Ever wonder just how much you gain by having Apache serve your static files? I had a particularly hairy set of RewriteRules to support this in my project and a fairly simple Python routine as an alternative, so I ran a few benchmarks to find out.
DXR is a code navigation and static analysis tool for the Firefox codebase. It consists of two parts:
- A Flask app which runs under Apache via mod_wsgi
- An offline build process which generates a syntax-highlighted version of every Firefox source file as HTML and lays them down on disk
These generated files are the ones served by RewriteRules in production:
However, for convenience during development, we also have a trivial Python routine to serve those files:
I pitted the RewriteRules against the Python controller on a local VM, so keep in mind that all the standard caveats of complex systems apply. That said, let’s see what happened!
Having heard complaints about NFS-based VirtualBox shared directories (where my generated files lived), I expected both solutions to be bottlenecked on IO. To my surprise, I saw a pronounced difference between them.
The RewriteRules serve static pages in an average of 6 ms at a concurrency of 10. This is a representative test run of ab. The tables at the bottom are the most important parts:
(py27)[15:16:12 ~/Checkouts/dxr]% ab -c 10 -n 1000 http://33.33.33.77/code/README.mkd
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 33.33.33.77 (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software: Apache/2.2.22
Server Hostname: 33.33.33.77
Server Port: 80
Document Path: /code/README.mkd
Document Length: 7348 bytes
Concurrency Level: 10
Time taken for tests: 0.573 seconds
Complete requests: 1000
Failed requests: 0
Write errors: 0
Total transferred: 7635628 bytes
HTML transferred: 7355348 bytes
Requests per second: 1744.93 [#/sec] (mean)
Time per request: 5.731 [ms] (mean)
Time per request: 0.573 [ms] (mean, across all concurrent requests)
Transfer rate: 13011.36 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 0.4 2 4
Processing: 1 4 4.9 4 124
Waiting: 1 4 3.1 4 99
Total: 2 6 4.9 5 124
Percentage of the requests served within a certain time (ms)
50% 5
66% 6
75% 6
80% 6
90% 6
95% 7
98% 7
99% 8
100% 124 (longest request)
Routing the requests through Python instead drives the mean up to 14 ms:
50% 14 66% 15 75% 16 80% 17 90% 19 95% 21 98% 23 99% 25 100% 32 (longest request)
This is with WSGIDaemonProcess example.com processes=2 threads=2, which, after a little experimentation, I determined is close to optimal for my 4-CPU VM. It makes some intuitive sense: one thread for each logical core. The host box has 4 physical cores with hyperthreading, so there are plenty to go around.
Turning the concurrency down to 2 had surprising results: Python actually got slightly faster than Apache: 3 ms avg. This could be measurement noise.
50% 3 66% 3 75% 4 80% 4 90% 4 95% 5 98% 7 99% 8 100% 222 (longest request)
-c 4 yields 6 ms:
50% 6 66% 7 75% 8 80% 8 90% 10 95% 11 98% 12 99% 12 100% 14 (longest request)
And, more generally, there is a linear performance trailoff as concurrency increases:
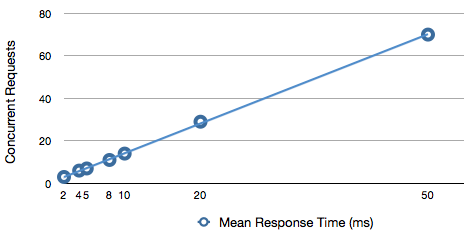
This was a surprise, as I expected more of a cliff when I exceeded the complement of 4 WSGI threads.
When we keep our concurrency down, it turns out that Apache doesn’t necessarily run the RewriteRules any faster than Python executes browse(). However, at high concurrency, Apache does pull ahead of Python, presumably because it has more threads to go around. That will probably hold true in production, since raw Apache processes eat less RAM than WSGI children and will thus have their threads capped less stringently.
Is a gain of twenty-some milliseconds for likely concurrency levels worth the added complexity—and logic duplication—of the RewriteRules? I think not. To get an idea of what 20 ms feels like, the human audio wetware juuuust begins to recognize two adjacent sounds as distinct when they are 20 ms apart: any closer, and they blend into a continuous tone. (Some sources go as low as 12Hz.) There are some usability studies that estimate a 1% dropoff in conversion rate for every extra 100 ms a page takes to load, but no one bothers to measure very fast-loading pages, and I would expect to reach a “fast enough” plateau eventually. Even if the linear relationship were overturned on real hardware, real hardware should be faster, making the latency differences (within reasonable concurrencies) even less than 20 ms. The “go ahead and use Python” conclusion should hold.
Finally, it’s worth mentioning that I’m still serving what are classically in the category of “static resources”—CSS, JS, images, and the like—with Apache, because we can do so in one simple Alias directive. What’s to lose?
Obviously, this is a boisterously multidimensional search space, comprising virtualization, threads, hardware, and IO abstraction, and I had ab running on the same physical box, so take these exact results as a single data point. However, they do establish a nice ceiling that lets us stop worrying about wringing every last drop out of the web server.
karl wrote on
:
wrote on
:
Erik Rose wrote on
:
wrote on
:
Nils Maier wrote on
:
wrote on
:
Robert wrote on
:
wrote on
:
Erik Rose wrote on
:
wrote on
:
Hanno Schlichting wrote on
:
wrote on
:
Erik Rose wrote on
:
wrote on
: