Sharing our Common Voices – Mozilla releases the largest to-date public domain transcribed voice dataset
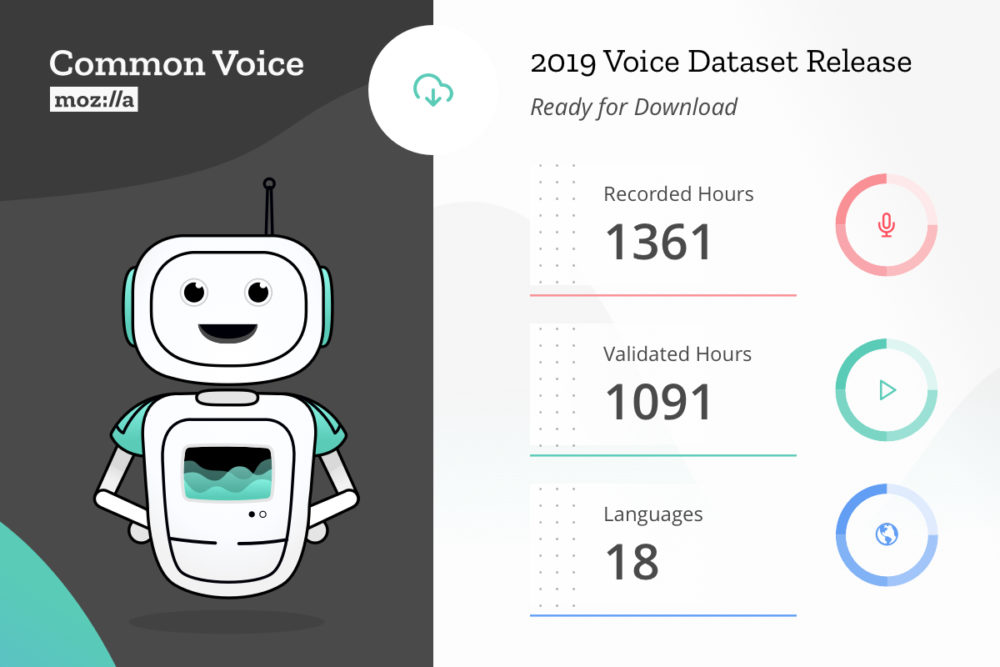
Mozilla crowdsources the largest dataset of human voices available for use, including 18 different languages, adding up to almost 1,400 hours of recorded voice data from more than 42,000 contributors.
From the onset, our vision for Common Voice has been to build the world’s most diverse voice dataset, optimized for building voice technologies. We also made a promise of openness: we would make the high quality, transcribed voice data that was collected publicly available to startups, researchers, and anyone interested in voice-enabled technologies.
Today, we’re excited to share our first multi-language dataset with 18 languages represented, including English, French, German and Mandarin Chinese (Traditional), but also for example Welsh and Kabyle. Altogether, the new dataset includes approximately 1,400 hours of voice clips from more than 42,000 people.
With this release, the continuously growing Common Voice dataset is now the largest ever of its kind, with tens of thousands of people contributing their voices and original written sentences to the public domain (CC0). Moving forward, the full dataset will be available for download on the Common Voice site.

Data Qualities
The Common Voice dataset is unique not only in its size and licence model but also in its diversity, representing a global community of voice contributors. Contributors can opt-in to provide metadata like their age, sex, and accent so that their voice clips are tagged with information useful in training speech engines.
This is a different approach than for other publicly available datasets, which are either hand-crafted to be diverse (i.e. equal number of men and women) or the corpus is as diverse as the “found” data (e.g. the TEDLIUM corpus from TED talks is ~3x men to women).
More Common Voices: from 3 to 22 languages in 8 months
Since we enabled multi-language support in June 2018, Common Voice has grown to be more global and more inclusive. This has surpassed our expectations: Over the last eight months, communities have enthusiastically rallied around the project, launching data collection efforts in 22 languages with an incredible 70 more in progress on the Common Voice site.
As a community-driven project, people around the world who care about having a voice dataset in their language have been responsible for each new launch — some are passionate volunteers, some are doing this as part of their day jobs as linguists or technologists. Each of these efforts require translating the website to allow contributions and adding sentences to be read.
Our latest additions include Dutch, Hakha-Chin, Esperanto, Farsi, Basque, and Spanish. In some cases, a new language launch on Common Voice is the beginning of that language’s internet presence. These community efforts are proof that all languages—not just ones that can generate high revenue for technology companies—are worthy of representation.
We’ll continue working with these communities to ensure their voices are represented and even help make voice technology for themselves. In this spirit, we recently joined forces with the Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) and co-hosted an ideation hackathon in Kigali to create a speech corpus for Kinyarwanda, laying the foundation for local technologists in Rwanda to develop open source voice technologies in their own language.
Improvements in the contribution experience, including optional profiles
The Common Voice Website is one of our main vehicles for building voice data sets that are useful for voice-interaction technology. The way it looks today is the result of an ongoing process of iteration. We listened to community feedback about the pain points of contributing while also conducting usability research to make contribution easier, more engaging, and fun.
People who contribute not only see progress per language in recording and validation, but also have improved prompts that vary from clip to clip; new functionality to review, re-record, and skip clips as an integrated part of the experience; the ability to move quickly between speak and listen; as well as a function to opt-out of speaking for a session.
We also added the option to create a saved profile, which allows contributors to keep track of their progress and metrics across multiple languages. Providing some optional demographic profile information also improves the audio data used in training speech recognition accuracy.
Empower decentralized product innovation: a marathon rather than a sprint
Mozilla aims to contribute to a more diverse and innovative voice technology ecosystem. Our goal is to both release voice-enabled products ourselves, while also supporting researchers and smaller players. Providing data through Common Voice is one part of this, as are the open source Speech-to-Text and Text-to-Speech engines and trained models through project DeepSpeech, driven by our Machine Learning Group.
We know this will take time, and we believe releasing early and working in the open can attract the involvement and feedback of technologists, organisations, and companies that will make these projects more relevant and robust. The current reality for both projects is that they are still in their research phase, with DeepSpeech making strong progress toward productization.
To date, with data from Common Voice and other sources, DeepSpeech is technically capable to convert speech to text with human accuracy and “live”, i.e. in realtime as the audio is being streamed. This allows transcription of lectures, phone conversations, television programs, radio shows, and and other live streams all as they are happening.
The DeepSpeech engine is already being used by a variety of non-Mozilla projects: For example in Mycroft, an open source voice based assistant; in Leon, an open-source personal assistant; in FusionPBX, a telephone switching system installed at and serving a private organization to transcribe phone messages. In the future Deep Speech will target smaller platform devices, such as smartphones and in-car systems, unlocking product innovation in and outside of Mozilla.
For Common Voice, our focus in 2018 was to build out the concept, make it a tool for any language community to use, optimise the website, and build a robust backend (for example, the accounts system). Over the coming months we will focus efforts on experimenting with different approaches to increase the quantity and quality of data we are able to collect, both through community efforts as well as new partnerships.
Our overall aim remains: Providing more and better data to everyone in the world who seeks to build and use voice technology. Because competition and openness are healthy for innovation. Because smaller languages are an issue of access and equity. Because privacy and control matters, especially over your voice.


