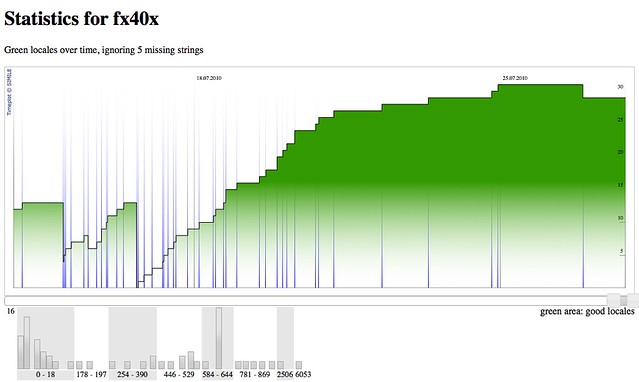
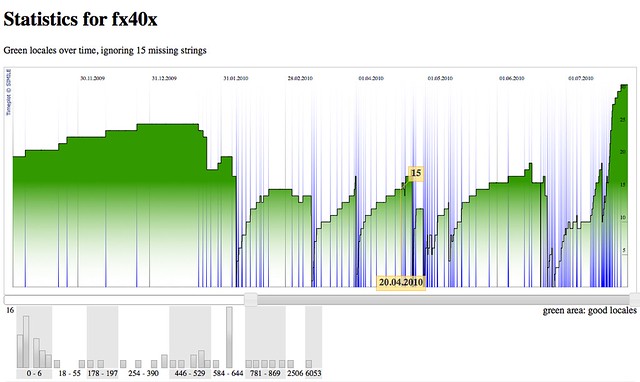
As you all know we’re having a new release scheme. That’s all good and great for localization, but there’s one tiny little peppermint: It exposed each and every design problem in the l10n dashboard, code-named elmo these days.
As many folks wonder why I’m still talking about how the l10n dashboard needs more work, I’ll put some details out there.
The Milestone object is the thing we use to keep track of which version of a localization was shipped in which release-style build. It’s backing up views like Fennec 6 Beta 3 milestone info page, and says “we’re adding pl, and updating nl, ru, zh-TW”. That could be used for QA and verification etc.
The AppVersion object is tracking a particular release. Say, Firefox 3.6 or Firefox 6. It’s containing a series of milestones. The AppVersion objects are tied to an Application object.
The actual compare-locales builds are hooked up to a Tree object, which represents the repositories to compare for a particular application.
The trick is how all these objects are tied together. Gandalf and I designed this back in the days of the Firefox 3.6 release. Back in those days, we had loooong release cycles, with lengthy cycles even for individual milestones, and string freezes for each milestone. At that point, we’d open up sign-offs. Remember, back in the days we wouldn’t have l10n-merge on for release builds, so we could only start reviewing the localizations after string freeze. Also, we did the hg branches for a release early in the cycle, and then we would ship most of our betas from that branch, while development on central progressed merrily.
Thus, our design decisions back then were:
There’s one static repository setup for a version of an application. Umpf. Can you see how bad that is today, where we switch our repo setup every six weeks?
Whether a localizer can sign-off or not depends on whether the upcoming milestone is string frozen or not. In other words, we need to have the upcoming milestone early to begin with, which is such a hassle now that we’re doing them weekly, instead of bi-monthly. Also, with l10n-merge and string-frozen branches, all that logic just … face palm.
Localizers sign off on a version of the application, with a push to its l10n repository. Pushes are per repo, appversions are spanning repos today. I.e., I push on aurora, sign off, it’s good, the appversion migrates to beta, but the push is still on aurora.
Review actions on sign-offs are forever. Say, I r+ a sign-off on aurora, that goes to beta, but there’s a lack of traction that makes that revision really bad to ship for the next cycle. I can’t make that sign-off bad for Firefox 12 and good for Firefox 11.
Lessons learned:
- appversions hop from tree to tree, over time
- sign-offs are per tree, this localization at this point is good, source-wise
- actions on sign-offs can be per appversion
- milestones aren’t required before we actually ship something
Or, as we say in German, we have to put the design “vom Kopf auf die Füße”.