By: Alessio Placitelli, Ben Miroglio, Jason Thomas, Shell Escalante and Martin Lopatka.
With special recognition of the development efforts of Roberto Vitillo who kickstarted this project, Mauro Doglio for massive contributions to the code base during his time at Mozilla, Florian Hartmann, who contributed efforts towards prototyping the ensemble linear combiner, Stuart Colville for coordinating integration with AMO. Last, but not least, to Anthony Miyaguchi who helped shaping the current code thanks to his reviewing efforts.
What’s TAAR?
Firefox has a robust ecosystem of add-ons that can enhance the browsing experience, but all users are different and not all add-ons are right for everyone. The TAAR project (Telemetry Aware Addon Recommender) is an experimental product developed over the course of 2017 to provide a personalized experience for Firefox users seeking to install add-ons based on available information already in Mozilla’s telemetry data. Our aim is to provide potentially interesting add-ons or useful replacements to add-ons built on legacy technology, without the need for additional data collection. Add-ons created with the new standard (after legacy) are safer, more secure, and won’t break in new Firefox releases.
Unlike conventional recommender systems, we designed TAAR to provide interesting add-on recommendations based on the Telemetry data Firefox collects in accordance to Mozilla’s Data Privacy Principles and privacy policy. The data contains, among other things, browser performance data and an hardware overview. This information is collected from Firefox desktop and can be disabled if users choose to do so. Retrofitting an existing data source to a new application is no easy task, but we are really happy with TAAR’s functionality in leveraging different information sources based on availability to provide a personalized add-on recommendation list.
Design philosophy
If there is anything the Netflix prize has taught the world about recommender systems, it is the importance of contextual information in practical recommendation ranking. In developing the TAAR system, we had additional constraints around the information available pertaining to clients’ interaction with the add-ons ecosystem.
Firstly, only 40% of Firefox users have an add-on installed and enabled. While existing add-on installations can be a very powerful predictor of add-on interest, there are a number of known shortcomings typical of collaborative filter type recommendations in terms of cold start, diversity and the long tail, and general lack of information for clients without currently installed add-ons. For this reason a fall-through approach was implemented to leverage information sources in order of their expected predictive value and based on the availability of information.
How it’s being deployed?
Building a new feature into Firefox always triggers the questions: will it work and will our users find it useful? To answer these we decided to let a fraction of the Firefox users on the Release channel to try it out through a SHIELD study: if user is enrolled in this study a modified about:addons page might be served incorporating recommendations from TAAR.
How does it work?
When the user opens the TAAR-enabled about:addons page, Firefox fetches the page content from discovery.addons.mozilla.org (AMO frontend). The client id is sent along with the page request and forwarded to the taar-api endpoint.
The TAAR library is called right after the request is parsed and validated. It queries our backend services to look up the most recent data for the client given the provided client id. This data is eventually passed to the other TAAR components to produce relevant add-on recommendations, which are returned to the browser as a list of add-on GUIDs which are rendered on the about:addons page.
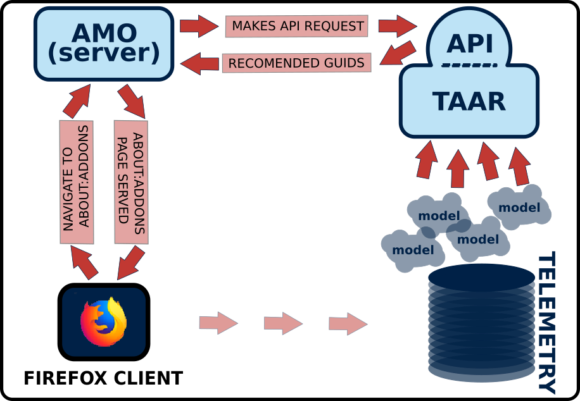
How does TAAR work?
The TAAR system is made up of 3 main components:
- the profile fetcher, which is responsible of looking up the latest data about the client given its id;
- the recommendation modules, each one implementing a different recommendation model;
- the recommendation manager, implementing a recommendation strategy and calling the relevant recommendation modules.
The current version of TAAR implements a basic recommendation manager which executes a simple recommendation strategy: once a recommendation is requested for a specific client id, the recommender iterates through all the registered recommendation modules linearly in their registered order. The first module that can perform a recommendation will return its results.
Each recommendation module defines its own, independent sets of requirements and exposes a single function that the manager can use to verify that a recommendation can be performed by that module. At the time of writing this post, we have four different TAAR modules: legacy, collaborative, similarity and locale.
To make sure recommendations are computed quickly, the heavy lifting for each recommendation module is performed off-line, in a series of Python ETL jobs that are scheduled to run weekly, on Monday.
The legacy model
This is the first model our recommendation strategy tries to recommend with. Its objective is to suggest add-ons to those users that have legacy add-ons installed (even if these are disabled).
On the backend, a weekly job makes use of the add-ons replacement API to build a dictionary of recommendations for each legacy add-on. The resulting file is shared with TAAR and consumed by the recommender.
The collaborative model
The collaborative filtering model attempts to perform relevant recommendations by analysing which add-ons similar users like. This model requires that each user has at least one installed add-on: the underlying assumption is that users with similar add-ons might have similar add-on interests.
The core of this approach is the recommender weekly job which performs the following basic tasks: it loads the list of valid add-ons from AMO, builds a users/add-ons matrix and perform matrix factorization. Since every user does not install every single add-on, the initial matrix is sparse by definition. As a consequence, the purpose of the last step is to find an approximate matrix that contains a confidence value related to the strength of each add-on recommendation for every user.
The resulting approximation is then used by TAAR module to perform the final recommendation: for a given list of add-ons coming from the requesting user, the closest row is picked from the matrix. The add-ons with the highest confidence value from this row are then returned and recommended to the user.
While this approach is intuitive and proved to work at scale and in production, it’s main drawback is that it suffers from the cold start problem: new users might receive bad recommendations and new add-ons might not get recommended. The first part of the problem is solved by requiring at least one add-on to be installed. The second problem is mitigated by using the other recommendation modules.
The similarity-based model
The similarity based recommendation model aims to identify candidate clients that may be similar enough to a new client that the philosophy of a collaborative filter can be extended to the independent feature space of other telemetry variables. Pairwise similarity in a subspace of the Firefox telemetry features has been investigated for its predictive value in terms of add-on installation likelihood. We began by identifying a set of candidate add-on donors. In order to ensure that a diverse sample of add-ons was represented in our candidate donors, we applied a bisecting K-means clustering algorithm (a form of divisive clustering) utilizing only the vector representation of installed add-ons to derive a number of clusters encompassing a diverse sample of add-on installations.
From the non-add-on telemetry variables. Donor clients belonging to the same add-on cluster are deemed to be similar in terms of their add-on preferences and similarity scores observed between same cluster clients are pooled as “same cluster” distances. Likewise, distances computed between clients in different add-on clusters are accumulated in a list of “different cluster” observed distances to generalise the relationship between add-on similarity and telemetry similarity.
The generalisation of pairwise distances computed for in-group and out-group relationships allows us to specify a model comparing the probability of observing a particular similarity (here synonymous to a specified distance metric) under one of two assumptions (same add-on cluster versus different add-on cluster). This can be represented as a general likelihood ratio model that gives us a very natural quantity pertaining to the chances that an add-on (taken from the pool of those installed by an add-on donor) may be interesting for a new client with a particular similarity to that client donor.
The corresponding ETL job can be seen here and the recommender module itself is implemented in the core TAAR library.
Candidate add-on donors are sampled weekly ensuring continuously fresh sampling of the add-ons ecosystem and allowing the possibility of new pattern discovery and the inclusion of new add-ons in the recommendation pool.
The similarity recommender module utilises the likelihood ratio model (computed weekly) to compare an incoming client with a set of (weekly resampled) donors to generate a ranked list of add-on recommendations.
The locale model
This is the last model that gets called, and the last attempt we make to give user a reasonable add-on recommendation. This model relies on user’s locale in order to recommend the relevant add-ons in that geographical area.
The locale ETL job computes the most reported add-ons for all our known locales. However, to preserve user’s privacy, we don’t recommend add-ons in locales for which we don’t have enough data. This mitigates the risk of recommending add-ons that could trace back to a small group of individuals.
The first TAAR study
Shield is a Firefox user testing platform that allows us to try out and evaluate new features through experimentation, or what we call Shield Studies. Common applications of Shield Studies include changing preferences, displaying messaging or distributing surveys.
To test the efficacy of TAAR, we ran an opt-out shield study on the Firefox Release channel. For half the users enrolled in the study, we changed the URL for the Add-ons Discovery Pane, which loads when a user types about:addons into the address bar or clicks on “Add-ons” from the Firefox menu.
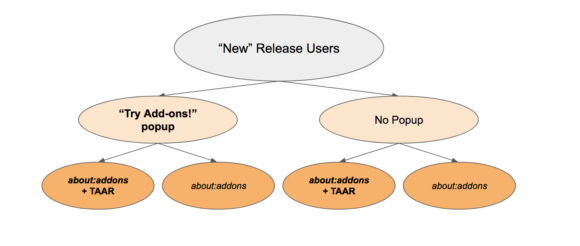
The altered URL tells AMO to send the user’s client id to TAAR and load recommendations into the page, if possible. Within each test group we exposed half to a notification prompting the user to “try add-ons” with a link to the about:addons page, thus creating 4 distinct groups with equal probabilities (0.25) of assignment. We tried to focus on new users for the study, to get a better understanding of clients’ entry into the add-ons ecosystem between our prompted and un-prompted study branches.
We focused on two measures in this shield study:
- installation rate (proportion of clients that installed 1+ add-on(s));
- installs per client (number of installs / number of clients).
We came away with three main findings from this study:
- clients exposed to a notification are more likely to install an add-on (installation rate +17.19%);
- clients that see TAAR recommendations are not more likely to install an add-on (installation rate +~0%, small effect, but not statistically significant);
- clients that see TAAR recommendations are more likely to install a larger number of add-ons (installs per client +1.4%).
An additional data source available in the analysis following the first TAAR study was the corpus of application log files generated by the TAAR library itself. A slightly deeper dive into the findings regarding the number of add-on installations throughout the course of the study revealed an interesting narrative. Clients initially served by the similarity-based model were frequently seen later, with around 18% returning to the TAAR service and being served by the collaborative model.
Lessons learned
Firstly, we learned that the awesome power of the SHIELD platform allows us to deploy large-scale studies seamlessly in the release population. It was a great experience to deploy a Firefox service via SHIELD in this manner.
A slightly harder lesson, is that clients’ attention is very difficult to steer. Of the 1.2 million users initially enrolled in this study a mere 3.5% interacted specifically with the TAAR library during the study period. Perhaps more obvious signaling could be considered, but we also wanted to avoid disruptive or overly aggressive disruption of the default Firefox user experience.
In addition we found that clients are very polarized in terms of how they like to interact with the add-ons ecosystem. Only around 12% of clients interacting (not necessarily leading to an add-on installation) with the add-on ecosystem were observed to visit both about:addons and addons.mozilla.org; meaning that ~88% of users exclusively interested with one of those two locations, perhaps indicating that many users are not aware of the two channels by which the AMO servers can be reached.
In conjunction with the TAAR study, we have continued to tinker with the TAAR library as a project in active development. Our initial predictions regarding client eligibility for each of the recommendation modules proved to be pretty close to the mark. But an interesting discovery was that in the live add-ons ecosystem, interacting with real clients the modules exhibit differences in their likely recommendations.
Future directions
We learned several valuable lessons in the first TAAR study. But we also were forced to think about the efficacy of the recommendations in a very pragmatic manner. In terms of maximizing the rate of installation we are tempted to recommend the (globally) most popular add-ons, especially to new users. However, showing only the most popular add-ons can reinforce a polarized ecosystem where it is nearly impossible for new add-ons to thrive. We aim to do better; we believe that delivering less generic recommendations could be more helpful to our users as these add-ons are better tailored to their experiences.
We also have been busy with analyzing the correlations in the feature spaces leveraged by the individual TAAR modules. While the telemetry space is full of correlations and latent relationships, we believe that the reduced space operated on by the four main recommendations modules (excluding locale-recommender) exhibit sufficient statistical independence that a linear ensemble recommendation strategy could be very helpful. Also, taking a peek at older, more established client profiles, we think that the additional and independent information provided by the similarity based recommender can help to refine the already great recommendation list provided by collaborative filtering. Likewise, information regarding now disabled legacy extensions can be very useful in provided recommended substitutes. The next version of TAAR will utilize a linear stacked ensemble learner in lieu of the current recommendation manager module.
Additional improvements currently in development and planned for TAAR are as follows:
- better integration of AMO information sources in generating recommendations, including ratings, download rates, uninstall rates, add-on metadata;
- the combination of individual recommendation modules in an ensemble;
- new parallelized execution of the individual TAAR modules;
- back-end optimizations to reduce end-to-end latency of the TAAR web service.
Look forward to the follow-up studies scheduled to evaluate our latest improvements to the TAAR library in early 2018.
And as always… thanks to all the Firefox users out there for continuing to take part to SHIELD studies, helping us improve Firefox every day. Th single Firefox user who continues to trust us with their data by enabling extended telemetry. And to all the Firefox Pioneers who’s contribution of extended data collection allows us to do the best job we can at exploring and refining Firefox features!
No comments yet
Comments are closed, but trackbacks are open.