(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
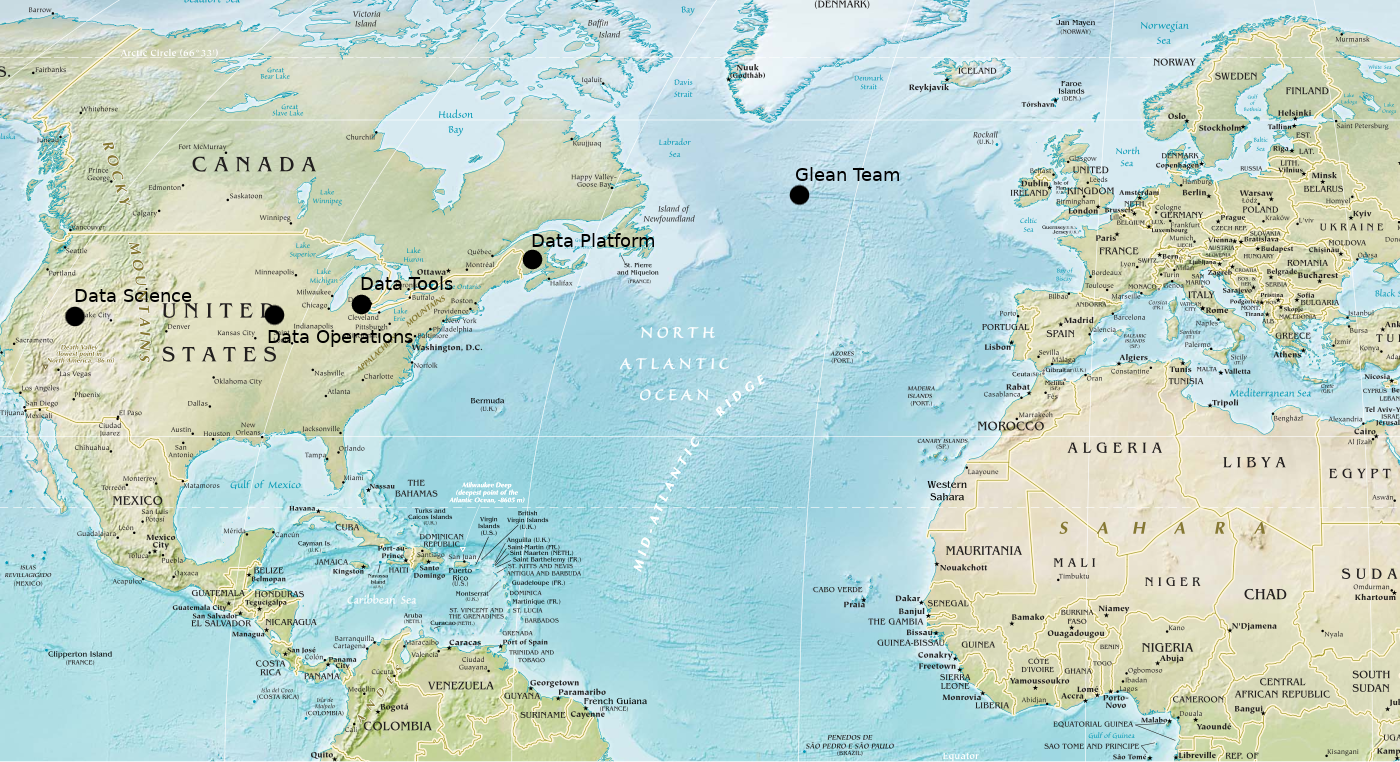
I was recently struck by a realization that the position of our data org’s team members around the globe mimics the path that data flows through the Glean Ecosystem.
Glean Data takes this five-fold path (corresponding to five teams):
- Data is collected in a client using the Glean SDK (Glean Team)
- Data is transmitted to the Structured Ingestion pipeline (Data Platform)
- Data is stored and maintained in our infrastructure (Data Operations)
- Data is presented in our tools (Data Tools)
- Data is analyzed and reported on (Data Science)
The geographical midpoint of the Glean Team is about halfway across the north atlantic. For Data Platform it’s on the continental US, anchored by three members in the midwestern US. Data Ops is further West still, with four members in the Pacific timezone and no Europeans. Data Tools breaks the trend by being a bit further East, with fewer westcoasters. Data Science (for Firefox) is centred farther west still, with only two members East of the Rocky Mountains.
Or, graphically:

Given the rotation of the Earth, the sun rises first on the Glean Team and the data collected by the Glean SDK. Then the data and the sun move West to the Data Platform where it is ingested. Data Tools gets the data from the Platform as morning breaks over Detroit. Data Operations keeps it all running from the midwest. And finally, the West Coast Centre of Firefox Data Science Excellence greets the data from a mountaintop, to try and make sense of it all.
(( Lying orthogonal to the data organization is the secret Sixth Glean Data “Team”: Data Stewardship. They ensure all Glean Data is collected in accordance with Mozilla’s Privacy Promise. The sun never sets on the Stewardship’s global coverage, and it’s a volunteer effort supplied from eight teams (and growing!), so I’ve omitted them from this narrative. ))
Bad metaphors about sunlight aside, I wonder whether this is random or whether this is some sort of emergent behaviour.
Conway’s Law suggests that our system architecture will tend to reflect our orgchart (well, the law is a bit more explicit about “communication structure” independent of organizational structure, but in the data org’s case they’re pretty close). Maybe this is a specific example of that: data architecture as a reflection of orgchart geography.
Or perhaps five dots on a globe that are only mostly in some order is too weak of a coincidence to even bear thinking about? Nah, where’s the blog post in that thinking…
If it’s emergent, it then becomes interesting to consider the “chicken and egg” point of view: did the organization beget the system or the system beget the organization? When I joined Mozilla some of these teams didn’t exist. Some of them only kinda existed within other parts of the company. So is the situation we’re in today a formalization by us of a structure that mirrors the system we’re building, or did we build the system in this way because of the structure we already had?
:chutten
(( This is a syndicated copy of the original post. ))