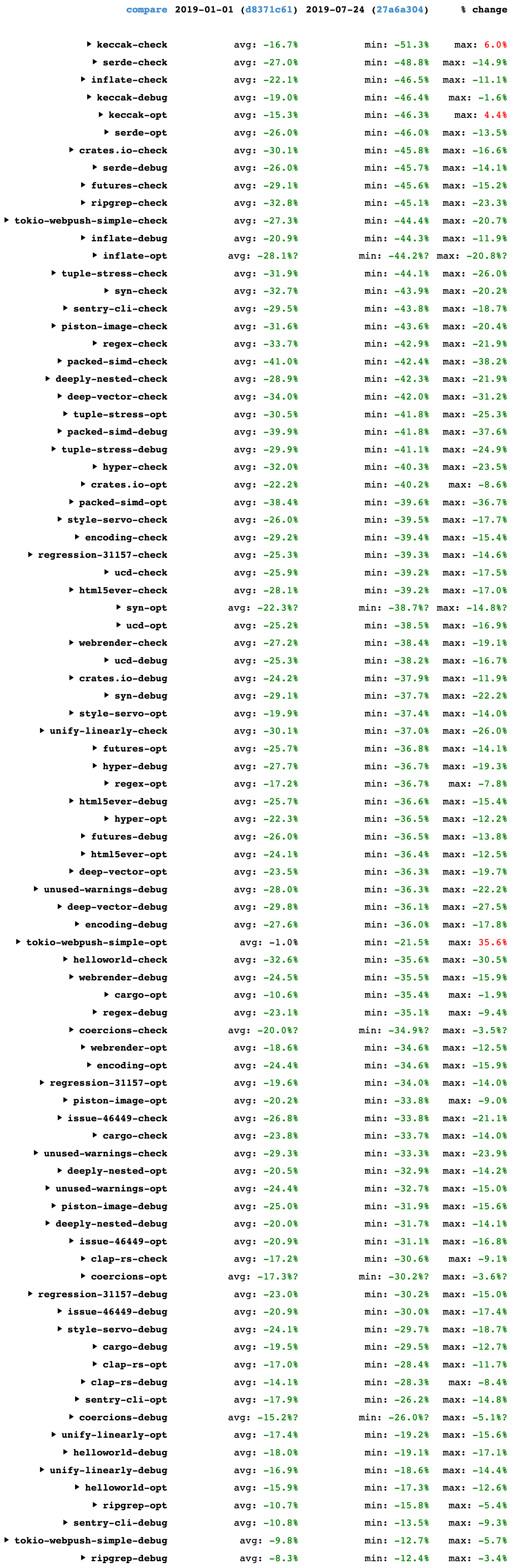
Incremental compilation
I started the year by profiling incremental compilation and making several improvements there.
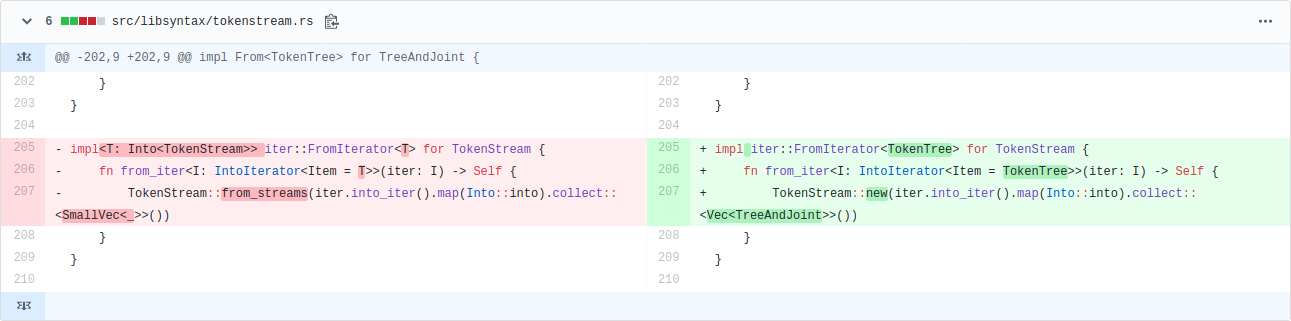
#68914: Incremental compilation pushes a great deal of data through a hash function, called SipHasher128, to determine what code has changed since the last compiler invocation. This PR greatly improved the extraction of bytes from the input byte stream (with a lot of back and forth to ensure it worked on both big-endian and little-endian platforms), giving incremental compilation speed-ups of up to 13% across many benchmarks. It also added a lot more comments to explain what is going on in that code, and removed multiple uses of unsafe.
#69332: This PR reverted the part of #68914 that changed the u8to64_le function in a way that made it simpler but slower. This didn’t have much impact on performance because it’s not a hot function, but I’m glad I caught it in case it gets used more in the future. I also added some explanatory comments so nobody else will make the same mistake I did!
#69050: LEB128 encoding is used extensively within Rust crate metadata. Michael Woerister had previously sped up encoding and decoding in #46919, but there was some fat left. This PR carefully minimized the number of operations in the encoding and decoding loops, almost doubling their speed, and giving wins on many benchmarks of up to 5%. It also removed one use of unsafe. In the PR I wrote a detailed description of the approach I took, covering how I found the potential improvement via profiling, the 18 different things I tried (10 of which improved speed), and the final performance results.
LLVM bitcode
Last year I noticed from profiles that rustc spends some time compressing the LLVM bitcode it produces, especially for debug builds. I tried changing it to not compress the bitcode, and that gave some small speed-ups, but also increased the size of compiled artifacts on disk significantly.
Then Alex Crichton told me something important: the compiler always produces both object code and bitcode for crates. The object code is used when compiling normally, and the bitcode is used when compiling with link-time optimization (LTO), which is rare. A user is only ever doing one or the other, so producing both kinds of code is typically a waste of time and disk space.
In #66598 I tried a simple fix for this: add a new flag to rustc that tells it to omit the LLVM bitcode. Cargo could then use this flag whenever LTO wasn’t being used. After some discussion we decided it was too simplistic, and filed issue #66961 for a more extensive change. That involved getting rid of the use of compressed bitcode by instead storing uncompressed bitcode in a section in the object code (a standard format used by clang), and introducing the flag for Cargo to use to disable the production of bitcode.
The part of rustc that deals with all this was messy. The compiler can produce many different kinds of output: assembly code, object code, LLVM IR, and LLVM bitcode in a couple of possible formats. Some of these outputs are dependent on other outputs, and the choices on what to produce depend on various command line options, as well as details of the particular target platform. The internal state used to track output production relied on many boolean values, and various nonsensical combinations of these boolean values were possible.
When faced with messy code that I need to understand, my standard approach is to start refactoring. I wrote #70289, #70345, and #70384 to clean up code generation, #70297, #70729 , and #71374 to clean up command-line option handling, and #70644 to clean up module configuration. Those changes gave me some familiarity with the code, simplifed it, and I was then able to write #70458 which did the main change.
Meanwhile, Alex Crichton wrote the Cargo support for the new -Cembed-bitcode=no option (and also answered a lot of my questions). Then I fixed rustc-perf so it would use the correct revisions of rustc and Cargo together, without which the the change would erroneously look like a performance regression on CI. Then we went through a full compiler-team approval and final comment period for the new command-line option, and it was ready to land.
Unfortunately, while running the pre-landing tests we discovered that some linkers can’t handle having bitcode in the special section. This problem was only discovered at the last minute because only then are all tests run on all platforms. Oh dear, time for plan B. I ended up writing #71323 which went back to the original, simple approach, with a flag called -Cbitcode-in-rlib=no. [EDIT: note that libstd is still compiled with -Cbitcode-in-rlib=yes, which means that libstd rlibs will still work with both LTO and non-LTO builds.]
The end result was one of the bigger performance improvements I have worked on. For debug builds we saw wins on a wide range of benchmarks of up to 18%, and for opt builds we saw wins of up to 4%. The size of rlibs on disk has also shrunk by roughly 15-20%. Thanks to Alex for all the help he gave me on this!
Anybody who invokes rustc directly instead of using Cargo might want to use -Cbitcode-in-rlib=no to get the improvements.
[EDIT (May 7, 2020): Alex subsequently got the bitcode-in-object-code-section approach working in #71528 by adding the appropriate “ignore this section, linker” incantations to the generated code. He then changed the option name back to the original -Cembed-bitcode=no in #71716. Thanks again, Alex!]
Miscellaneous improvements
#67079: Last year in #64545 I introduced a variant of the shallow_resolved function that was specialized for a hot calling pattern. This PR specialized that function some more, winning up to 2% on a couple of benchmarks.
#67340: This PR shrunk the size of the Nonterminal type from 240 bytes to 40 bytes, reducing the number of memcpy calls (because memcpy is used to copy values larger than 128 bytes), giving wins on a few benchmarks of up to 2%.
#68694: InferCtxt is a type that contained seven different data structures within RefCells. Several hot operations would borrow most or all of the RefCells, one after the other. This PR grouped the seven data structures together under a single RefCell in order to reduce the number of borrows performed, for wins of up to 5%.
#68790: This PR made a couple of small improvements to the merge_from_succ function, giving 1% wins on a couple of benchmarks.
#68848: The compiler’s macro parsing code had a loop that instantiated a large, complex value (of type Parser) on each iteration, but most of those iterations did not modify the value. This PR changed the code so it initializes a single Parser value outside the loop and then uses Cow to avoid cloning it except for the modifying iterations, speeding up the html5ever benchmark by up to 15%. (An aside: I have used Cow several times, and while the concept is straightforward I find the details hard to remember. I have to re-read the documentation each time. Getting the code to work is always fiddly, and I’m never confident I will get it to compile successfully… but once I do it works flawlessly.)
#69256: This PR marked with #[inline] some small hot functions relating to metadata reading and writing, for 1-5% improvements across a number of benchmarks.
#70837: There is a function called find_library_crate that does exactly what its name suggests. It did a lot of repetitive prefix and suffix matching on file names stored as PathBufs. The matching was slow, involving lots of re-parsing of paths within PathBuf methods, because PathBuf isn’t really designed for this kind of thing. This PR pre-emptively extracted the names of the relevant files as strings and stored them alongside the PathBufs, and changed the matching to use those strings instead, giving wins on various benchmarks of up to 3%.
#70876: Cache::predecessors is an oft-called function that produces a vector of vectors, and the inner vectors are usually small. This PR changed the inner vector to a SmallVec for some very small wins of up to 0.5% on various benchmarks.
Other stuff
I added support to rustc-perf for the compiler’s self-profiler. This gives us one more profiling tool to use on the benchmark suite on local machines.
I found that using LLD as the linker when building rustc itself reduced the time taken for linking from about 93 seconds to about 41 seconds. (On my Linux machine I do this by preceding the build command with RUSTFLAGS="-C link-arg=-fuse-ld=lld".) LLD is a really fast linker! #39915 is the three-year old issue open for making LLD the default linker for rustc, but unfortunately it has stalled. Alexis Beingessner wrote a nice summary of the current situation. If anyone with knowledge of linkers wants to work on that issue, it could be a huge win for many Rust users.
Failures
Not everything I tried worked. Here are some notable failures.
#69152: As mentioned above, #68914 greatly improved SipHasher128, the hash function used by incremental compilation. That hash function is a 128-bit version of the default 64-bit hash function used by Rust hash tables. I tried porting those same improvements to the default hasher. The goal was not to improve rustc’s speed, because it uses FxHasher instead of default hashing, but to improve the speed of all Rust programs that do use default hashing. Unfortunately, this caused some compile-time regressions for complex reasons discussed in detail in the PR, and so I abandoned it. I did manage to remove some dead code in the default hasher in #69471, though.
#69153: While working on #69152, I tried switching from FxHasher back to the improved default hasher (i.e. the one that ended up not landing) for all hash tables within rustc. The results were terrible; every single benchmark regressed! The smallest regression was 4%, the largest was 85%. This demonstrates (a) how heavily rustc uses hash tables, and (b) how much faster FxHasher is than the default hasher when working with small keys.
I tried using ahash for all hash tables within rustc. It is advertised as being as fast as FxHasher but higher quality. I found it made rustc a tiny bit slower. Also, ahash is also not deterministic across different builds, because it uses const_random! when initializing hasher state. This could cause extra noise in perf runs, which would be bad. (Edit: It would also prevent reproducible builds, which would also be bad.)
I tried changing the SipHasher128 function used for incremental compilation from the Sip24 algorithm to the faster but lower-quality Sip13 algorithm. I got wins of up to 3%, but wasn’t confident about the safety of the change and so didn’t pursue it further.
#69157: Some follow-up measurements after #69050 suggested that its changes to LEB128 decoding were not as clear a win as they first appeared. (The improvements to encoding were still definitive.) The performance of decoding appears to be sensitive to non-local changes, perhaps due to differences in how the decoding functions are inlined throughout the compiler. This PR reverted some of the changes from #69050 because my initial follow-up measurements suggested they might have been pessimizations. But then several sets of additional follow-up measurements taken after rebasing multiple times suggested that the reversions sometimes regressed performance. The reversions also made the code uglier, so I abandoned this PR.
#66405: Each obligation held by ObligationForest can be in one of several states, and transitions between those states occur at various points. This PR reduced the number of states from five to three, and greatly reduced the number of state transitions, which won up to 4% on a few benchmarks. However, it ended up causing some drastic regressions for some users, so in #67471 I reverted those changes.
#60608: This issue suggests using FxIndexSet in some places where currently an FxHashMap plus a Vec are used. I tried it for the symbol table and it was a significant regression for a few benchmarks.
Progress
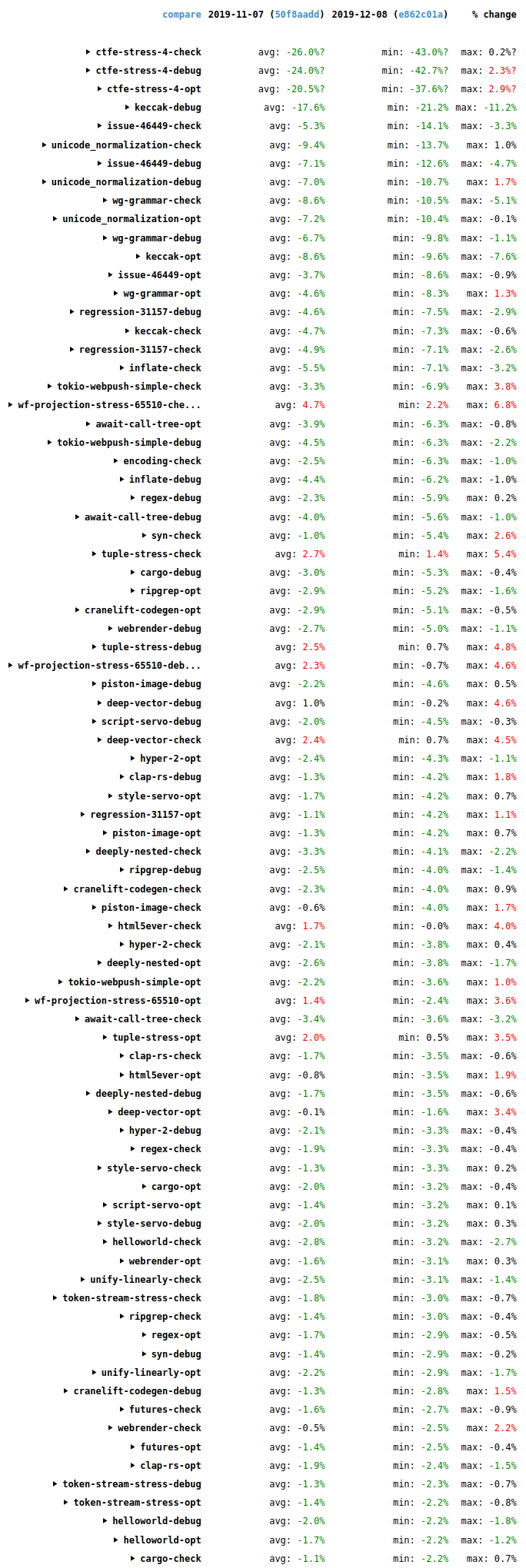
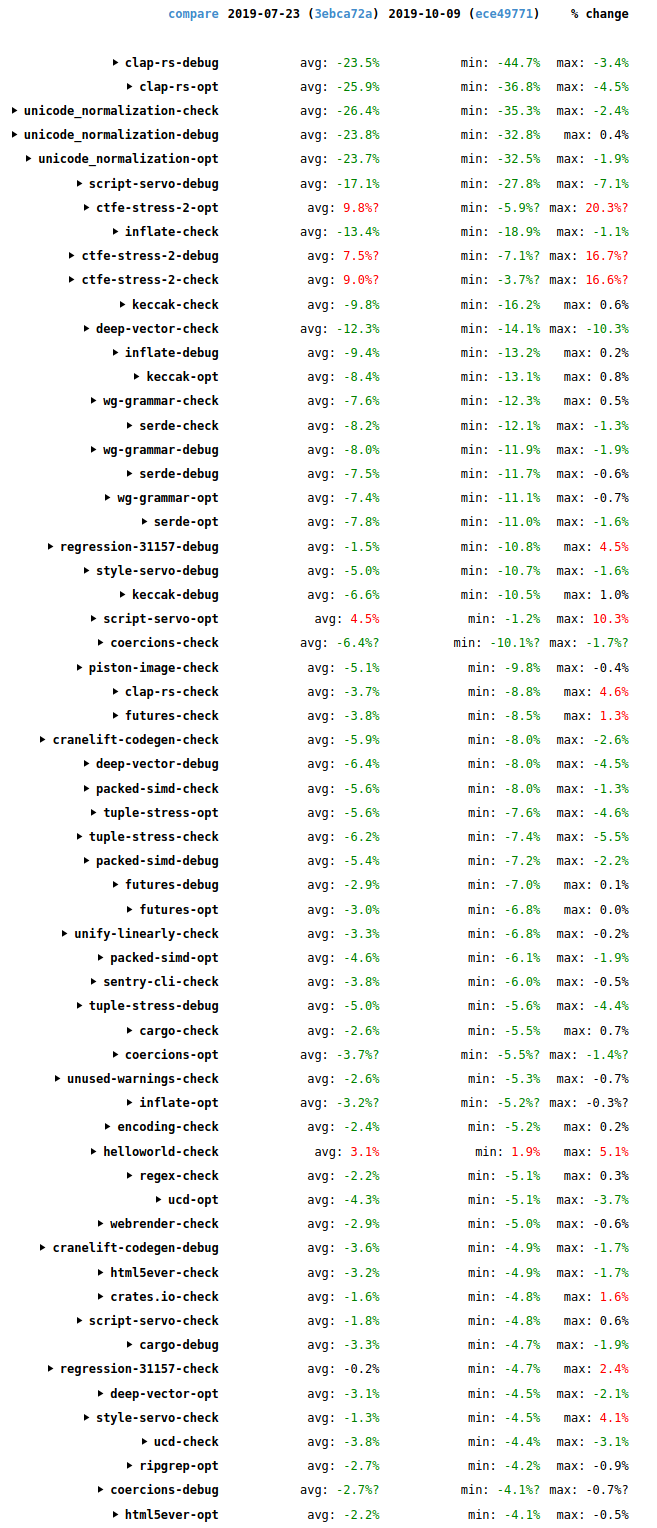
Since my last blog post, compile times have seen some more good improvements. The following screenshot shows wall-time changes on the benchmark suite since then (2019-12-08 to 2020-04-22).
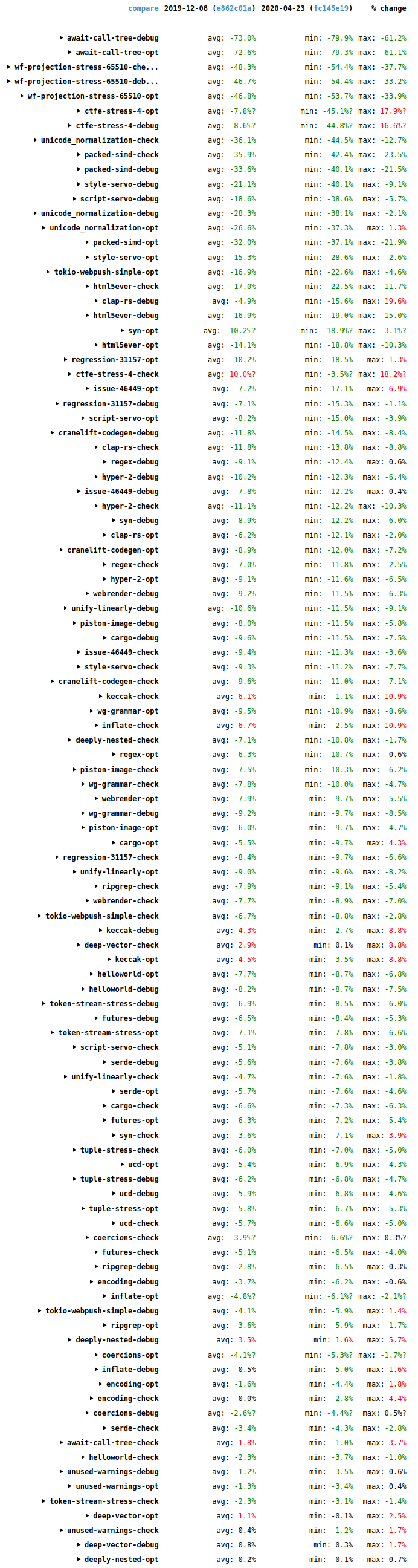
The biggest changes are in the synthetic stress tests await-call-tree-debug, wf-projection-stress-65510, and ctfe-stress-4, which aren’t representative of typical code and aren’t that important.
Overall it’s good news, with many improvements (green), some in the double digits, and relatively few regressions (red). Many thanks to everybody who helped with all the performance improvements that landed during this period.
]]>