The Mozila Services team is happy to announce the release of Heka 0.4, the latest version of our logs and metrics processing platform.
We’ve been hard at work fixing bugs and adding features (see the changelog for a full report). One of the most visible change is a complete overhaul of Heka’s internal dashboard UI. Heka’s prior dashboard UI was just a placeholder, the quickest path to exposing the requisite data, but since the previous release we’ve added a much more attractive Backbone.js-based interface with live updating and greatly improved usability. Using the DashboardOutput you’ll be able to see information on how data is flowing through Heka’s pipeline, view time series graphs generated by filters using circular buffers, and examine any other textual data (including JSON, XML, or any other format) that might be generated by a filter. We’ve been using this internally to help make sense of some of our Telemetry data; the attached screenshots show how this looks.
That’s not all we’ve been up to (see the changelog for the full details). Here are more of the highlights:
- Heka now supports loading and parsing files from a directory (via the LogileDirectoryManagerInput), instead of requiring that all of the files be specified individually. The specified directory will be watched so new folders and files that are added will automatically start being parsed without the need to reconfigure or restart Heka.
- We’ve added a ProcessInput that will let Heka launch external processes on the host machine, using the process’s stdout output as the input data.
- The addition of the PayloadJsonDecoder means that you can now map data extracted from arbitrary JSON text to Heka message fields.
- Sandboxed Lua filters now have access to LPeg (i.e. parsing expression grammar) and JSON decoding libraries, for sophisticated parsing inside your dynamic filter code.
- The hekad config can now be specified as a directory in addition to a single file, to allow complex configurations to be spread across multiple TOML files.
- There is now a global working directory configuration option, allowing plugins to store data relative to a root folder rather than having to maintain a full path for each plugin.
- We’ve greatly improved our input stream parsing, now supporting multi-line records in the input data (with either token or regular expression specified delimiters). That data can come from a log file, an external process, or a TCP, UDP, or AMQP network connection.
- Similarly, protocol buffer-encoded Heka messages are now supported whether the protobuf stream comes from a file, an external process, or one of the currently supported network protocols (TCP, UDP, AMQP).
- It is now possible to use sandboxed Lua code in the decoding step, in addition to the filter plugins that have been supported in prior versions.
As always, we love to hear your feedback. Please join us on the Heka mailing list (highly recommended for all Heka users) and in the #heka IRC channel on irc.mozilla.org, and follow the code, submit bugs, and make suggestions on Github.
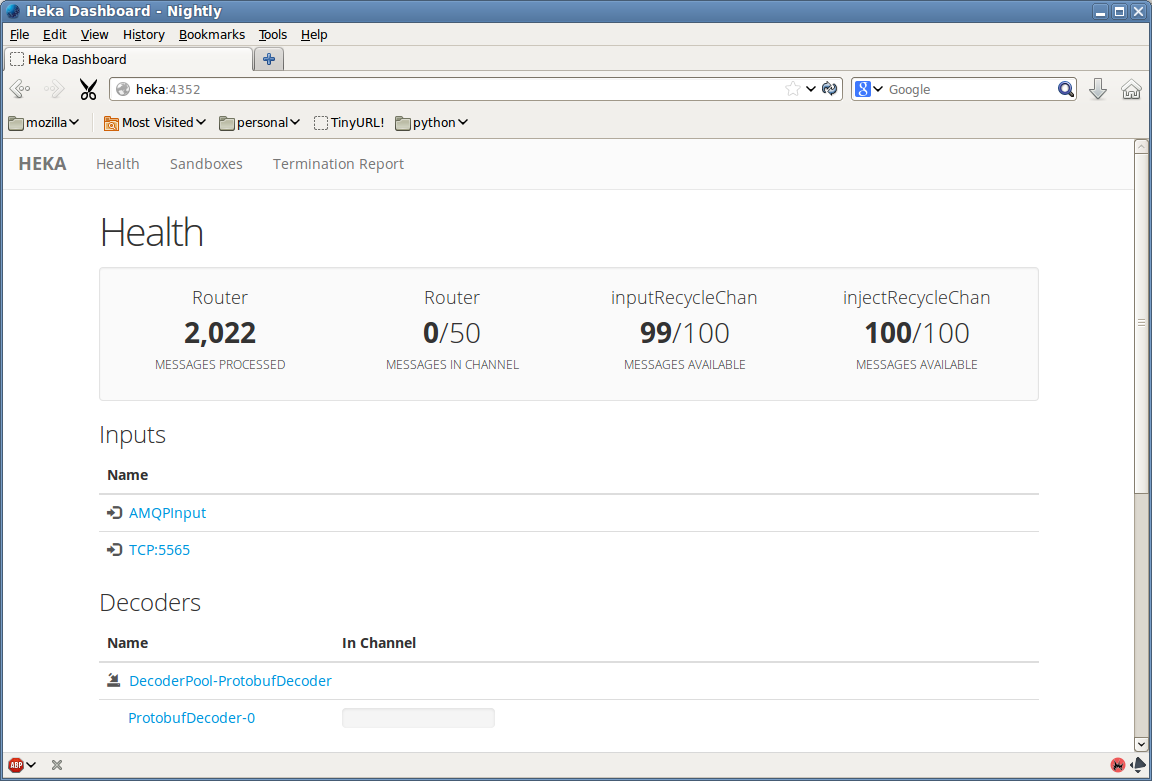
- Heka Health Report
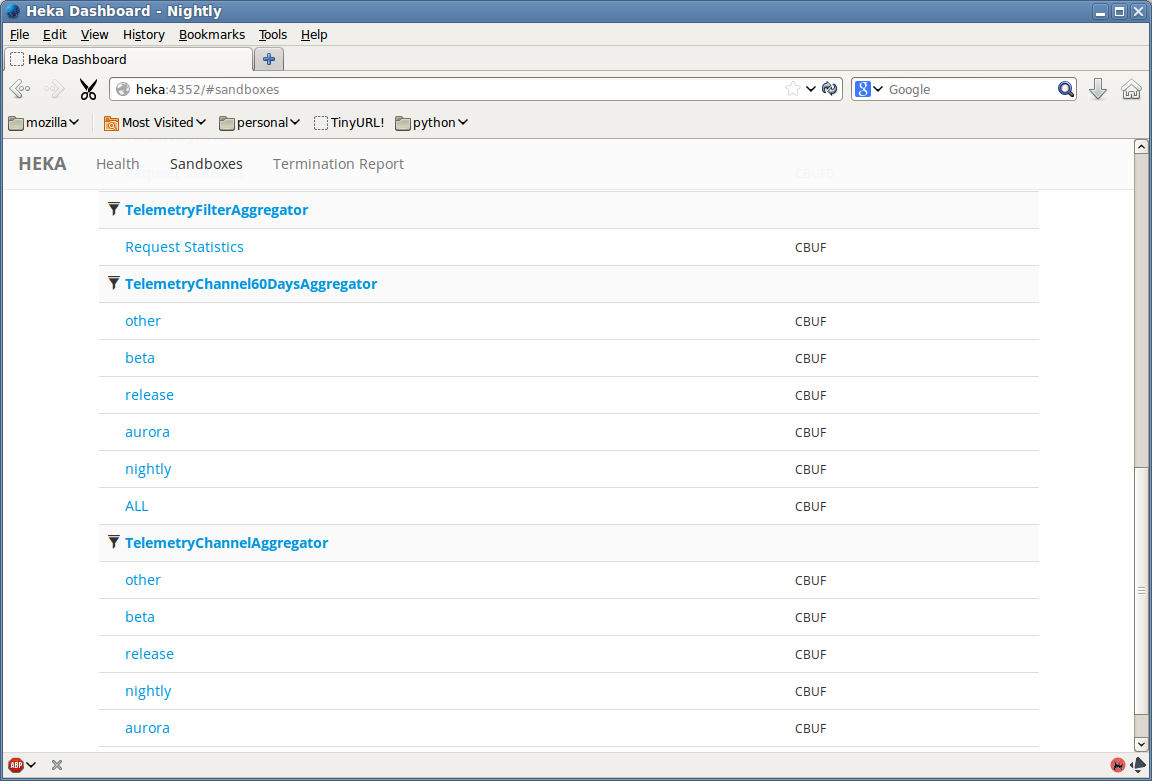
- Heka Sandboxes
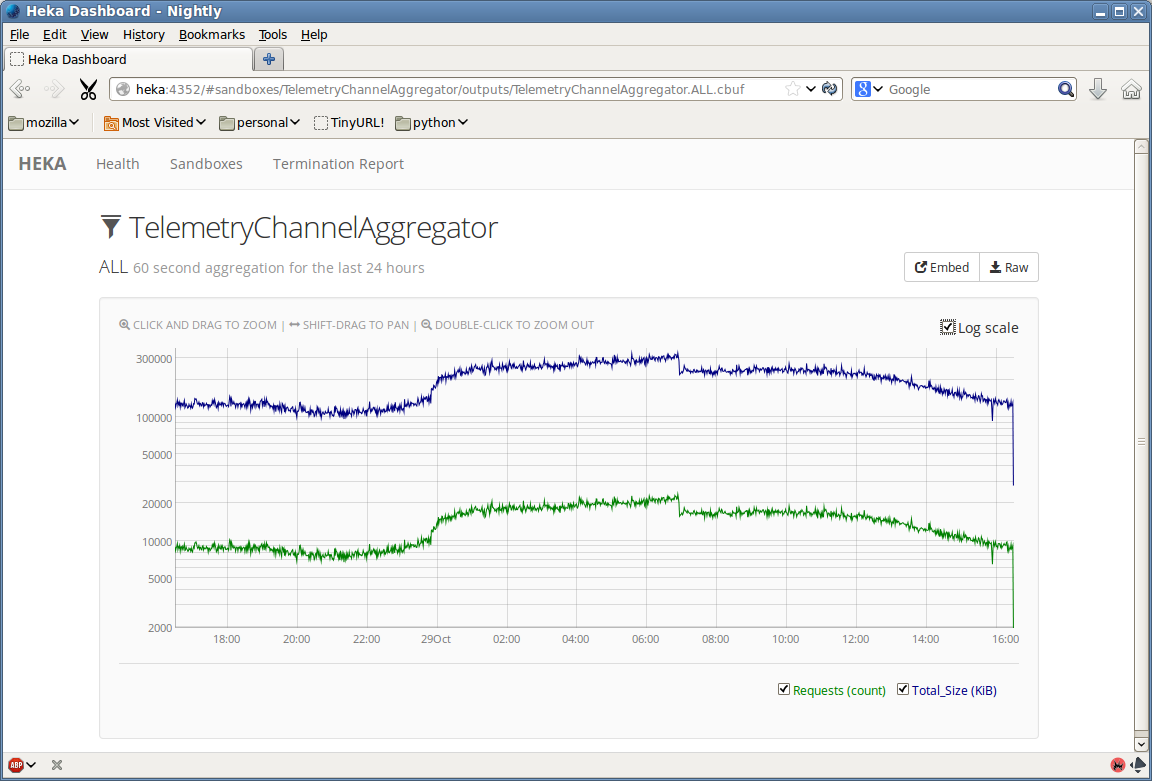
- Sandbox CBuf Output