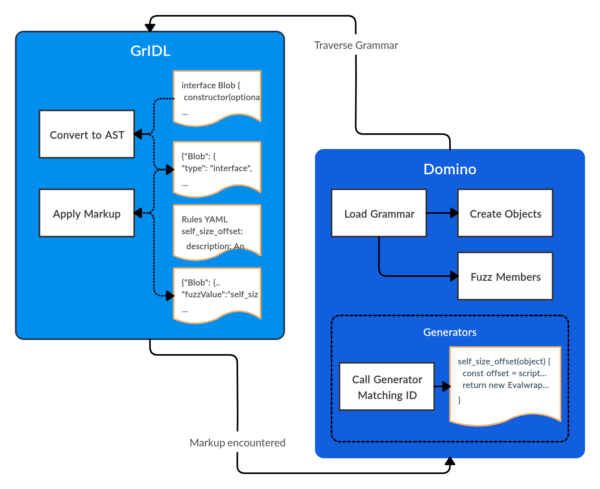
Out of this need, we developed another tool named GrIDL. GrIDL leverages the WebIDL2.js library for converting our IDL definitions into an AST. It also makes several optimizations to the AST to better support its use as a fuzzing grammar.
However, the most interesting feature of GrIDL is this: We can dynamically patch IDL declarations where a more precise value is required. Using a rule-based matching system, GrIDL identifies the target value and inserts a unique identifier. Those identifiers correspond with a matching generator implemented by Domino. While iterating over the AST, if one of these identifiers is encountered, Domino calls the matching generator and emits the value returned.

The diagram above demonstrates the correlation between GrIDL identifiers and Domino generators. Here we’ve defined two generators. One returns byte offsets and the other returns a valid MIME type.
It’s important to note that each generator will also receive access to a live representation of the current object being fuzzed. This provides us with the ability to generate values informed by the current state of the object.
In the example above, we leverage this object to generate byte offsets for the slice function that are relative to its length. However, consider any of the attributes or operations associated with the WebGLRenderingContextBase interface. This interface could be implemented by either a WebGL or WebGL2 context. The arguments required by each may vary drastically. By referencing the current object being fuzzed, we can determine the context type and return values accordingly.
> domino.generateTestcase()
…
const o = []
o[1] = new Uint8Array(14471)
o[0] = new Blob([null, null, o[1]], {
'type': 'image/*',
'endings': 'transparent'
})
o[2] = o[0].slice((1642420336 % o[0].size), (3884321603 % o[0].size), 'application/xhtml+xml')
o[0].arrayBuffer().then(function (arg0) {
setTimeout(function () { o[0].text().then(function (arg1) { o[0].stream() }) }, 180)
o[2].arrayBuffer().then(function (arg2) {
o[0].slice((3412050218 % o[0].size), (646665894 % o[0].size), 'text/plain')
o[0].stream()
})
o[2].text().then(function (arg3) {
o[2].slice((2025414481 % o[2].size), (2615146387 % o[2].size), 'text/html')
o[3] = o[0].slice((753872984 % o[0].size), (883984089 % o[0].size), 'text/xml')
o[3].stream()
})
})
With our newly created rules, we’re now able to generate values that more closely resemble those described by the specification.
Real-World Examples
The examples included in this post have been greatly simplified. It can often be hard to see how an approach like this might be applied to more complex APIs. With that, I’d like to leave you with an example of one of the more complex vulnerabilities uncovered by Domino.
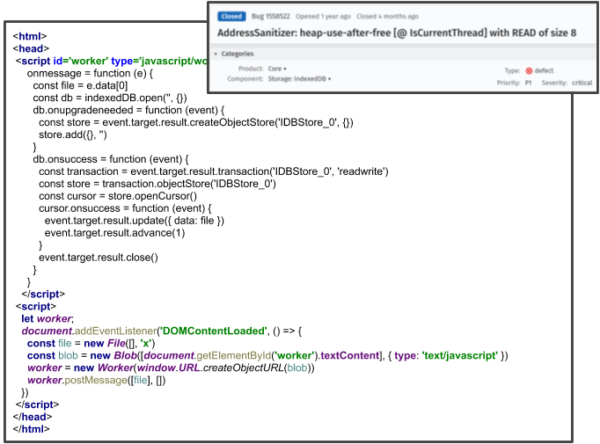
In bug 1558522, we identified a critical use-after-free vulnerability affecting the IndexedDB API. This vulnerability is very interesting from a fuzzing perspective due to the level of complexity required to trigger the issue. Domino was able to trigger this vulnerability by creating a file in the global context, then passing the file object to a worker context where an IndexedDB database connection is established.
This level of coordination between contexts would often be difficult to describe using traditional grammars. However, due to the detailed descriptions of these APIs provided by the WebIDL, Domino can identify vulnerabilities like this with ease.
Contributing
A final note: Domino continues to find security-sensitive vulnerabilities in our code. Unfortunately, this means we cannot release it yet for public use. However, we have plans to release a more generic version in the near future. Stay tuned. If you’d like to get started contributing code to the development of Firefox, there are plenty of open opportunities. And, if you are a Mozilla employee or NDA’d code contributor and you’d like to work on Domino, feel free to reach out to the team in the Fuzzing room on Riot (Matrix)!