Mozilla research shows some machine voices score higher than humans
This blog post is to accompany the publication of the paper Choice of Voices: A Large-Scale Evaluation of Text-to-Speech Voice Quality for Long-Form Content in the Proceedings of CHI’20, by Julia Cambre and Jessica Colnago from CMU, Jim Maddock from Northwestern, and Janice Tsai and Jofish Kaye from Mozilla.
In 2019, Mozilla’s Voice team developed a method to evaluate the quality of text-to-speech voices. It turns out there was very little that had been done in the world of text to speech to evaluate voice for listening to long-form content — things like articles, book chapters, or blog posts. A lot of the existing work answered the core question of “can you understand this voice?” So a typical test might use a syntactically correct but meaningless sentence, like “The masterly serials withdrew the collaborative brochure”, and have a listener type that in. That way, the listener couldn’t guess missed words from other words in the sentence. But now that we’ve reached a stage of computerized voice quality where so many voices can pass the comprehension test with flying colours, what’s the next step?
How can we determine if a voice is enjoyable to listen to, particularly for long-form content — something you’d listen to for more than a minute or two? Our team had a lot of experience with this: we had worked closely with our colleagues at Pocket to develop the Pocket Listen feature, so you can listen to articles you’ve saved, while driving or cooking. But we still didn’t know how to definitively say that one voice led to a better listening experience than another.
The method we used was developed by our intern Jessica Colnago during her internship at Mozilla, and it’s pretty simple in concept. We took one article, How to Reduce Your Stress in Two Minutes a Day, and we recorded each voice reading that article. Then we had 50 people on Mechanical Turk listen to each recording — 50 different people each time. (You can also listen to clips from most of these recordings to make your own judgement.). Nobody heard the article more than once. And at the end of the article, we’d ask them a couple of questions to check they were actually listening, and to see what they thought about the voice.
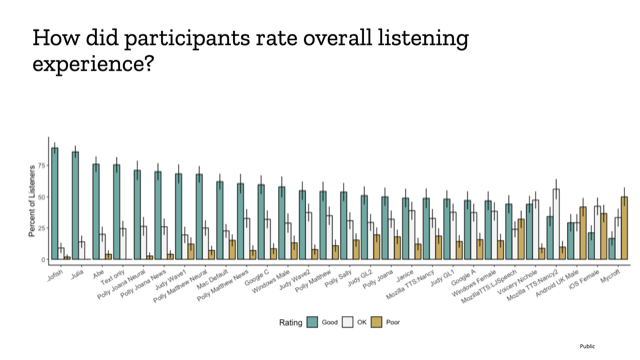
For example, we’d ask them to rate how much they liked the voice on a scale of one to five, and how willing they’d be to listen to more content recorded by that voice. We asked them why they thought that voice might be pleasant or unpleasant to listen to. We evaluated 27 voices, and here’s one graph which represents the results. (The paper has lots more rigorous analysis, and we explored various methods to sort the ratings, but the end results are all pretty similar. We also added a few more voices after the paper was finished, which is why there’s different numbers of voices in different places in this research.)
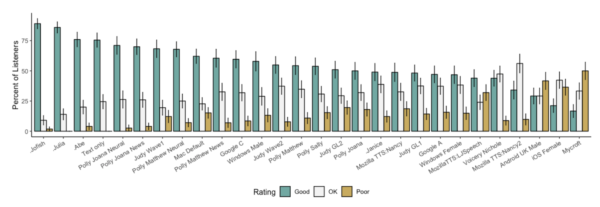 As you can see, some voices rated better than others. The ones at the left are the ones people consistently rated positively, and the ones at the right are the ones that people liked less: just as examples, you’ll notice that the default (American) iOS female voice is pretty far to the right, although the Mac default voice has a pretty respectable showing. I was proud to find that the Mozilla Judy Wave1 voice, created by Mozilla research engineer Eren Gölge, is rated up there along with some of the best ones in the field. It turns out the best electronic voices we tested are Mozilla’s voices and the Polly Neural voices from Amazon. And while we still have some licensing questions to figure out, making sure we can create sustainable, publicly accessible, high quality voices, it’s exciting to see that we can do something in an open source way that is competitive with very well funded voice efforts out there, which don’t have the same aim of being private, secure and accessible to all.
As you can see, some voices rated better than others. The ones at the left are the ones people consistently rated positively, and the ones at the right are the ones that people liked less: just as examples, you’ll notice that the default (American) iOS female voice is pretty far to the right, although the Mac default voice has a pretty respectable showing. I was proud to find that the Mozilla Judy Wave1 voice, created by Mozilla research engineer Eren Gölge, is rated up there along with some of the best ones in the field. It turns out the best electronic voices we tested are Mozilla’s voices and the Polly Neural voices from Amazon. And while we still have some licensing questions to figure out, making sure we can create sustainable, publicly accessible, high quality voices, it’s exciting to see that we can do something in an open source way that is competitive with very well funded voice efforts out there, which don’t have the same aim of being private, secure and accessible to all.
We found there were some generalizable experiences. Listeners were 54% more likely to give a higher experience rating to the male voices we tested than the female voices. We also looked at the number of words spoken in a minute. Generally, our results indicated that there is a “just right speed” in the range of 163 to 177 words per minute, and people didn’t like listening to voices that were much faster or slower than that.
But the more interesting result comes from one of the things we did at a pretty late stage in the process, which was to include some humans reading the article directly into a microphone. Those are the voices circled in red:
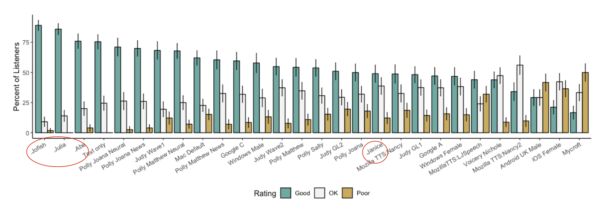
What we found was that some of our human voices were being rated lower than some of the robot voices. And that’s fascinating. That suggests we are at a point in technology, in society right now, where there are mechanically generated voices that actually sound better than humans. And before you ask, I listened to those recordings of human voices. You can do the same. Janice (the recording labelled Human 2 in the dataset) has a perfectly normal voice that I find pleasant to listen to. And yet some people were finding these mechanically generated voices better.
That raises a whole host of interesting questions, concerns and opportunities. This is a snapshot of computerized voices, in the last two years or so. Even since we’ve done this study, we’ve seen the quality of voices improve. What happens when computers are more pleasant to listen to than our own voices? What happens when our children might prefer to listen to our computer reading a story than ourselves?
A potentially bigger ethical question comes with the question of persuasion. One question we didn’t ask in this study was whether people trusted or believed the content that was read to them. What happens when we can increase the number of people who believe something simply by changing the voice that it is read in? There are entire careers exploring the boundaries of influence and persuasion; how does easy access to “trustable” voices change our understanding of what signals point to trustworthiness? The BBC has been exploring British attitudes to regional accents in a similar way — drawing, fascinatingly, from a study of how British people reacted to different voices on the radio in 1927. We are clearly continuing a long tradition of analyzing the impact of voice and voices on how we understand and feel about information.


