Speeding up Firefox Local AI Runtime
Last year we rolled out the Firefox AI Runtime, the engine that quietly powers features such as PDF.js generated alt text and, more recently, our smart tab grouping. The system worked, but not quite at the speed we wanted.
This post explains how we accelerated inference by replacing the default onnxruntime‑web that powers Transformers.js with its native C++ counterpart that now lives inside Firefox.
Where we started
Transformers.js is the JavaScript counterpart to Hugging Face’s Python library. Under the hood it relies on onnxruntime‑web, a WebAssembly (WASM) build of ONNX Runtime.
A typical inference cycle:
- Pre‑processing in JavaScript (tokenization, tensor shaping)
- Model execution in WASM
- Post‑processing back in JavaScript
Even with warm caches, that dance crosses multiple layers. The real hotspot is the matrix multiplications, implemented with generic SIMD when running on CPU.
Why plain WASM wasn’t enough
WASM SIMD is great, but it can’t beat hardware‑specific instructions such as NEON on Apple Silicon or AVX‑512 on modern Intel chips.
Firefox Translations (uses Bergamot) already proves that diving to native code speeds things up: it uses WASM built‑ins which are small hooks that let WASM call into C++ compiled with those intrinsics. The project, nicknamed gemmology, works brilliantly.
We tried porting that trick to ONNX, but the huge number of operators made a one‑by‑one rewrite unmaintainable. And each cold start still paid the JS/WASM warm‑up tax.
Switching to ONNX C++
Transformers.js talks to ONNX Runtime through a tiny surface. It creates a session, pushes a Tensor, and pulls a result. It makes it simple to swap the backend without touching feature code.
Our steps to achieve this were:
- Vendor ONNX Runtime C++ directly into the Firefox tree.
- Expose it to JavaScript via a thin WebIDL layer.
- Wire Transformers.js to the new backend.
From the perspective of a feature like PDF alt‑text, nothing changed, it still calls await pipeline(…). Underneath, tensors now go straight to native code.
Integration of ONNX Runtime to the build system
Upstream ONNX runtime does not support all of our build configuration, and it’s a large amount of code. As a consequence we chose not to add it in-tree. Instead, a configuration flag can be used to provide a compiled version of the ONNX runtime. It is eventually automatically downloaded from Taskcluster (where we build it for a selection of supported configuration) or provided by downstream developers. This provides flexibility while not slowing down our usual build and requiring low maintenance.
Building ONNX on Taskcluster required some configuration changes and upstream patches. The goal was to find a balance between speed and binary size, while being compatible with native code requirements from the Firefox repo.
Most notably:
- Building without exception and RTTI support required some patches upstream
- Default build configuration is set to MinSizeRel, compilation uses LTO
The payoff
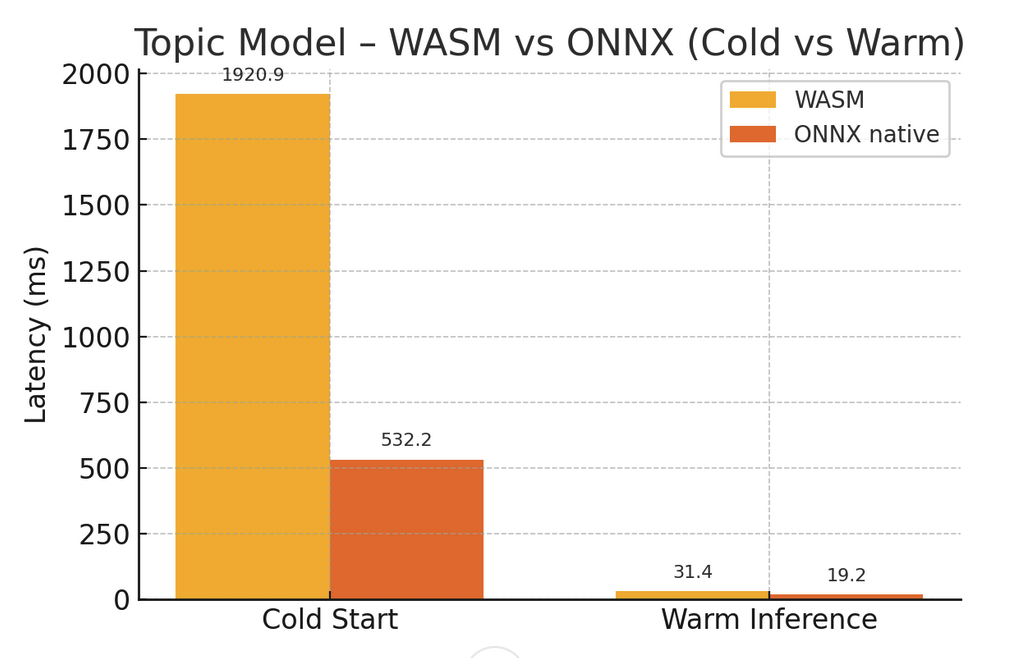
Because the native backend is a drop‑in replacement, we can enable it feature by feature and gather real‑world numbers. Early benchmarks shows from 2 to 10 × faster inference, with zero WASM warm‑up overhead.
For example, the Smart Tab Grouping topic suggestion, which can be laggy on first run, is now quite snappy, and this is the first feature we gradually moved to this backend for Firefox 142.
The image to text model used for PDF.js alt-text feature also benefited from this change. On the same hardware the latency went from from 3.5s to 350ms.
What’s next
We’re gradually rolling out this new backend to additional features throughout the summer, so all capabilities built on Transformers.js can take advantage of it.
And with the C++ API at hand, we’re planning to tackle a few long‑standing pain points, and enable GPU.
Those changes will ship in our vendored ONNX Runtime and offer us the best possible performance for Transformers.js-based features in our runtime in the future.
1. DequantizeLinear goes multi‑threaded
The DequantizeLinear operation is single‑threaded and often dominated inference time. While upstream work recently merged an improvement (PR #24818), we built a patch to spread the work across cores, letting the compiler auto‑vectorize the inner loops. The result is an almost linear speedup, especially on machines with many cores.
2. Matrix transposition goes multi-threaded
Similarly, it is typical to have to transpose very large (multiple dozen megabytes) matrices when performing an inference task. This operation was done naively with nested for loops. Switching to a multi-threaded cache-aware tiled transposition scheme, and leveraging SIMD allowed to take advantage of modern hardware and speed up this operation by a supra-linear factor, typically twice the number of threads allocated to this task, for example a 8x speedup using 4 threads.
This can be explained by the fact that the naive for loop was auto-vectorized, but otherwise did poor usage of CPU caches.
3. Caching the compiled graph
Before an inference can run, ONNX Runtime compiles the model graph for the current platform. On large models such as Qwen 2.5 0.5B this can cost up to five seconds every launch.
We can cache the compiled graph separately from the weights on the fly, shaving anywhere from a few milliseconds to the full five seconds.
4. Using GPUs
Currently, we’ve integrated only CPU-based providers. The next step is to support GPU-accelerated ONNX backends, which will require more effort. This is because GPU support demands additional sandboxing to safely and securely interact with the underlying hardware.
Conclusion
What is interesting about this migration is the fact that we could improve performance that much, while migrating features gradually, and all that in complete isolation, without having to change any feature code.
While the speed ups are already visible from a UX standpoint, we believe that a lot of improvement can and will happen in the future, further improving the efficiency of the ML-based features, and making them more accessible to a wider audience.
Have ideas, questions or bug reports? Ping us on Discord in the firefox-ai channel (https://discord.gg/TBZXDKnz) or file an issue on Bugzilla, we’re all ears.