Intro
There’s a new Sync back-end! The past year or so has been a year of a lot of changes and some of those changes broke things. Our group reorganized, we moved from IRC to Matrix, and a few other things caught us off guard and needed to be addressed. None of those should be excuses for why we kinda stopped keeping you up to date about Sync. We did write a lot of stuff about what we were going to do, but we forgot to share it outside of mozilla. Again, not an excuse, but just letting you know why we felt like we had talked about all of this, even though we absolutely had not.
So, allow me to introduce you to the four person “Services Engineering” team whose job it is to keep a bunch of back-end services running, including Push Notifications and Sync back-end, and a few other miscellaneous services.
For now, let’s focus on Sync.
Current Situation
Sync probably didn’t do what you thought it did.
Sync’s job is to make sure that the bookmarks, passwords, history, extensions and other bits you want to synchronize between one copy of Firefox gets to your other copies of Firefox. Those different copies of Firefox could be different profiles, or be on different devices. Not all of your copies of Firefox may be online or accessible all the time, though, so sync has to do is keep a temporary, encrypted copy on some backend servers which it can use to coordinate later. Since it’s encrypted, Mozilla can’t read that data, we just know it belongs to you. A side effect is that adding a new instance of Firefox (by installing and signing in on a new device, or uninstalling and reinstalling on the same device, or creating a new Firefox profile you then sign in to), just adds another copy of Firefox to Sync’s list of things to synchronize. It might be a bit confusing, but this is true even if you only had one copy of Firefox. If you “lost” a copy of Firefox because you uninstalled it, or your computer’s disc crashed, or your dog buried your phone in the backyard, when you re-installed Firefox, you add another copy of Firefox to your account. Sync would then synchronize your data to that new copy. Sync would just never get an update from the “old” version of Firefox you lost. Sync would just try to rebuild your data from the temporary echoes of the encrypted data that was still on our servers.
That’s great for short term things, but kinda terrible if you, say, shut down Firefox while you go on walk-about only to come back months later to a bad hard drive. You reinstall, try to set up sync, and due to an unexpected Sync server crash we wound up losing your data echos.
That was part of the problem. If we lost a server, we’d basically tell all the copies of Firefox that were using that server, “Whoops, go talk to this new server” and your copy of Firefox would then re-upload what it had. Sometimes this might result in you losing a line of history, sometimes you’d get a duplicate bookmark, but generally, Sync would tend to recover OK and you’d be none the wiser. If that happens when there are no other active copies of Firefox for your account , however, all bets were off and you’d probably lose everything since there were no other copies of your data anywhere.
A New Hope Service
A lot of folks expected it to be a Backup service. The good news is, now it is a backup service. Sync is more reliable now. We use a distributed database to store your data securely, so we no longer lose databases (or your data echos). There’s a lot of benefit for us as well. We were able to rewrite the service in Rust, a more efficient programming language that lets us run on less machines.
Of course, there are a few challenges we face when standing up a service like this.
Sync needs to run with new versions of Firefox, as well as older ones. In some cases, very old ones, which had some interesting “quirks”. It needs to continue to be at least as secure as before while hopefully giving devs a chance to fix some of the existing weirdness as well as add new features. Oh, and switching folks to the new service should be as transparent as possible.
It’s a long, complicated list of requirements.
How we got here
First off we had to decide a few things. Like what data store were we going to use. We picked Google Cloud’s Spanner database for its own pile of reasons, some technical, some non-technical. Spanner provides a SQL like database which means that we don’t have to radically change existing MySQL based code. This means that we can provide some level of abstraction allowing for those who want to self-host without radically altering internal data structures. In addition, Spanner provides us an overall cost savings in running our servers. It’s a SQL like database that should be able to handle what we need to do.
We then picked Rust as our development platform and Actix as the web base because we had pretty good experience with moving other Python projects to them. It’s not been magically easy, and there have been plenty of pain points we’ve hit, but by-and-large we’re confident in the code and it’s proven to be easy enough to work with. Rust has also allowed us to reduce the number of servers we have to run in order to provide the service at the scale we need to offer it, which also helps us reduce costs.
For folks interested in following our progress, we’re working with the syncstorage-rs repo on Github. We also are tracking a bunch of the other issues at the services engineering repo.
Because Rust is ever evolving, often massively useful features roll out on different schedules. For instance, we HEAVILY use the async/await code, which landed in late December of 2019, and is taking a bit to percolate through all the libraries. As those libraries update, we’re going to need to rebuild bits of our server to take advantage of them.
How you can help
Right now, all we can ask is some patience, and possibly help with some of our Good First Bugs. Google released a “stand-alone” spanner emulator that may help you work with our new sync server if you want to play with that part, or you can help us work on the traditional, MySQL stand alone side. That should let you start experimenting with the server and help us find bugs and issues.
To be honest, our initial focus was more on the Spanner integration work than the stand-alone SQL side. We have a number of existing unit tests that exercise both halves and there are a few of us who are very vocal about making sure we support stand-alone SQL databases, but we can use your help testing in more “real world” environments.
For now, folks interested in running the old python 2.7 syncserver still can while we continue to improve stand-alone support inside of syncstorage-rs.
Some folks who run stand-alone servers are well aware that Python 2.7 officially reached “end of life”, meaning no further updates or support is coming from the Python developers, however, we have a bit of leeway here. The Pypy group has said that they plan on offering some support for Python 2.7 for a while longer. Unfortunately, the libraries that we use continue to progress or get abandoned for python3. We’re trying to lock down versions as much as possible, but it’s not sustainable.
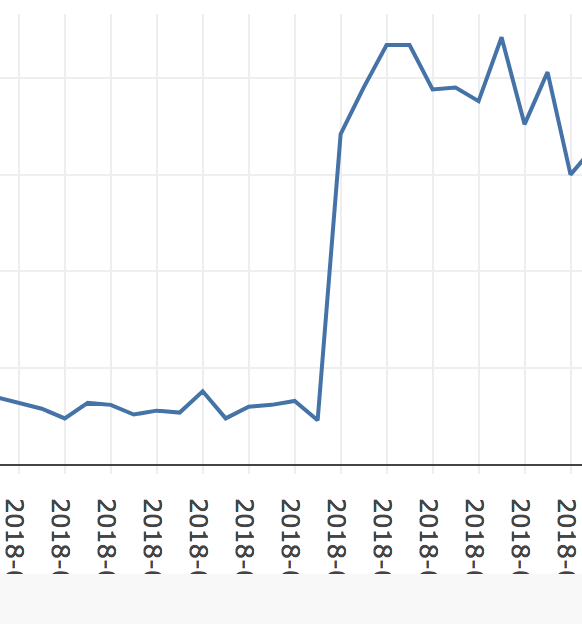
We finally have rust based sync storage working with our durable back end running and hosting users. Our goal is to now focus on the “stand-alone” version, and we’re making fairly good progress.
I’m sorry that things have been too quiet here. While we’ve been putting together lots of internal documents explaining how we’re going to do this move, we’ve not shared them publicly. Hopefully we can clean them up and do that.
We’re excited to offer a new version of Sync and look forward to telling you more about what’s coming up. Stay tuned!