Process separation remains one of the most important parts of the Firefox security model and securing our IPC (Inter-Process Communication) interfaces is crucial to keep privileges in the different processes separated. Today, we will take a more detailed look at our newest tool for finding vulnerabilities in these interfaces – snapshot fuzzing.
Snapshot Fuzzing
One of the challenges when fuzzing the IPC Layer is that isolating the interfaces that are to be tested isn’t easily doable. Instead, one needs to run an entire Firefox instance to effectively fuzz these interfaces. However, having to run a Firefox instance for fuzzing comes with another set of downsides: First, we cannot easily reset the system back into a known-good state other than restarting the entire browser. This causes issues with reproducibility and breaks determinism required by coverage-guided fuzzing. And second, many errors in the parent process are still handled by crashing, again forcing a full and time consuming restart of the browser. Both cases are essentially a performance problem – restarting the browser is simply too slow to allow for efficient and productive fuzzing. This is where snapshot fuzzing comes into play – it allows us to take a snapshot at the point where we are “ready” to perform fuzzing and reset to that snapshot point after each fuzzing iteration at practically no cost. This snapshot technique even works when we find a bug in the parent process which would normally force us to restart the browser.
Technical Implementation
As Firefox consists of multiple processes that need to be kept in sync, we decided to use Nyx, a full-vm snapshot fuzzing tool. In this setup, Firefox runs in a guest operating system (usually Linux) and the snapshot taken is a snapshot of the whole guest including all of its processes. Nyx is also compatible with AFL++ as a frontend, a tool we already employ for other fuzzing targets.
To facilitate communication between Firefox and Nyx, we use a custom agent, essentially glue-code that is preloaded into Firefox. This code handles the low-level communication with Nyx and is also responsible for providing the trace buffer (for coverage measurements) to the AFL++ runtime linked to Firefox as well as passing through fuzzing data from AFL++. Both of these tasks are more complex in this configuration as AFL++ is not directly launching and communicating with the target binary. The agent further exposes a clean interface to Firefox that can be used to implement the actual fuzzer in Firefox itself without having to worry about the low-level details.
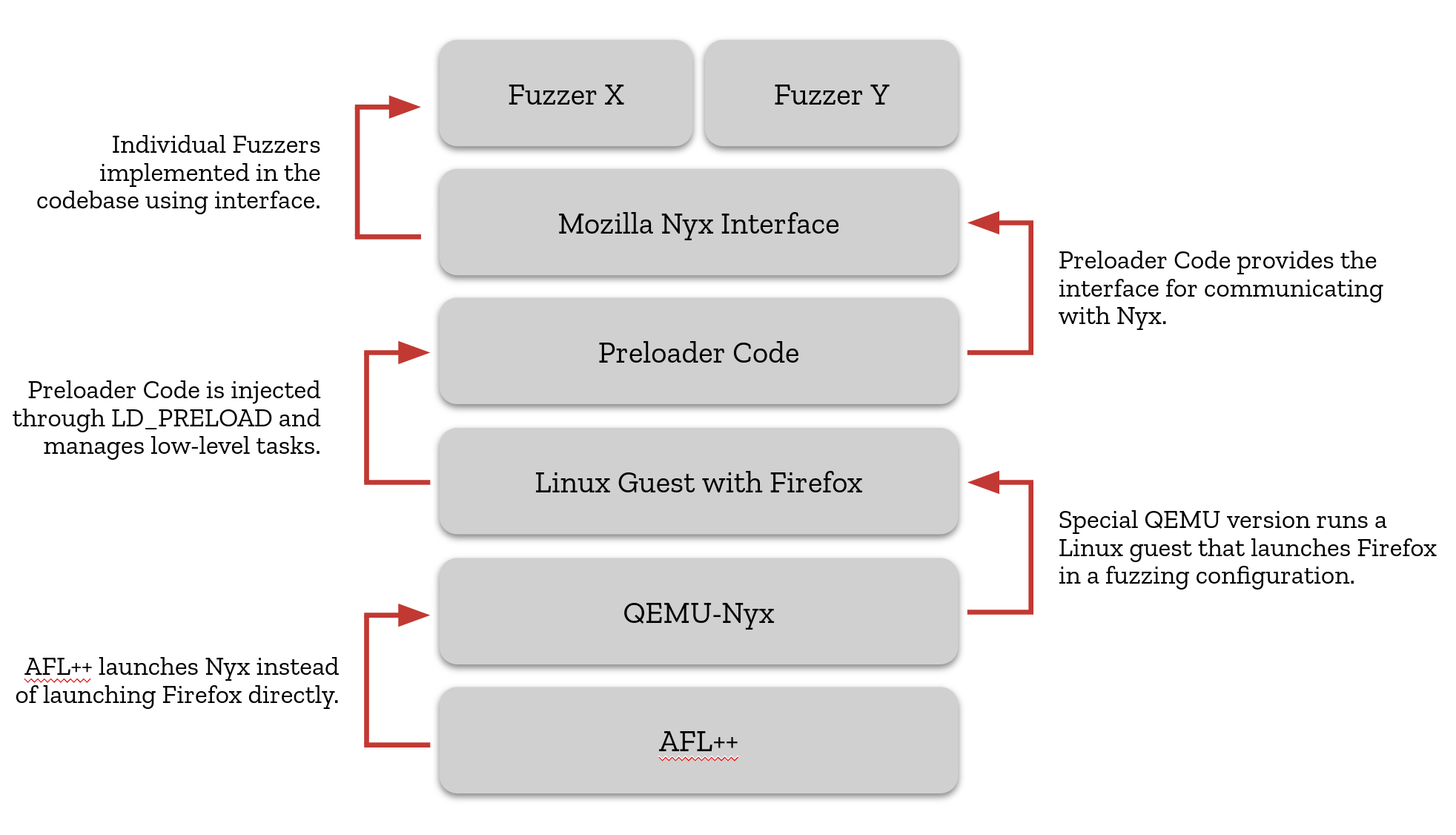
Technology stack for snapshot fuzzing at a glance.
On top of this interface, we have implemented multiple IPC fuzzing targets, the simplest one being IPC_SingleMessage, which we will look at in more detail now.
Fuzzing a single IPC message
Modifying a single IPC message in transit is one of the rudimentary approaches for IPC fuzzing in general. It is especially useful if the message type being targeted is in itself complex (lots of data contained in a single message rather than a complex interface being composed of a large number of simpler messages).
For this purpose, we intercept messages in the parent process on the target thread before they are dispatched to the generated IPC code that ultimately calls the IPC method. Most of the logic is then contained in IPCFuzzController::replaceIPCMessage which primarily does either of these two things:
- If the message type does not match our configured target message, we can optionally dump it to a file (this is useful to create seeds for different types of single message fuzzing), but otherwise we pass the message through.
- If the message matches our target specification, take the snapshot, replace the payload of the original message with our fuzzing data and return the new (fuzzed) message to be dispatched.
Once the fuzzed message is dispatched (most commonly to a different thread), we face an important challenge of multi-threaded snapshot fuzzing: synchronization. Coverage-guided fuzzing generally operates under the assumption that we know when our fuzzing data has been processed. Depending on the fuzzing target, it can be fairly difficult to tell when we are “done” but in our case, because we are already on the target thread that is running the actual IPC method. So unless that method again performs an asynchronous dispatch, we can just wait for the dispatch to return and we do so at the end of DispatchMessage() where we call back into IPCFuzzController to release (revert back to the snapshot).
By combining this target with a CI test¹, we are now able to find implementation flaws like for example a vulnerability in the accessibility code that involved the ShowEvent message. This message contains an array of serialized AccessibleData, making this message type a good target for single message fuzzing.
Measuring Code Coverage in Snapshot Fuzzing
Code coverage is probably the most important metric for long-term fuzzing campaigns as it highlights potential shortcomings of the fuzzing. While for most fuzzing, it is rather straightforward to generate code coverage, doing so in snapshot fuzzing is less trivial. Traditional source code coverage provided by tools like gcov which find usage with other fuzzing, aren’t easily deployable because the data would have to be pulled out of the VM on every iteration so it can be saved before the snapshot revert resets the data. Doing so would make the process of obtaining code coverage unfeasibly slow.
Instead, we decided to build our own code coverage measurement on top of the existing instrumentation. For this purpose, we added a new AFL++ instrumentation type that instruments all basic blocks and then creates a second, permanent trace buffer in AFL++ that accumulates the coverage of the regular trace buffer. Finally, we create a third buffer called the pcmap which maps every entry in the trace buffer to an address in the binary that can later be resolved to a source code location using debug information. As this information is contained in the AFL++ runtime, we need to obtain it within our custom Nyx agent and write it out to the host. The same holds for module information that denotes at which addresses Firefox modules were loaded. By combining these three sources of information, we can map the progress of Nyx fuzzing onto actual source code. We also built additional tooling to turn this basic block coverage into line-based coverage using information from a gcov build². As a result, we can generate metrics like percentage of code covered to evaluate the overall effectiveness of snapshot-based fuzzing.
Conclusion
While snapshot fuzzing is a rather complex technology with many moving parts, it allows us to effectively stress code regions of the browser that would otherwise remain beyond the capabilities of traditional fuzzing techniques, but are critical for providing adequate security guarantees. We are happy to report that this new fuzzing technology is becoming the norm and is now an essential part of our security testing strategy. We would like to thank the authors of Nyx and AFL++ for making this technology available and hope that our combined efforts will help others to adapt snapshot fuzzing for their projects.
¹ Firefox runs many Continuous Integration tests to ensure every functionality of the browser is automatically tested.
² Unfortunately, gcov and debug information deviate in some cases, so the result is not a 100% accurate mapping yet and can’t be seamlessly merged with other gcov data. This could likely be improved using LLVM annotations for additional basic block information.