As a follow up to my previous post on my digging through our build status, I want to look with a bit more detail, pretend it’d all be simple and what it could be, and, well, add the promised chocolate to coconut. Bounty.
Let’s look at the actual data for two and half landings. First, I’ll start with a rather simple landing by roc, revision 1b43… on mozilla-central. Let me summarize the builds real quick:
1 changeset in 1 push.
27 change rows in status db.
16 different branch names.
106 sourcestamps in status db.
245 builds.
That’s a lot, because, what we’re really interested in is
1 push, 245 builds.
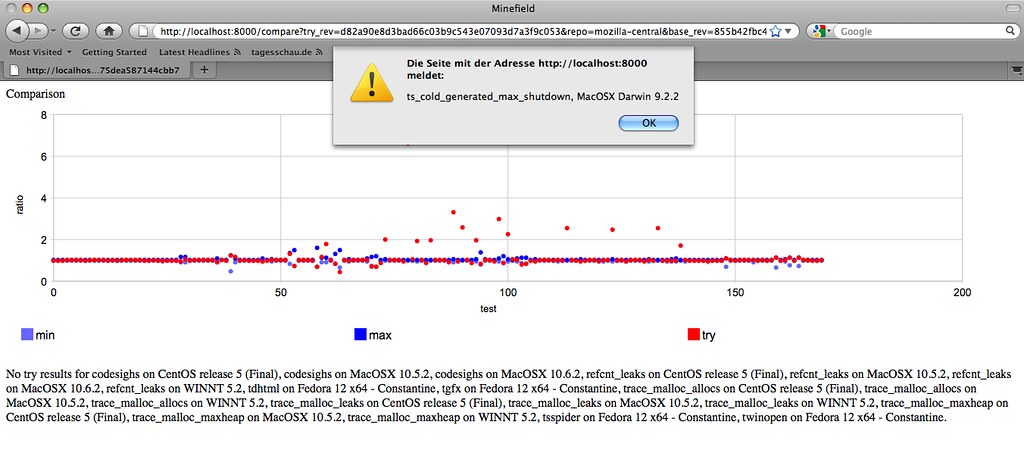
Talk is cheap, but what’s really cheap is manipulating other peoples database, so while Vettel was running in circles in Brazil, I was running circles in the db and manually stitched things back together. The result is still coconut, but with chocolate, so here is the same url in bounty.
1 source, 1 change, 253 builds.
Wait, what, not 245? No, 253, because, well, there are more disconnects in the status, so the query in the database doesn’t catch them all. That’s what you need manual stitching for. Also, finding the right sourcestamp to keep isn’t trivial.
Which is why I only did it for a few builds. Sorry, you’ll not find a lot of builds that are stitched together, so enjoy the guided tour through the few shiny places.
During my needlework I came across another set of changes which are worthwhile to include into today’s tour. It’s two pushes, by khuey and vlad. Let’s give Count Count a rest and look at them with chocolate right away, the builds for khuey’s revision and vlad’s. What you’ll notice is that some of the builds for khuey aren’t there, but lumped together with vlad’s. Why’s that?
Our build infrastructure really doesn’t know about pushes. As I’ve detailed in my previous post, there are sourcestamps and changes, but no further grouping. At this point it’s really a design decision on whether the buildbot changes are hg pushes or hg changesets. This decision is currently in favor of hg changesets, which may just be right. At that point, the scheduling logic that puts changes into builds needs to put extra care into creating sourcestamps for what we intend to get builds for, and to keep those sourcestamps apart. The current implementation puts anything coming in within three minutes into the same sourcestamp, which is somewhat of a load limiter.
Anyway, back to chocolate. When you looked at the pages, did you realize that once you add it, you’re almost at a tinderboxpushlog page? Right, it could be that “easy”.
What’s between reality and chocolate? Well, sendchange. That’s a buildbot architecture component that allows shell commands to insert changes into buildmaster. It’s rather limited in the data it can transport, which is why we loose data on the way. There’s an alternative feature called trigger, which doesn’t. There is an open ticket to make that span different buildmasters, but given how much Mozilla invested into schedulerdb, let’s pray it’s easy to fix. Filed bug 611670.
Update: Changed links to l10n community server.