Today we are excited to announce that Common Voice, Mozilla’s initiative to crowdsource a large dataset of human voices for use in speech technology, is going multilingual! Thanks to the tremendous efforts from Mozilla’s communities and our deeply engaged language partners you can now donate your voice in German, French and Welsh, and we are working to launch 40+ more as we speak. But this is just the beginning. We want Common Voice to be a tool for any community to make speech technology available in their own language.
Since we launched Common Voice last July, we have collected hundreds of thousands of voice samples in English through our website and iOS app. Last November, we published the first version of the Common Voice dataset. This data has been downloaded thousands of times, and we have seen the data being used in commercial voice products as well as open-source software like Kaldi and our very own speech recognition engine, project Deep Speech.
Up until now, Common Voice has only been available for voice contributions in English. But the goal of Common Voice has always been to support many languages so that we may fulfil our vision of making speech technology more open, accessible, and inclusive for everyone. That is why our main effort these last few months has been around growing and empowering individual language communities to launch Common Voice in their parts of the world, in their local languages and dialects.
In addition to localising the website, these communities are populating Common Voice with copyright-free sentences for people to read that have the required characteristics for a high quality dataset. They are also helping promote the site in their countries, building a community of contributors with the goal of growing the total hours of collected data available in each language.
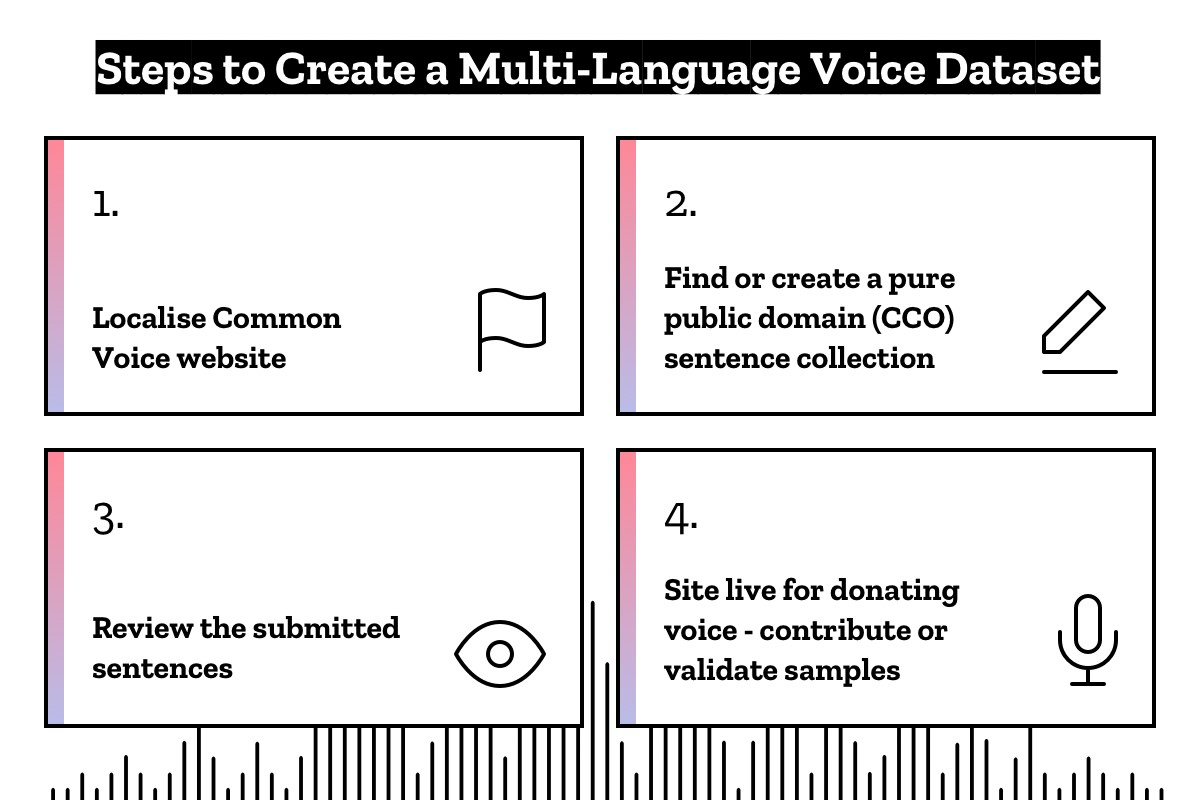
Adding to English, we are now collecting voice samples in French, German and Welsh. And there are already more than 40 other languages on the way – not only big languages like Spanish, Chinese or Russian, but also smaller ones like Frysian, Norwegian or Chuvash. For us, these smaller languages are important because they are often under-served by existing commercial digital and speech recognition services. Having data available can empower entrepreneurs and communities to address this gap on their own.
Going multilingual marks a big step for Common Voice and we hope that it’s also a big step for speech technology in general. Democratizing voice technology will not only lower the barrier for global innovation, but also the barrier for access to information. Especially so for people who traditionally have had less of this access — for example, vision impaired, people who never learned to read, children, the elderly and many others.
We are thrilled to see the growing support we are getting to build the world’s largest public multi-language voice dataset and everyone can help us grow it by donating your voice. You can also use the iOS app. If you would like to help bring Common Voice and speech technology to your language, visit our language page. And if you are part of an organisation and have an idea for participating in this project, please get in touch.
Our Forum gives more details on how to help, as well as being a great place to ask questions and meet the communities.
Special Thanks
We would like to thank our Speech Advisory Group, people who have been expert advisors and contributors to the Common Voice project:
- Francis Tyers – Assistant Professor of Computational Linguistics at Higher School of Economics in Moscow.
- Gilles Adda – Speech scientist
- Thomas Griffiths – Digital Services Officer, Office of the Legislative Assembly, Australia
- Joshua Meyer – PhD candidate in Speech Recognition
- Delyth Prys – Language technologies at Bangor University research centre.
- Dewi Bryn Jones – Language technologies at Bangor University research centre.
- Wael Farhan – MS in Machine Learning from UCSD, currently doing research for Arabic NLP at Mawdoo3.com.
- Eren Gölge – Machine learning scientist currently working on TTS for Mozilla.
- Alaa Saade – Senior Machine Learning Scientist @ Snips (Paris)
- Laurent Besacier – Professor at Université Grenoble Alpes, NLP, speech processing, low resource languages
- David van Leeuwen – Speech Technologist
- Benjamin Milde – PhD candidate in NLP/speech processing
- Shay Palachy – M.Sc. in Computer Science, Lead Data Scientist in a startup
***
Common Voice complements Mozilla’s work in the field of speech recognition, which runs under the project name “Deep Speech“, an open-source speech recognition engine model that approaches human accuracy, which was released in November 2017. Together with the growing Common Voice dataset we believe this technology can and will enable a wave of innovative products and services, and that it should be available to everyone.
–
More Common Voices (Welsh)
Rhagor o Leisiau i Common Voice
Heddiw mae’n bleser gennym gyhoeddi fod Common Voice, menter Mozilla i dorfoli set ddata fawr o leisiau dynol ar gyfer eu defnyddio mewn technoleg lleferydd, yn mynd yn mynd i fod ar gael ar gyfer nier o ieithoedd! Diolch i ymdrechion glew cymunedau lleoleiddio Mozilla a’n partneriaid iaith ymrwymedig gallwch nawr gyfrannu eich llais mewn Cymraeg, Almaeneg a Ffrangeg, ac rydym yn gweithio i lansio 40+ yn ychwanegol cyn bo hir. Ond dim ond y dechrau yw hyn. Rydym eisiau i Common Voice fod yn arf ar gyfer unrhyw gymuned i greu technoleg lleferydd yn eu hiaith eu hun.

Ers i ni lansio Common Voice fis Gorffennaf diwethaf, rydym wedi casglu cannoedd o filoedd o samplau llais yn Saesneg drwy ein gwefan ac ap iOS. Fis Tachwedd y llynedd, fe wnaethom ni gyhoeddi fersiwn cyntaf set ddata Common Voice. Mae’r data hyn wedi cael eu llwytho lawr fileodd o weithiau, ac rydym wedi gweld y data yn cael eu defnyddio mewn cynnyrch llais masnachol fel Kaldi yn ogystal â’n meddalwedd cod agored ni ein hunain, Deep Speech.
Hyd yn hyn, mae Common Voice wedi bod ar gael dim ond ar gyfer cyfraniadau llais yn Saesneg. Ond nod Common Voice o’r dechrau oedd cefnogi llawer o ieithoedd er mwyn gwireddu ein gweledigaeth o wneud technoleg lleferydd yn fwy agored, hygyrch a chynhwysol i bawb. Dyna pam fod ein prif ymdrechion yn ystod y misoedd diwethaf wedi canolbwyntio ar dyfu a grymuso cymunedau iaith unigol i lansio Common Voice yn eu rhannau nhw o’r byd, yn eu hieithoedd a’u tafodieithoedd eu hunain.
Yn ychwanegol at leoleiddio’r wefan, mae’r cymunedau hyn yn helpu poblogi Common Voice gyda brawddegau i bobl eu darllen. Mae’r brawddegau hyn yn rhydd o hawlfraint, ac mae ganddyn nhw’r nodweddion cywir i greu set ddata o safon uchel. Mae’r cymunedau hyn hefyd yn helpu hyrwyddo’r wefan yn eu gwledydd eu hunain, gan adeiladu cymuned o gyfranwyr gyda’r nod o dyfu’r cyfanswm o oriau o ddata sydd wedi’u casglu ac sydd ar gael ym mhob iaith.
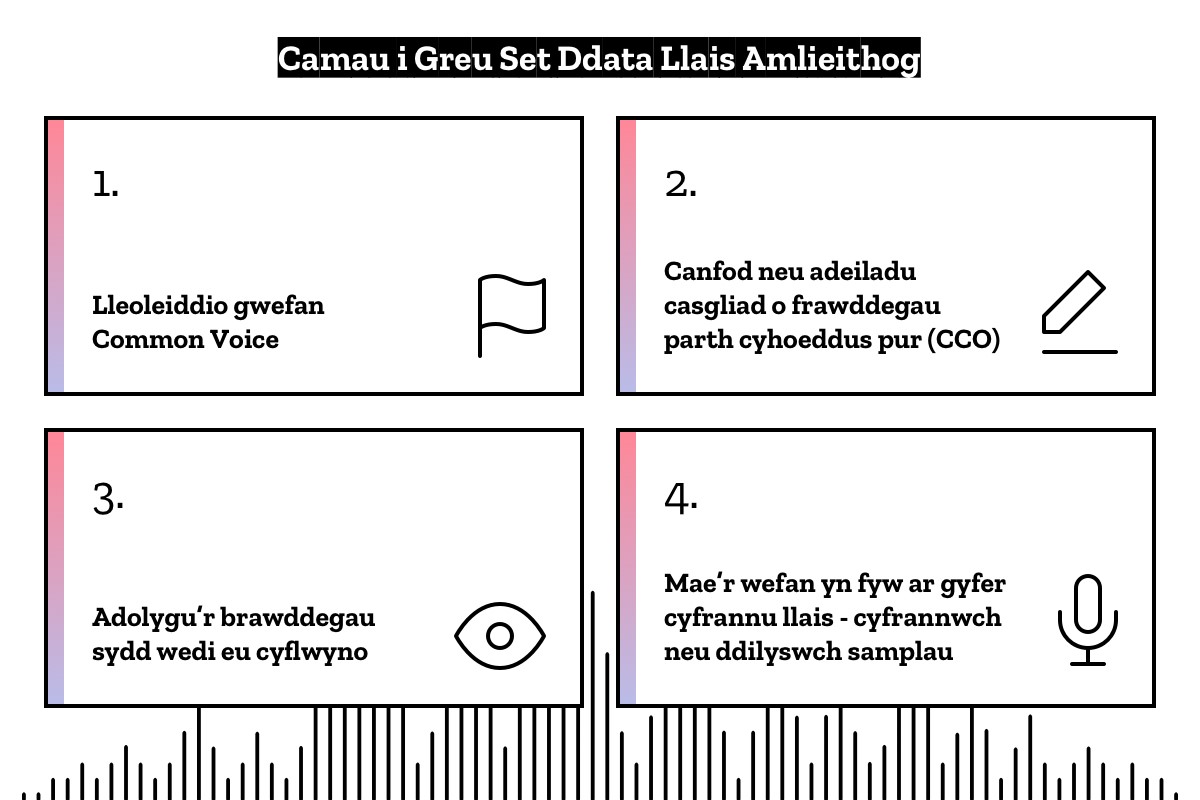
Yn ychwanegol at Saesneg, rydym nawr yn casglu samplau llais mewn Cymraeg, Ffrangeg ac Almaeneg. Ac mae mwy na 40 iaith arall eisoes ar y ffordd – nid dim ond ieithoedd mawr fel Sbaeneg, Tseineeg neu Rwsieg, ond hefyd ieithoedd llai fel Ffriseg, Norwyeg neu Chuvash. I ni, mae’r ieithoedd llai hyn yn bwysig oherwydd eu bod nhw yn aml heb gael digon o sylw gan y gwasanaethau adnabod lleferydd a digidol masnachol presennol. Gall bodolaeth data addas hefyd rymuso entrepreneuriaid a chymunedau i lenwi’r bwlch hwn eu hunain.
Mae mynd yn amlieithog yn gam mawr i Common Voice a gobeithiwn ei fod hefyd yn gam mawr i dechnoleg lleferydd yn gyffredinol. Bydd democrateiddio technoleg lleferydd nid yn unig yn lleihau’r rhwystr sy’n atal arloesedd byd-eang ond hefyd y rhwystr sy’n atal pobl rhag cael mynediad at y wybodaeth. Yn arbennig felly pobl sydd yn draddodiadol wedi cael llai o fynediad — er enghraifft, pobl â nam ar eu golwg, pobl na wnaeth erioed ddysgu darllen, plant, pobl hŷn, a llawer eraill.
Rydym yn falch iawn o weld y gefnogaeth gynyddol sydd i ni adeiladu’r set ddata amlieithog gyhoeddus fwyaf yn y byd, a gall pawb ein helpu i’w dyfu drwy gyfrannu eich llais. Os hoffech chi helpu i ddod â Common Voice a thechnoleg lleferydd i’ch iaith chi, ewch i’n tudalen iaith. Ac os ydych yn rhan o sefydliad a bod gennych syniad ar gyfer cymryd rhan yn y project hwn, cysylltwch â ni.
Mae ein Fforwm yn rhoi mwy o fanylion ar sut i helpu, yn ogystal â bod yn lle gwych i ofyn cwestiynau a chyfarfod â’r cymunedau.
Diolch Arbennig
Hoffem ddiolch i’n Grŵp Ymgynghorol Lleferydd, pobl sydd wedi bod yn gyfranwyr ac yn ymgynghowyr arbenigol i’r project Common Voice:
- Francis Tyers – Athro Cynorthwyol Ieithyddiaeth Gyfrifiadurol yn yr Ysgol Economeg Uwch yn Moscow.
- Gilles Adda – Gwyddonydd lleferydd
- Thomas Griffiths – Swyddog Gwasanaethau Digidol, Swyddfa’r Cynulliad Deddfwriaethol, Awstralia
- Joshua Meyer – ymgeisydd PhD mewn Adnabod Lleferydd
- Delyth Prys – Pennaeth Uned Technolegau Iaith, Prifysgol Bangor, Cymru
- Dewi Bryn Jones – Prif Beiriannydd Meddalwedd, Uned Technolegau Iaith, Prifysgol Bangor, Cymru
- Wael Farhan – MS mewn Dysgu Peiriant o UCSD, ar hyn o bryd yn gwneud ymchwil ar gyfer NLP Arabeg yn Mawdoo3.com.
- Eren Gölge – Gwyddonydd dysgu peirianyddol sydd ar hyn o bryd yn gweithio ar destun i leferydd i Mozilla.
- Alaa Saade – Uwch Wyddonydd Dysgu Peirianyddol yn Snips (Paris)
- Laurent Besacier – Athro yn Université Grenoble Alpes, NLP, prosesu lleferydd, adnoddau llai eu hadnoddau
- David van Leeuwen – Technolegydd Lleferydd
- Benjamin Milde – ymgeisydd PhD mewn NLP/prosesu lleferydd
- Shay Palachy – M.Sc. mewn Cyfrifiadureg, Gwyddonydd Data Arweiniol mewn cwmni cychwynnol
***
Mae Common Voice yn cefnogi gwaith Mozilla ym maes adnabod lleferydd, sy’n rhedeg dan yr enw project “Deep Speech“, model peiriant adnabod lleferydd cod agored sy’n dod yn agos at gywirdeb dynol, a ryddhawyd ym mis Tachwedd 2017. Ar y cyd gyda’r set ddata Common Voice rydym yn credu y gall ac y bydd y dechnoleg hon yn galluogi ton o gynnyrch a gwasanaethau arloesol, ac y dylai hyn fod ar gael i bawb.