Here’s our newest bi-weekly installment of Happenings at the Hatchery (“What’s Hatching”) and how to get your project (Mozilla or otherwise) to the next level (“Hatch This”). Enjoy!
What’s Hatching
With the introduction of Firefox OS smartphones, we in the Labs’ Hatchery have been thinking a lot about apps for them. Developers like me lust after platforms like this this because we find the technology itself so interesting. I think most users choose a device based on the functionality it provides—functionality that is most often manifested in apps.
We need a lot more apps.
The Mozilla project is a global community of users, contributors and developers. Wouldn’t it be great if we could put the power of building Firefox OS apps into the hands of more than just those that identify as Developers? Many have tried to do similar things to this, many have failed. We have hypotheses that may contribute to the success of this effort:
Building apps should be fun. Building releveant, interesting apps can be fun for non-developers.
Games are fun. This seems like an obvious statement, but can we make building apps more like playing games? Can we make learning programming more like gameplay discovery than research? This requires experimentation. It will take more than whiteboards and debate. We’re going to test our hypotheses by building experimental software and introducing it to as many people as possible. We’re going to test it with users at Campus Party UK.
Here’s our checklist:
Keep the Mechanics, Abstract the Details:
Within SimCity, you learn the mechanics of city planning—zoning neighbourhoods and connecting roads. You do this without worrying about details like permits.

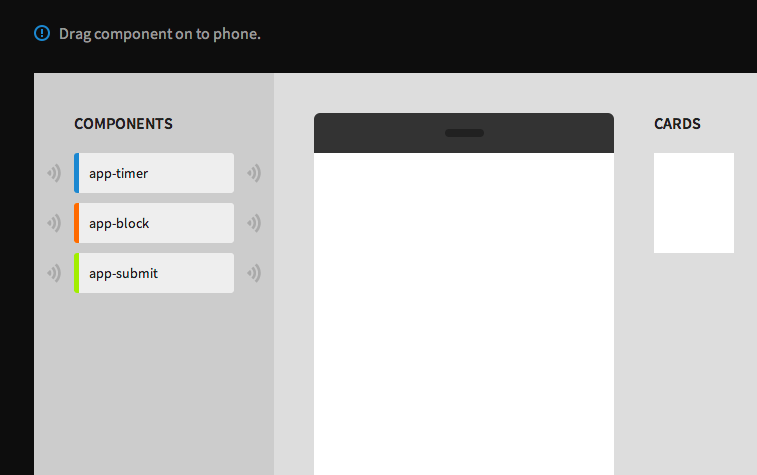
Our goal in Appmaker is for the user to discover the mechanics of event-driven programming, without worrying about details like for loops and css layout.
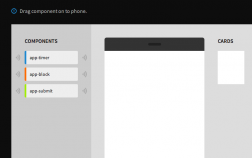
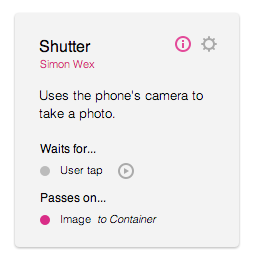
Components — “A Thing I want”
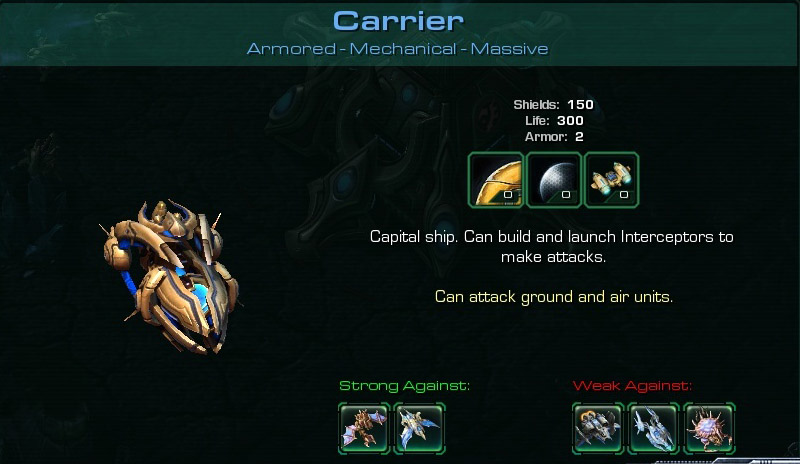
In real-time strategy games, the player produces units. Units perform certain tasks and work well with complimentary units.
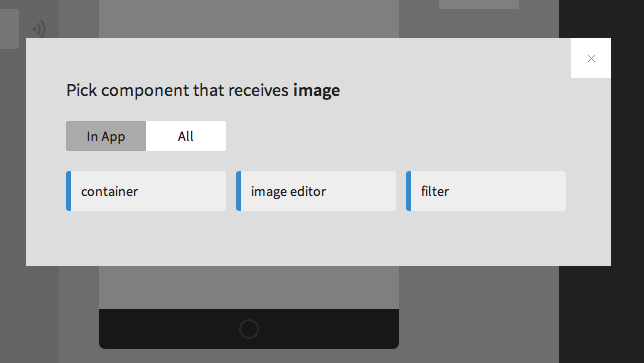
In Appmaker, we’re calling these things components. Components linked together provide the functionality of an app and expose the features of the phone.
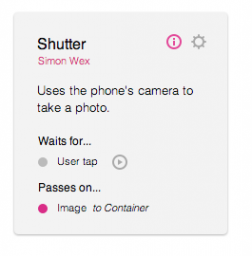
Advisors
Games have advisors to suggest where you might build or alert that you have trouble.
In Appmaker, you will receive tips and alerts to guide you through adding and connecting of components.
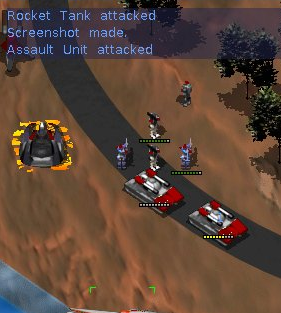
Lots of Action
In games such as Command and Conquer, when you use a tank to attack an enemy unit, it moves and starts firing weapons. There is instant and constant action.
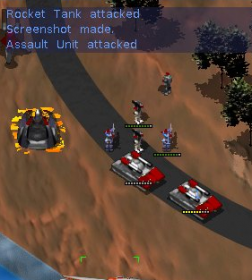
In Appmaker, components will wait for events. As soon as they happen, the app lights up and data starts to flow. We’ll be complementing the activity indicators with a message log style console.

Growing with the User
As you progress in a building game, the components you use mature to fit your situation. Games contain complex dependency hierarchies that are slowly introduced to the user as they become more advanced.
In Appmaker we’re going to present the maker with a limited set of components until they “level up.” We hope the maker will learn at points of interest instead of being bombarded by huge amounts of information.
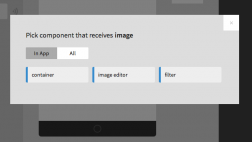
As with any positive hypotheses, we hope they test true. We hope that this is the beginning of something more than seems obvious.
Hatch This
Every post we include some practical advice and tools to help you get your product to the next level. This week we’re pleased to feature Mozillian and WebFWD mentor Jane Finette on defining your customer value proposition and key points of differentiation. Because it doesn’t matter how much technical or design beauty your product has if it doesn’t resonate with the rest of the world.
Tune in to hear Jane and get some great tools to apply to your project so it matters.
http://webfwd.tumblr.com/post/27933281198/the-customer-value-proposition