
It all started rather inconspicuous: The Data Engineering team filed a bug report about a sudden increase in schema errors at ingestion of telemetry data from Firefox for Android. At that point in time about 0.9% of all incoming pings were not passing our schema validation checks.
The data we were seeing was surprising. Our ingestion endpoint received valid JSON that contained snippets like this:
{
"metrics": {
"schema: counter": {
"glean.validation.pings_submitted": {
"events": 1
}
},
...
},
...
}What we would expect and would pass our schema validation is this:
{
"metrics": {
"labeled_counter": {
"glean.validation.pings_submitted": {
"events": 1
}
},
...
},
...
}The difference? 8 characters:
- "schema: counter": {
+ "labeled_counter": {8 different characters that still make up valid JSON, but break validation.
A week later the number of errors kept increasing, affecting up to 2% of all ingested pings from Firefox for Android Beta. That’s worryingly high. That’s enough to drop other work and call an incident.
Aside: Telemetry ingestion
In Firefox the data is collected using the Glean SDK. Data is stored in a local database and eventually assembled into what we call a ping: A bundle of related metrics, gathered in a JSON payload to be transmitted. This JSON document is then POSTed to the Telemetry edge server. From there the decoder eventually picks it up and processes it further. One of the early things it does is verify the received data against one of the pre-defined schemas. When data is coming from the Glean SDK it must pass the pre-defined glean.1.schema.json. This essentially describes which fields to expect in the nested JSON object. One thing it is expecting is a labeled_counter A thing it is NOT expecting is schema: counter. In fact
keys other than the listed ones are forbidden.
The missing schema:_
The data we were receiving from a growing number of clients contained 8 bytes that we didn’t expect in that place: schema: . That 8-character string didn’t even show up in the Glean SDK source code. Where does it come from? Why was it showing up now?
We did receive entirely valid JSON, so it’s unlikely to be simple memory corruption1. More like memory confusion, if that’s a thing.
We know where the payload is constructed. The nested object for labeled metrics is constructed in its own function. It starts with string formatting:
let ping_section = format!("labeled_{}", metric.ping_section());There’s our 8-character string labeled_ that gets swapped. The Glean SDK is embedded into Firefox inside mozilla-central and compiled with all the other code together. A single candidate for the schema: string exists in that codebase. That’s another clue it could be memory confusion.
My schema? Confused.
I don’t know much about how string formatting in Rust works under the hood, but luckily Mara blogged about it 2 years ago: Behind the Scenes of Rust String Formatting: format_args!() (and then recently improved the implementation2).
So the format! from above expands into something like this:
std::io::_format(
// Simplified expansion of format_args!():
std::fmt::Arguments {
template: &[Str("labeled_ "), Arg(0)],
arguments: &[&metric.ping_section() as &dyn Display],
}
);Another clue that the labeled_ string is referenced all by itself and swapping out the pointer to it would be enough to lead to the corrupted data we were seeing.
Architecturing more clues
Whenever we’re faced with data anomalies we start by dissecting the data to figure out if the anomalies are from a particular subset of clients. The hope is that identifying the subset of clients where it happens gives us more clues about the bug itself.
After initially focusing too much on actual devices colleagues helpfully pointed out that the actual split was the device’s architecture3:
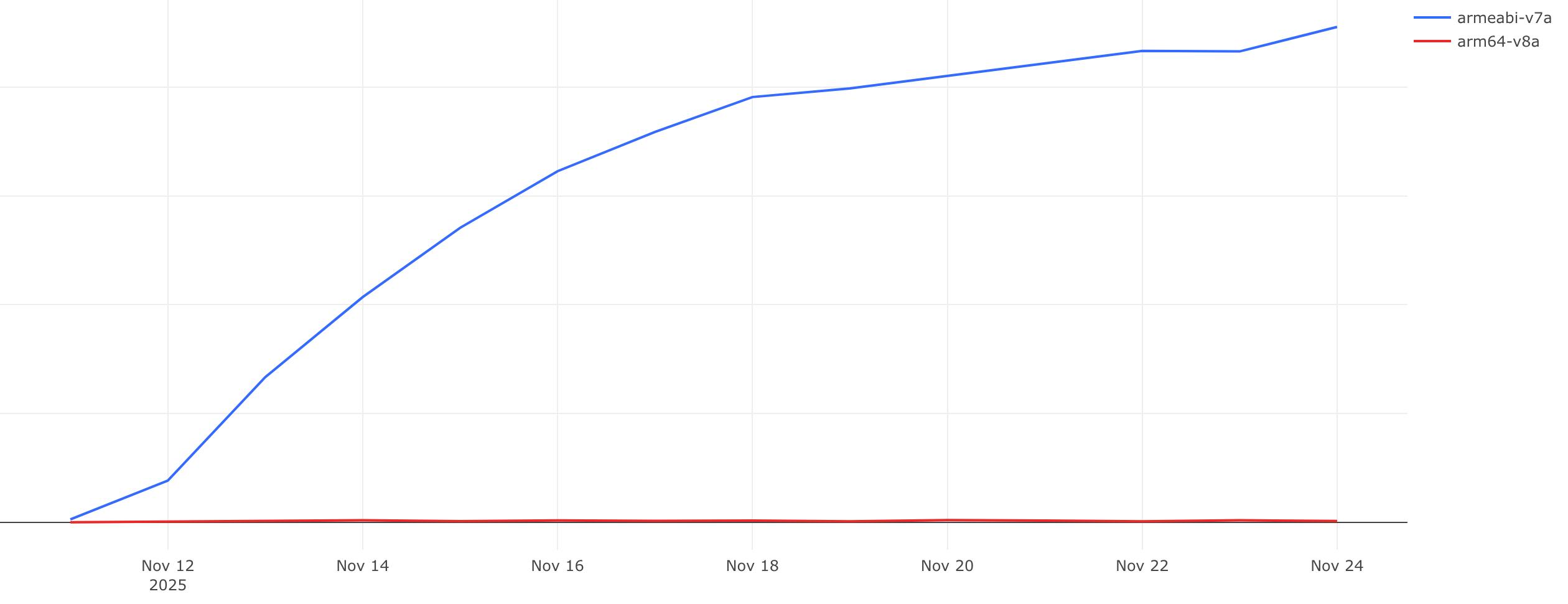
Data since 2025-11-11 showing a sharp increase in errors for armeabi-v7a clients
ARMv8, the 64-bit architecture, did not run into this issue4. ARMv7, purely 32-bit, was the sole driver of this data anomaly. Another clue that something in the code specifically for this architecture was causing this.
Logically unchanged
With a hypothesis what was happening, but no definite answer why, we went to speculative engineering: Let’s avoid the code path that we think is problematic.
By explicitly listing out the different strings we want to have in the JSON payload we avoid the formatting and thus hopefully any memory confusion.
let ping_section = match metric.ping_section() {
"boolean" => "labeled_boolean".to_string(),
"counter" => "labeled_counter".to_string(),
// <snip>
_ => format!("labeled_{}", metric.ping_section()),
};This was implemented in 912fc80 and shipped in Glean v66.1.2. It landed in Firefox the same day of the SDK release and made it to Firefox for Android Beta the Friday after. The data shows: It’s working, no more memory confusion!
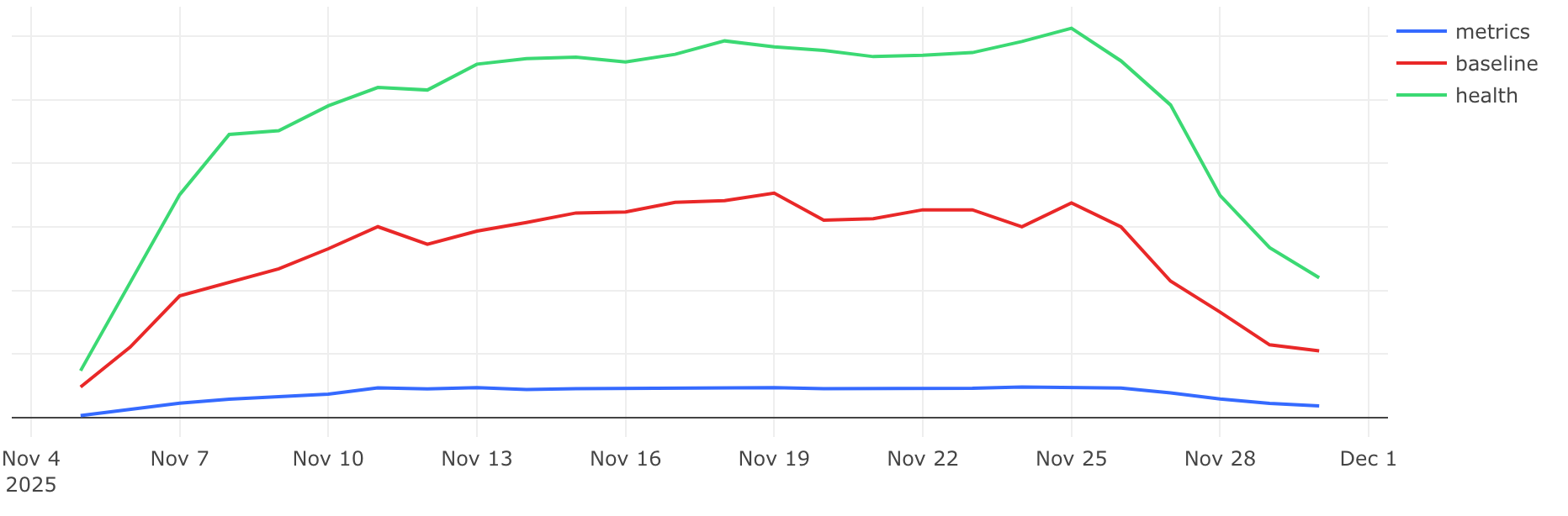
The number of errors have been on a downturn ever since the fix landed on 2025-11-26
A bug gone but still there
The immediate incident-causing data anomaly was mitigated, the bug is not making it to the Firefox 146 release.
But we still didn’t know why this was happening in the first place. My colleagues Yannis and Serge kept working and searching and were finally able to track down what exactly is happening in the code. The bug contains more information on the investigation.
While I was trying to read and understand the disassembly of the broken builds, they went ahead and wrote a tiny emulator (based on the Unicorn engine) that runs just enough of the code to find the offending code path5.
> python ./emulator.py libxul.so
Path: libxul.so
GNU build id: 1b9e9c8f439b649244c7b3acf649d1f33200f441
Symbol server ID: 8F9C9E1B9B43926444C7B3ACF649D1F30
Please wait, downloading symbols from: https://symbols.mozilla.org/try/libxul.so/8F9C9E1B9B43926444C7B3ACF649D1F30/libxul.so.sym
Please wait, uncompressing symbols...
Please wait, processing symbols...
Proceeding to emulation.
Result of emulation: bytearray(b'schema: ')
This is a BAD build.The relevant section of the code boils down to this:
ldr r3, [pc, #0x20c]
add r3, pc
strd r3, r0, [sp, #0xd0]
add r1, sp, #0xd0
bl alloc::fmt::format_innerThe first two instructions build the pointer to the slice in r3, by using a pc-relative offset found in a nearby constant. Then we store that pointer at
sp+0xd0, and we put the addresssp+0xd0intor1. So before we reachalloc::fmt::format_inner,r1points to a stack location that contains a pointer to the slice of interest. The slice lives in.data.rel.roand contains a pointer to the string, and the length of the string (8). The string itself lives in.rodata.
In good builds the .rodata r3 points to looks like this:
0x06f0c3d4: 0x005dac18 --> "labeled_"
0x06f0c3d8: 0x8
0x06f0c3dc: 0x0185d707 --> "/builds/<snip>/rust/glean-core/src/storage/mod.rs"
0x06f0c3e0: 0x4dIn bad builds however it points to something that has our dreaded schema: string:
0x06d651c8: 0x010aa2e8 --> "schema: "
0x06d651cc: 0x8
0x06d651d0: 0x01a869a7 --> "maintenance: "
0x06d651d4: 0xd
0x06d651d8: 0x01a869b4 --> "storage dir: "
0x06d651dc: 0xd
0x06d651e0: 0x01a869c8 --> "from variant of type "
0x06d651e4: 0x15
0x06d651e8: 0x017f793c --> ": "
0x06d651ec: 0x2This confirms the suspicion that it’s a compiler/linker bug. Now the question was how to fix that.
Firefox builds with a variety of Clang/LLVM versions. Mozilla uses its own build of LLVM and Clang to build the final applications, the exact version used is updated as soon as possible, but never on release. Sometimes additional patches are applied on top of the Clang release, like some backports fixing other compiler bugs.
After identifying that this is indeed a bug in the linker and that it has already been patched in later LLVM versions, Serge did all the work to bisect the LLVM release to find which patches to apply to Mozilla’s own Clang build. Ultimately he tracked it down to these two patches for LLVM:
- [InstCombine] Don’t handle non-canonical index type in icmp of load fold
- [InstCombine] Make foldCmpLoadFromIndexedGlobal more resiliant to non-array geps.
With those patches applied, the old code, without our small code rearrangement, does not lead to broken builds anymore.
With the Glean code patched, the ingestion errors dropping and the certainty that we have identified and patched the compiler bug, we can safely ship the next release of Firefox (for Android).
Collaboration
Incidents are stressful situations, but a great place for collaboration across the whole company. The number of people involved in resolving this is long.
Thanks to Eduardo & Ben from Data Engineering for raising the issue.
Thanks to Alessio (my manager) for managing the incident.
Thanks to chutten and Travis (from my team) for brainstorming what caused this and suggesting solutions/workarounds.
Thanks to Donal (Release Management) for fast-tracking the mitigation into a Beta release.
Thanks to Alex (Release Engineering) for some initial investigation into the linker bug.
Thanks to Brad (Data Science) for handling the data analysis side.
Thanks to Yannis and Serge (OS integration) for identifying, finding and patching the linker bug.
Footnotes:
- Memory corruption is never “simple”. But if it were memory corruption I would expect data to be broken worse or in other places too. Not just a string swap in a single place.↩︎
- That improvement is not yet available to us. The application experiencing the issue was compiled using Rust 1.86.0.↩︎
- Our checklist initially omitted architecture. A mistake we since fixed.↩︎
- Apparently we do see some errors, but they are so infrequent that we can ignore them for now.↩︎
- Later Yannis wrote a script that can identify broken builds purely much quicker, just by searching for the right string patterns.↩︎