(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
This week in Glean, we bring you a detective story from the Mozilla telemetry beat. It’s a story about how fixing things can often break things in unexpected ways. It’s about how things that may work perfectly in the lab, suddenly fail in the wild at scale. And it’s about how our team used all of the data sources at our disposal to solve a problem.
Glean is a new effort at Mozilla to collect telemetry based on lessons from our past experiences that can be used across a number of our products and better support our lean data practices. It is currently being used to collect telemetry from Firefox Preview for Android, but will be rolling out to more Mozilla products in the coming months.
When using Firefox Preview, the browser makes measurements (or telemetry) about its usage and how it’s performing. Users can choose to disable telemetry if they prefer, however the data from the rest provides us with key insights that allow us to build stable and performant products that meet the needs of our users. This telemetry is periodically sent to Mozilla in bundles called “pings“, all of which is orchestrated on Firefox’s behalf by the Glean SDK.
The Glean SDK sends a few different kinds of pings, but the two that are relevant to our story are the metrics ping and baseline ping. The metrics ping is sent once a day at 04:00 local time, if the user used the application in the last 24 hours. The baseline ping contains minimal data, but is sent more often: every time the application “goes to background”. This happens when the user switches to another application or the device goes to sleep. Given how people normally use their smartphones, the browser “goes to background” a few times a day, so one would expect to see baseline pings occuring more often than metrics pings.
Not long after the release of Firefox Preview, we noticed that we were getting a metrics ping every 24 hours from each user, even if they hadn’t used the browser during that period. This wastes bandwidth, both for us and our users, since there’s no need to send data if there haven’t been any changes.
The bug was happening because every time Glean sent a metrics ping at 4am, it would just go ahead and schedule the next one to be sent 24 hours later. Android doesn’t provide a lot of good options to solve this problem. The solution we arrived at is that Glean would schedule the ping for the next 04:00 only if the user is actually using the application at the time. If they aren’t using it, we’ll just check the next time the user opens the app, and schedule it for the following 04:00 at that time. Android provides an API that can tell our app when the app goes to foreground and background (among other things) called the “LifecycleObserver API“. Using that bit of information, Glean can know when the user is using the app and schedule our next metrics ping accordingly.
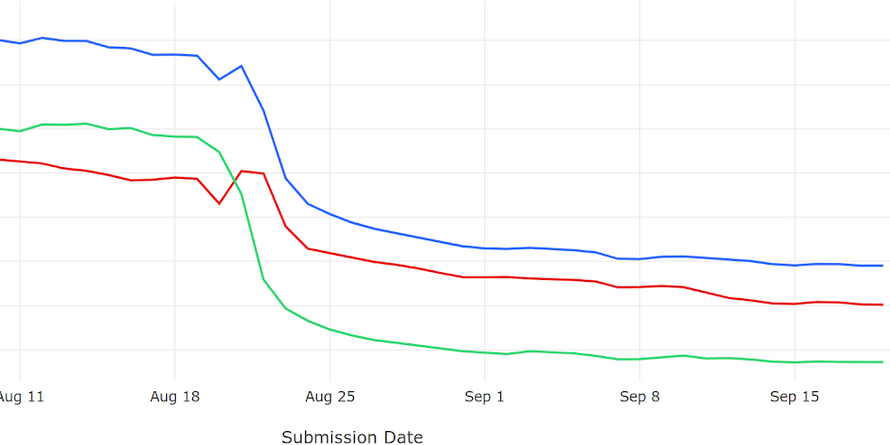
We merged this fix, feeling we had squashed that bug and moved on. But our jaws dropped when we saw the following graph:
The graph shows the number of clients that sent a baseline ping (green), metrics ping (red) or both a baseline and metrics ping (blue). Around August 20, when we fixed that bug, the number of metrics pings went down (as expected), but the number of baseline pings went down even more, such that there were now fewer baseline pings than metrics pings. How could that possibly be?
We scratched our heads for a few days over this, methodically looking over of the other changes that occurred during that timeframe that may have caused this strange outcome in the data. One by one, all other options were eliminated until all signs pointed to that “fix” for the metrics ping. But understanding how that fix could be connected to this behavior remained elusive.
It turned out the answer lay hidden in our crash data. In addition to the Glean telemetry, Firefox Preview uses Sentry to collect reports about application crashes. These reports contain “backtraces”, or specific information about where in the code the crash occurred. For some time, we had seen crash reports that pointed at Android’s Lifecycle Observer API, but they were of such low frequency that we hadn’t invested the effort to investigate further. Around the time of the “fix” however, there was an uptick in these kinds of crashes.
It turns out the Lifecycle Observer API has an undocumented limitation that it wasn’t designed to be called in the way we were calling it (off of the main thread of execution). This caused the Lifecycle Observer to randomly fail, but only sometimes, and only for a fraction of users in the wild. I, personally, have never been able to reproduce the behavior — we know about it only because Firefox Preview is running on thousands of devices in the world at large and they report back through Sentry.
When the Lifecycle Observer does fail, two interesting things happen in tandem:
- For the metrics ping, Glean no longer knows when the application is being used, so it sends the metrics ping more often than it should.
- The baseline ping is triggered directly from the Lifecycle Observer when the application goes to background. So when the Lifecycle Observer fails, Glean sends the baseline ping less often than we should.
These two things in combination are what caused the red and green lines to cross and the fabric of space-time to become unraveled. The culprit is most likely that the fix added a second use of the Lifecycle Observer to the application: it was now being used both to handle the metrics ping and the baseline ping. Using it twice (and potentially concurrently) was enough to push a long latent crash problem into the monster that ate our data.
These sorts of puzzles can be very frustrating until they reveal themselves. Having a great team to brainstorm hypotheses with, and a common mission to find a “cause” without a “blame” is incredibly valuable. Thanks to everyone on the Glean team: Alessio Placitelli, Travis Long, Jan-Erik Rediger, Georg Fritzsche, Chris Hutten-Czapski and Beatriz Rizental.
Join us next week. Who knows what we’ll find in the icy fjords of Glean land…
(( This is a syndicated copy of the original post. ))