Introduction
The Web Push API provides the ability to deliver real time events (including data) from application servers (app servers) to their client-side counterparts (applications), without any interaction from the user. In other parts of our Push documentation we provide a general reference for the application API and a basic client usage tutorial. This document addresses the app server side portion in detail, including integrating VAPID and Push message encryption into your server effectively, and how to avoid common issues.
Bear in mind that Push is not meant to replace richer messaging technologies like Google Cloud Messaging (GCM), Apple Push Notification system (APNs), or Microsoft’s Windows Notification System (WNS). Each has their benefits and costs, and it’s up to you as developers or architects to determine which system solves your particular set of problems. Push is simply a low cost, easy means to send data to your application.
Push Summary
The Push system looks like:
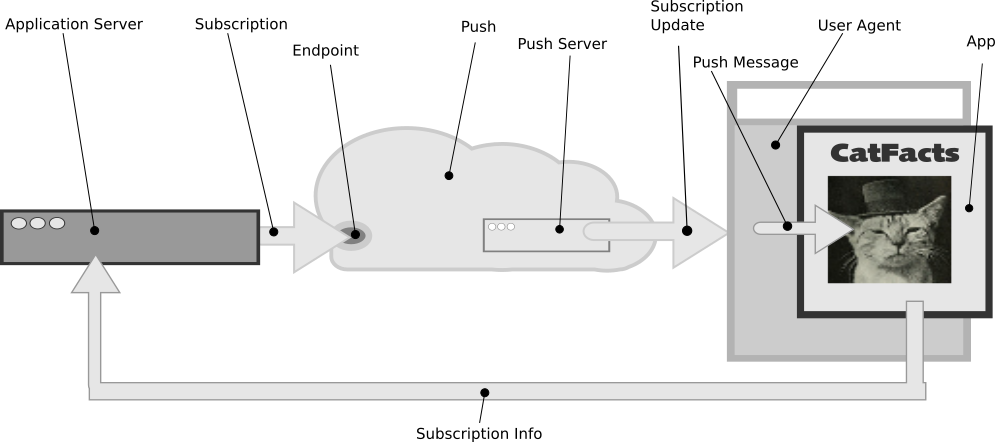
| Application | The user facing part of the program that interacts with the browser in order to request a Push Subscription, and receive Subscription Updates. |
|---|---|
| Application Server | The back-end service that generates Subscription Updates for delivery across the Push Server. |
| Push | The system responsible for delivery of events from the Application Server to the Application. |
| Push Server | The server that handles the events and delivers them to the correct Subscriber. Each browser vendor has their own Push Server to handle subscription management. For instance, Mozilla uses autopush. |
| Subscription | A user request for timely information about a given topic or interest, which involves the creation of an Endpoint to deliver Subscription Updates to. Sometimes also referred to as a “channel”. |
| Endpoint | A specific URL that can be used to send a Push Message to a specific Subscriber. |
| Subscriber | The Application that subscribes to Push in order to receive updates, or the user who instructs the Application to subscribe to Push, e.g. by clicking a “Subscribe” button. |
| Subscription Update | An event sent to Push that results in a Push Message being received from the Push Server. |
| Push Message | A message sent from the Application Server to the Application, via a Push Server. This message can contain a data payload. |
The main parts that are important to Push from a server-side perspective are as follows we’ll cover all of these points below in detail:
- Identifying yourself: This is important for security reasons any server that has an Endpoint can use it to send Push Messages to the corresponding application. Identifying yourself makes this more difficult.
- Receiving subscription information: Below we’ll cover best practices for receiving subscription information on your Application Server.
- Sending subscription updates: both without data and with encrypted data. We will also look at best practice for handling subscription updates.
Identifying Yourself
Mozilla goes to great lengths to respect privacy, but sometimes, identifying your feed can be useful.
Mozilla offers the ability for you to identify your feed content, which is done using the Voluntary Application server Identification for web Push VAPID specification. This is a set of header values you pass with every subscription update. One value is a VAPID key that validates your VAPID claim, and the other is the VAPID claim itself a set of metadata describing and defining the current subscription and where it has originated from.
VAPID is only useful between your servers and our push servers. If we notice something unusual about your feed, VAPID gives us a way to contact you so that things can go back to running smoothly. In the future, VAPID may also offer additional benefits like reports about your feeds, automated debugging help, or other features.
In short, VAPID is a bit of JSON that contains an email address to contact you, an optional URL that’s meaningful about the subscription, and a timestamp. I’ll talk about the timestamp later, but really, think of VAPID as the stuff you’d want us to have to help you figure out something went wrong.
It may be that you only send one feed, and just need a way for us to tell you if there’s a problem. It may be that you have several feeds you’re handling for customers of your own, and it’d be useful to know if maybe there’s a problem with one of them.
Generating your VAPID key
The easiest way to do this is to use an existing library for your language. VAPID is a new specification, so not all languages may have existing libraries.
Currently, we’ve collected several libraries under https://github.com/web-push-libs/vapid and are very happy to learn about more.
Fortunately, the method to generate a key is fairly easy, so you could implement your own library without too much trouble
The first requirement is an Elliptic Curve Diffie Hellman (ECDH) library capable of working with Prime 256v1 (also known as “p256” or similar) keys. For many systems, the OpenSSL package provides this feature. OpenSSL is available for many systems. You should check that your version supports ECDH and Prime 256v1. If not, you may need to download, compile and link the library yourself.
At this point you should generate a EC key for your VAPID identification. Please remember that you should NEVER reuse the VAPID key for the data encryption key you’ll need later. To generate a ECDH key using openssl, enter the following command in your Terminal:
openssl ecparam -name prime256v1 -genkey -noout -out vapid_private.pem
This will create an EC private key and write it into vapid_private.pem. It is important to safeguard this private key. While you can always generate a replacement key that will work, Push (or any other service that uses VAPID) will recognize the different key as a completely different user.
You’ll need to send the Public key as one of the headers . This can be extracted from the private key with the following terminal command:
openssl ec -in vapid_private.pem -pubout -out vapid_public.pem
Creating your VAPID claim
VAPID uses JWT to contain a set of information (or “claims”) that describe the sender of the data. JWTs (or Javascript Web Tokens) are a pair of JSON objects, turned into base64 strings, and signed with the private ECDH key you just made. A JWT element contains three parts separated by “.”, and may look like:
eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiJ9.eyJzdWIiOiAibWFpbHRvOmFkbWluQGV4YW1wbGUuY29tIiwgImV4cCI6ICIxNDYzMDg3Njc3In0.uyVNHws2F3k5jamdpsH2RTfhI3M3OncskHnTHnmdo0hr1ZHZFn3dOnA-42YTZ-u8_KYHOOQm8tUm-1qKi39ppA
- The first element is a “header” describing the JWT object. This JWT header is always the same the static string {typ:"JWT",alg:"ES256"} which is URL safe base64 encoded to eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiJ9. For VAPID, this string should always be the same value.
- The second element is a JSON dictionary containing a set of claims. For our example, we’ll use the following claims:
{ "sub": "mailto:admin@example.com", "aud": "https://push.services.mozilla.com", "exp": "1463001340" }The required claims are as follows:
- sub : The “Subscriber” a mailto link for the administrative contact for this feed. It’s best if this email is not a personal email address, but rather a group email so that if a person leaves an organization, is unavailable for an extended period, or otherwise can’t respond, someone else on the list can. Mozilla will only use this if we notice a problem with your feed and need to contact you.
- aud : The “Audience” is a JWT construct that indicates the recipient scheme and host (e.g. for an endpoint like
https://updates.push.services.mozilla.com/wpush/v1/gAAAAABY..., the “aud” would behttps://updates.push.services.mozilla.com. Some push services will require this field. Please consult your documentation. - exp : “Expires” this is an integer that is the date and time that this VAPID header should remain valid until. It doesn’t reflect how long your VAPID signature key should be valid, just this specific update. Normally this value is fairly short, usually the current UTC time + no more than 24 hours. A long lived “VAPID” header does introduce a potential “replay” attack risk, since the VAPID headers could be reused for a different subscription update with potentially different content.
Feel free to add additional items to your claims. This info really should be the sort of things you want to get at 3AM when your server starts acting funny. For instance, you may run many AWS S3 instances, and one might be acting up. It might be a good idea to include the AMI-ID of that instance (e.g. “aws_id”:”i-5caba953″). You might be acting as a proxy for some other customer, so adding a customer ID could be handy. Just remember that you should respect privacy and should use an ID like “abcd-12345” rather than “Mr. Johnson’s Embarrassing Bodily Function Assistance Service”. Just remember to keep the data fairly short so that there aren’t problems with intermediate services rejecting it because the headers are too big.
Once you’ve composed your claims, you need to convert them to a JSON formatted string, ideally with no padding space between elements1, for example:
{"sub":"mailto:admin@example.com","aud":"https://push.services.mozilla.com","exp":"1463087677"}
Then convert this string to a URL-safe base64-encoded string, with the padding ‘=’ removed. For example, if we were to use python:
import base64
import json
# These are the claims
claims = {"sub":"mailto:admin@example.com",
"aud": "https://push.services.mozilla.com",
"exp":"1463087677"}
# convert the claims to JSON, then encode to base64
body = base64.urlsafe_b64encode(json.dumps(claims))
print body
would give us
eyJhdWQiOiJodHRwczovL3B1c2guc2VydmljZXMubW96aWxsYS5jb20iLCJzdWIiOiJtYWlsdG86YWRtaW5AZXhhbXBsZS5jb20iLCJleHAiOiIxNDYzMDAxMzQwIn0
This is the “body” of the JWT base string.
The header and the body are separated with a ‘.’ making the JWT base string.
eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiJ9.eyJhdWQiOiJodHRwczovL3B1c2guc2VydmljZXMubW96aWxsYS5jb20iLCJzdWIiOiJtYWlsdG86YWRtaW5AZXhhbXBsZS5jb20iLCJleHAiOiIxNDYzMDAxMzQwIn0
Generating the signature depends on your language and library, but is done by the ecdsa algorithm using your private key. If you’re interested in how it’s done in Python or Javascript, you can look at the code in https://github.com/web-push-libs/vapid.
Since your private key will not match the one we’ve generated, the signature you see in the last part of the following example will be different.
eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiJ9.eyJhdWQiOiJodHRwczovL3B1c2guc2VydmljZXMubW96aWxsYS5jb20iLCJzdWIiOiJtYWlsdG86YWRtaW5AZXhhbXBsZS5jb20iLCJleHAiOiIxNDYzMDAxMzQwIn0.y_dvPoTLBo60WwtocJmaTWaNet81_jTTJuyYt2CkxykLqop69pirSWLLRy80no9oTL8SDLXgTaYF1OrTIEkDow
Forming your headers
The VAPID claim you assembled in the previous section needs to be sent along with your Subscription Update as an Authorization header vapid token. This is a compound key consisting of the JWT token you just created (designated as t=) and the VAPID public key as its value formatted as a URL safe, base64 encoded DER formatted string of the raw key.
If you like, you can cheat here and use the content of “vapid_public.pem”. You’ll need to remove the “-----BEGIN PUBLIC KEY------” and “-----END PUBLIC KEY-----” lines, remove the newline characters, and convert all “+” to “-” and “/” to “_”.
The complete token should look like so:
Authorization: vapid t=eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiJ9.eyJhdWQiOiJodHRwczovL3B1c2guc2VydmljZXMubW96aWxsYS5jb20iLCJzdWIiOiJtYWlsdG86YWRtaW5AZXhhbXBsZS5jb20iLCJleHAiOiIxNDYzMDAxMzQwIn0.y_dvPoTLBo60WwtocJmaTWaNet81_jTTJuyYt2CkxykLqop69pirSWLLRy80no9oTL8SDLXgTaYF1OrTIEkDow,k=BAS7pgV_RFQx5yAwSePfrmjvNm1sDXyMpyDSCL1IXRU32cdtopiAmSysWTCrL_aZg2GE1B_D9v7weQVXC3zDmnQ
You can validate your work against the VAPID test page this will tell you if your headers are properly encoded. In addition, the VAPID repo contains libraries for JavaScript and Python to handle this process for you.
We’re happy to consider PRs to add libraries covering additional languages.
Receiving Subscription Information
Your Application will receive an endpoint and key retrieval functions that contain all the info you’ll need to successfully send a Push message. See Using the Push API for details about this. Your application should send this information, along with whatever additional information is required, securely to the Application Server as a JSON object.
Such a post back to the Application Server might look like this:
{
"customerid": "123456",
"subscription": {
"endpoint": "https://updates.push.services.mozilla.com/push/v1/gAAAA…",
"keys": {
"p256dh": "BOrnIslXrUow2VAzKCUAE4sIbK00daEZCswOcf8m3TF8V…",
"auth": "k8JV6sjdbhAi1n3_LDBLvA"
}
},
"favoritedrink": "warm milk"
}
In this example, the “subscription” field contains the elements returned from a fulfilled PushSubscription. The other elements represent additional data you may wish to exchange.
How you decide to exchange this information is completely up to your organization. You are strongly advised to protect this information. If an unauthorized party gained this information, they could send messages pretending to be you. This can be made more difficult by using a “Restricted Subscription”, where your application passes along your VAPID public key as part of the subscription request. A restricted subscription can only be used if the subscription carries your VAPID information signed with the corresponding VAPID private key. (See the previous section for how to generate VAPID signatures.)
Subscription information is subject to change and should be considered “opaque”. You should consider the data to be a “whole” value and associate it with your user. For instance, attempting to retain only a portion of the endpoint URL may lead to future problems if the endpoint URL structure changes. Key data is also subject to change. The app may receive an update that changes the endpoint URL or key data. This update will need to be reflected back to your server, and your server should use the new subscription information as soon as possible.
Sending a Subscription Update Without Data
Subscription Updates come in two varieties: data free and data bearing. We’ll look at these separately, as they have differing requirements.
Data Free Subscription Updates
Data free updates require no additional App Server processing, however your Application will have to do additional work in order to act on them. Your application will simply get a “push” message containing no further information, and it may have to connect back to your server to find out what the update is. It is useful to think of Data Free updates like a doorbell “Something wants your attention.”
To send a Data Free Subscription, you POST to the subscription endpoint. In the following example, we’ll include the VAPID header information. Values have been truncated for presentation readability.
curl -v -X POST\
-H "Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiJ9.eyJhdWQiOiJodHR…"\
-H "Crypto-Key: p256ecdsa=BA5vkyMXVfaKuehJuecNh30-NiC7mT9gM97Op5d8LiAKzfIezLzC…"\
-H "TTL: 0"\
"https://updates.push.services.mozilla.com/push/v1/gAAAAABXAuZmKfEEyPbYfLXqtPW…"
This should result in an Application getting a “push” message, with no data associated with it.
To see how to store the Push Subscription data and send a Push Message using a simple server, see our Using the Push API article.
Data Bearing Subscription Updates
Data Bearing updates are a lot more interesting, but do require significantly more work. This is because we treat our own servers as potentially hostile and require “end-to-end” encryption of the data. The message you send across the Mozilla Push Server cannot be read. To ensure privacy, however, your application will not receive data that cannot be decoded by the User Agent.
There are libraries available for several languages at https://github.com/web-push-libs, and we’re happy to accept or link to more.
The encryption method used by Push is Elliptic Curve Diffie Hellman (ECDH) encryption, which uses a key derived from two pairs of EC keys. If you’re not familiar with encryption, or the brain twisting math that can be involved in this sort of thing, it may be best to wait for an encryption library to become available. Encryption is often complicated to understand, but it can be interesting to see how things work.
Data encryption summary
This encoding is currently the most widely supported, however it is out-of-date.
The core principles remain the same across versions, however the final formatting differs.
There is some effort being made to have the UA report back the forms of encryption content it supports,
however that may not be available at time of publication.
You’re strongly encouraged to use a ECE library when possible.
- Octet An 8 bit byte of data (between \x00 and \xFF)
- Subscription data The subscription data to encode and deliver to the Application.
- Endpoint the Push service endpoint URL, received as part of the Subscription data.
- Receiver key The p256dh key received as part of the Subscription data.
- Auth key The auth key received as part of the Subscription data.
- Payload The data to encrypt, which can be any streamable content between 2 and 4096 octets.
- Salt 16 octet array of random octets, unique per subscription update.
- Sender key A new ECDH key pair, unique per subscription update.
Web Push limits the size of the data you can send to between 2 and 4096 octets. You can send larger data as multiple segments, however that can be very complicated. It’s better to keep segments smaller. Data, whatever the original content may be, is also turned into octets for processing.
Each subscription update requires two unique items a salt and a sender key. The salt is a 16 octet array of random octets. The sender key is a ECDH key pair generated for this subscription update. It’s important that neither the salt nor sender key be reused for future encrypted data payloads. This does mean that each Push message needs to be uniquely encrypted.
The receiver key is the public key from the client’s ECDH pair. It is base64, URL safe encoded and will need to be converted back into an octet array before it can be used. The auth key is a shared “nonce”, or bit of random data like the salt.
Emoji Based Diagram
| Subscription Data | Per Update Info | Update |
|---|---|---|
| 🎯 Endpoint | 🔑 Private Server Key | 📄Payload |
| 🔒 Receiver key (‘p256dh’) | 🗝 Public Server Key | |
| 💩 Auth key (‘auth’) | 📎 Salt | |
| 🔐 Private Sender Key | ||
| ✒️ Public Server Key | ||
| 🏭 Build using / derive | ||
| 🔓 message encryption key | ||
| 🎲 message nonce |
Encryption uses a fabricated key and nonce. We’ll discuss how the actual encryption is done later, but for now, let’s just create these items.
Creating the Encryption Key and Nonce
The encryption uses HKDF (Hashed Key Derivation Function) using a SHA256 hash very heavily.
Creating the secret
The first HKDF function you’ll need will generate the common secret (🙊), which is a 32 octet value derived from a salt of the auth (💩) and run over the string “Content-Encoding: auth\x00”.
So, in emoji =>
🔐 = 🔑(🔒);
🙊 = HKDF(💩, “Content-Encoding: auth\x00”).🏭(🔐)
An example function in Python could look like so:
# receiver_key must have "=" padding added back before it can be decoded.
# How that's done is an exercise for the reader.
# 🔒
receiver_key = subscription['keys']['p256dh']
# 🔑
server_key = pyelliptic.ECC(curve="prime256v1")
# 🔐
sender_key = server_key.get_ecdh_key(base64.urlsafe_b64decode(receiver_key))
#🙊
secret = HKDF(
hashes.SHA256(),
length = 32,
salt = auth,
info = "Content-Encoding: auth\0").derive(sender_key)
The encryption key and encryption nonce
The next items you’ll need to create are the encryption key and encryption nonce.
An important component of these is the context, which is:
- A string comprised of ‘P-256’
- Followed by a NULL (“\x00”)
- Followed by a network ordered, two octet integer of the length of the decoded receiver key
- Followed by the decoded receiver key
- Followed by a networked ordered, two octet integer of the length of the public half of the sender key
- Followed by the public half of the sender key.
As an example, if we have an example, decoded, completely invalid public receiver key of ‘RECEIVER’ and a sample sender key public key example value of ‘sender’, then the context would look like:
# ⚓ (because it's the base and because there are only so many emoji)
root = "P-256\x00\x00\x08RECEIVER\x00\x06sender"
The “\x00\x08” is the length of the bogus “RECEIVER” key, likewise the “\x00\x06” is the length of the stand-in “sender” key. For real, 32 octet keys, these values will most likely be “\x00\x20” (32), but it’s always a good idea to measure the actual key rather than use a static value.
The context string is used as the base for two more HKDF derived values, one for the encryption key, and one for the encryption nonce. In python, these functions could look like so:
In emoji:
🔓 = HKDF(💩 , “Content-Encoding: aesgcm\x00” + ⚓).🏭(🙊)
🎲 = HKDF(💩 , “Content-Encoding: nonce\x00” + ⚓).🏭(🙊)
#🔓
encryption_key = HKDF(
hashes.SHA256(),
length=16,
salt=salt,
info="Content-Encoding: aesgcm\x00" + context).derive(secret)
# 🎲
encryption_nonce = HDKF(
hashes.SHA256(),
length=12,
salt=salt,
info="Content-Encoding: nonce\x00" + context).derive(secret)
Note that the encryption_key is 16 octets and the encryption_nonce is 12 octets. Also note the null (\x00) character between the “Content-Encoding” string and the context.
At this point, you can start working your way through encrypting the data 📄, using your secret 🙊, encryption_key 🔓, and encryption_nonce 🎲.
Encrypting the Data
The function that does the encryption (encryptor) uses the encryption_key 🔓 to initialize the Advanced Encryption Standard (AES) function, and derives the Galois/Counter Mode (G/CM) Initialization Vector (IV) off of the encryption_nonce 🎲, plus the data chunk counter. (If you didn’t follow that, don’t worry. There’s a code snippet below that shows how to do it in Python.) For simplicity, we’ll presume your data is less than 4096 octets (4K bytes) and can fit within one chunk.
The IV takes the encryption_nonce and XOR’s the chunk counter against the final 8 octets.
def generate_iv(nonce, counter):
(mask,) = struct.unpack("!Q", nonce[4:]) # get the final 8 octets of the nonce
iv = nonce[:4] + struct.pack("!Q", counter ^ mask) # the first 4 octets of nonce,
# plus the XOR'd counter
return iv
The encryptor prefixes a “\x00\x00” to the data chunk, processes it completely, and then concatenates its encryption tag to the end of the completed chunk. The encryptor tag is a static string specific to the encryptor. See your language’s documentation for AES encryption for further information.
def encrypt_chunk(chunk, counter, encryption_nonce, encryption_key):
encryptor = Cipher(algorithms.AES(encryption_key),
modes.GCM(generate_iv(encryption_nonce,
counter))
return encryptor.update(b"\x00\x00" + chunk) +
encryptor.finalize() +
encryptor.tag
def encrypt(payload, encryption_nonce, encryption_key):
result = b""
counter = 0
for i in list(range(0, len(payload)+2, 4096):
result += encrypt_chunk(
payload[i:i+4096],
counter,
encryption_key,
encryption_nonce)
Sending the Data
Encrypted payloads need several headers in order to be accepted.
The Crypto-Key header is a composite field, meaning that different things can store data here. There are some rules about how things should be stored, but we can simplify and just separate each item with a semicolon “;”. In our case, we’re going to store three things, a “keyid”, “p256ecdsa” and “dh”.
“keyid” is the string “p256dh”. Normally, “keyid” is used to link keys in the Crypto-Key header with the Encryption header. It’s not strictly required, but some push servers may expect it and reject subscription updates that do not include it. The value of “keyid” isn’t important, but it must match between the headers. Again, there are complex rules about these that we’re safely ignoring, so if you want or need to do something complex, you may have to dig into the Encrypted Content Encoding specification a bit.
“p256ecdsa” is the public key used to sign the VAPID header (See Forming your Headers). If you don’t want to include the optional VAPID header, you can skip this.
The “dh” value is the public half of the sender key we used to encrypt the data. It’s the same value contained in the context string, so we’ll use the same fake, stand-in value of “sender”, which has been encoded as a base64, URL safe value. For our example, the base64 encoded version of the string ‘sender’ is ‘c2VuZGVy’
Crypto-Key: p256ecdsa=BA5v…;dh=c2VuZGVy;keyid=p256dh
The Encryption Header contains the salt value we used for encryption, which is a random 16 byte array converted into a base64, URL safe value.
Encryption: keyid=p256dh;salt=cm5kIDE2IGJ5dGUgc2FsdA
The TTL Header is the number of seconds the notification should stay in storage if the remote user agent isn’t actively connected. “0” (Zed/Zero) means that the notification is discarded immediately if the remote user agent is not connected; this is the default. This header must be specified, even if the value is “0”.
TTL: 0
Finally, the Content-Encoding Header specifies that this content is encoded to the aesgcm standard.
Content-Encoding: aesgcm
The encrypted data is set as the Body of the POST request to the endpoint contained in the subscription info. If you have requested that this be a restricted subscription and passed your VAPID public key as part of the request, you must include your VAPID information in the POST.
As an example, in python:
headers = {
'crypto-key': 'p256ecdsa=BA5v…;dh=c2VuZGVy;keyid=p256dh',
'content-encoding': 'aesgcm',
'encryption': 'keyid=p256dh;salt=cm5kIDE2IGJ5dGUgc2FsdA',
'ttl': 0,
}
requests.post(subscription_info['subscription']['endpoint'],
data=encrypted_data,
headers=headers)
A successful POST will return a response of 201, however, if the User Agent cannot decrypt the message, your application will not get a “push” message. This is because the Push Server cannot decrypt the message so it has no idea if it is properly encoded. You can see if this is the case by:
- Going to about:config in Firefox
- Setting the dom.push.loglevel pref to debug
- Opening the Browser Console (located under Tools > Web Developer > Browser Console menu.
When your message fails to decrypt, you’ll see a message similar to the following

You can use values displayed in the Web Push Data Encryption Page to audit the values you’re generating to see if they’re similar. You can also send messages to that test page and see if you get a proper notification pop-up, since all the key values are displayed for your use.
You can find out what errors and error responses we return, and their meanings by consulting our server documentation.
Subscription Updates
Nothing (other than entropy) lasts forever. There may come a point where, for various reasons, you will need to update your user’s subscription endpoint. There are any number of reasons for this, but your code should be prepared to handle them.
Your application’s service worker will get a onpushsubscriptionchange event. At this point, the previous endpoint for your user is now invalid and a new endpoint will need to be requested. Basically, you will need to re-invoke the method for requesting a subscription endpoint. The user should not be alerted of this, and a new endpoint will be returned to your app.
Again, how your app identifies the customer, joins the new endpoint to the customer ID, and securely transmits this change request to your server is left as an exercise for the reader. It’s worth noting that the Push server may return an error of 410 with an errno of 103 when the push subscription expires or is otherwise made invalid. (If a push subscription has expired several months ago, the server may return a different errno value.
Conclusion
Push Data Encryption can be very challenging, but worthwhile. Harder encryption means that it is more difficult for someone to impersonate you, or for your data to be read by unintended parties. Eventually, we hope that much of this pain will be buried in libraries that allow you to simply call a function, and as this specification is more widely adopted, it’s fair to expect multiple libraries to become available for every language.
See also:
- WebPush Libraries: A set of libraries to help encrypt and send push messages.
- VAPID lib for python or javascript can help you understand how to encode VAPID header data.
Footnotes:
- Technically, you don’t need to strip the whitespace from JWS tokens. In some cases, JWS libraries take care of that for you. If you’re not using a JWS library, it’s still a very good idea to make headers and header lines as compact as possible. Not only does it save bandwidth, but some systems will reject overly lengthy header lines. For instance, the library that autopush uses limits header line length to 16,384 bytes. Minus things like the header, signature, base64 conversion and JSON overhead, you’ve got about 10K to work with. While that seems like a lot, it’s easy to run out if you do things like add lots of extra fields to your VAPID claim set.