AES-GCM is a NIST standardised authenticated encryption algorithm (FIPS 800-38D). Since its standardisation in 2008 its usage increased to a point where it is the prevalent encryption used with TLS. With 88% it is by far the most widely used TLS cipher in Firefox.
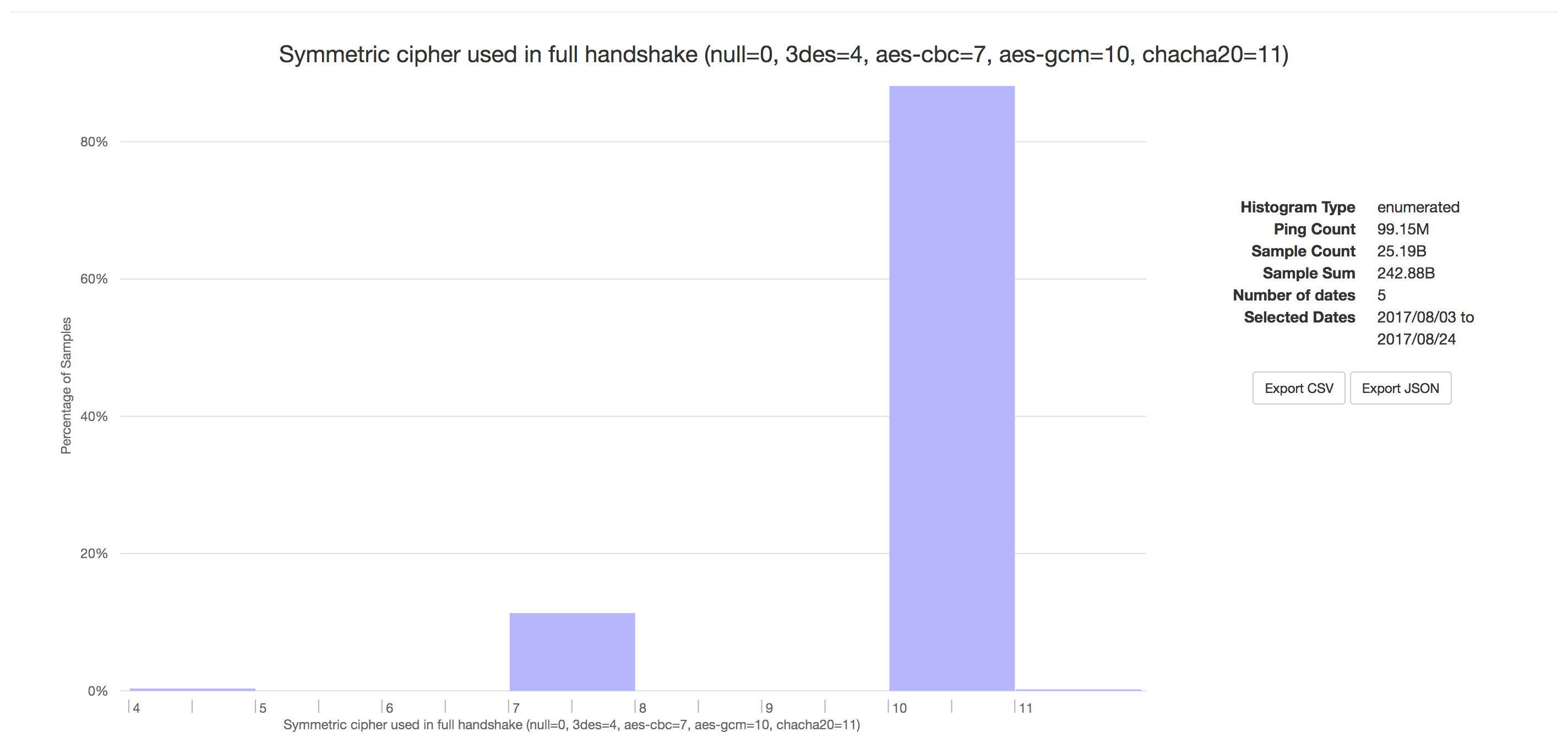
Firefox telemetry on symmetric ciphers in TLS
Unfortunately the AES-GCM implementation used in Firefox (provided by NSS) until now did not take advantage of full hardware acceleration on all platforms; it used a slower software-only implementation on Mac, Linux 32-bit, or any device that doesn’t have all of the AVX, PCLMUL, and AES-NI hardware instructions. Based on hardware telemetry information, only 30% of Firefox 55 users get full hardware acceleration (as well as the resulting resistance to side channel analysis). In this post I describe how I made AES-GCM in NSS and thus Firefox 56 significantly faster, more side-channel resistant, and more energy efficient on most platforms using hardware support.
To evaluate the actual impact on Firefox users, I tested the practical speed of our encryption by downloading a large file from a secure site using various hardware configurations: Downloading a file on a mid-2015 MacBook Pro Retina with Firefox 55 spends 17% of its CPU usage in ssl3_AESGCM, the routine that performs the decryption. On a Windows laptop with an AMD C-70 (without the AES-NI instruction) Firefox CPU usage is 60% and the download speed is capped at 3.5MB/s. This doesn’t seem to be only an academic issue: Particularly for battery-operated devices, the energy consumption difference would be noticeable.
Improving GCM performance
Speeding up the GCM multiplication function is the first obvious step to improve AES-GCM performance. A bug was opened on integration of the original AES-GCM code to provide an alternative to the textbook implementation of gcm_HashMult. This code is not only slow but has timing side channels as you can see in the following excerpt from the binary multiplication algorithm:
for (ib = 1; ib < b_used; ib++) {
b_i = *pb++;
/* Inner product: Digits of a */
if (b_i)
s_bmul_d_add(MP_DIGITS(a), a_used, b_i, MP_DIGITS(c) + ib);
else
MP_DIGIT(c, ib + a_used) = b_i;
}
We can improve on two fronts here. First NSS should use the PCLMUL hardware instruction to speed up the ghash multiplication if possible. Second if PCLMUL is not available, NSS should use a fast constant-time implementation.
Bug 868948 has several attempts of speeding up the software implementation without introducing timing side-channels. Unfortunately the fastest code that was proposed uses table lookups and is therefore not constant-time (accessing memory locations in the same cache line still leaks timing information). Thanks to Thomas Pornin I re-implemented the binary multiplication in a way that doesn’t leak any timing information and is still faster than any other proposed C code (see Bug 868948 or openssl/boringssl for other software implementations). Check out Thomas’ excellent write-up for details.
If PCLMUL is available on the CPU, using it is the way to go. All modern compilers support intrinsics, which allow us to write “inline assembly” in C that runs on all platforms without having to write assembly code files. A hardware accelerated implementation of the ghash multiplication can be easily implemented with _mm_clmulepi64_si128.
On Mac and Linux the new 32-bit and 64-bit software ghash functions (faster and constant-time) are used on the respective platforms if PCLMUL or AVX is not available. Since Windows doesn’t support 128-bit integers (outside of registers) NSS falls back to the slower 32-bit ghash code – which is still more than 25% faster than the previous ghash implementation.
Improving AES performance
To speed up AES, NSS requires hardware acceleration on Mac as well as on Linux 32-bit and any machine that doesn’t support AVX (or has it disabled). When NSS can’t use the specialised AES code it falls back to a table-based implementation that is again not constant-time (in addition to being slow). There are currently no plans of rewriting the existing fallback code. AES is impossible to implement efficiently in software without introducing side channels. Implementing AES with intrinsics on the other hand is a breeze.
m = _mm_xor_si128(m, cx->keySchedule[0]);
for (i = 1; i < cx->Nr; ++i) {
m = _mm_aesenc_si128(m, cx->keySchedule[i]);
}
m = _mm_aesenclast_si128(m, cx->keySchedule[cx->Nr]);
_mm_storeu_si128((__m128i *)output, m);
Key expansion is a little bit more involved (for 192 and 256 bit), but is written in about 100 lines as well.
Mac sees the biggest improvement here. Previously, only Windows and 64-bit Linux used AES-NI, and now all desktop x86 and x64 platforms use it when available.
Looking at the numbers
To measure the performance gain of the new AES-GCM code I encrypted a 479MB file with a 128-bit key (the most widely used key size for AES-GCM). Note that these numbers are supposed to show a trend and heavily depend on the used machine and system load at the time.
Linux measurements are done on an Intel Core i7-4790, Windows measurements on a Surface Pro 2 with an Intel Core i5-4300U, and Mac mid 2015 Core i7-4980HQ. For all following graphs lower is better.

Linux 64 AES-GCM 128 encryption performance improvements
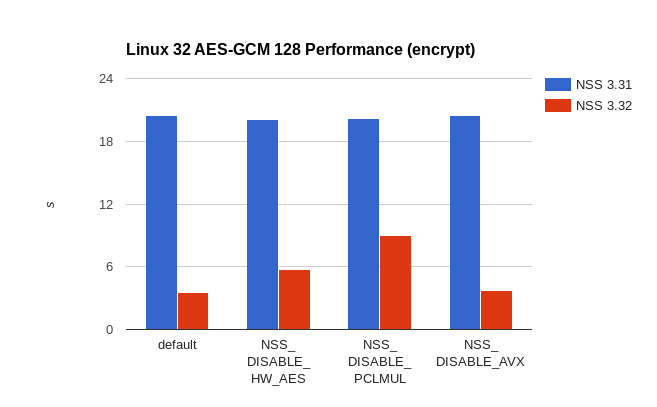
Linux 32 AES-GCM 128 encryption performance improvements
Performance of AES-GCM 128 on any 64-bit Linux machine without hardware support for the AES, PCLMUL, or AVX instructions is at least twice as fast now. If the AES and PCLMUL instructions are available, the new code only needs 33% of the time the old code took.
The speed-up for 32-bit Linux is more significant as it didn’t previously have any hardware accelerated code. With full hardware acceleration the new code is more than 5 times faster than before. Even in the worst case – when PCLMUL is not available – the speedup is still more than 50%.
The story is similar on Windows, although NSS already had fast code for 32-bit Windows users.
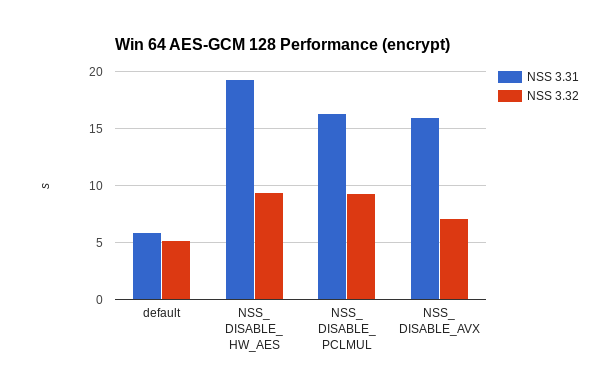
Windows 64 AES-GCM 128 encryption performance improvements
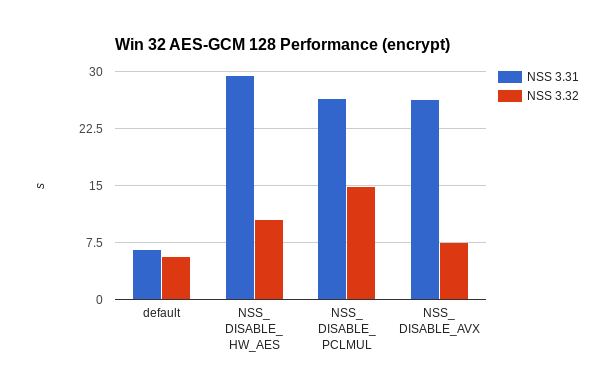
Windows 32 AES-GCM 128 encryption performance improvements
Performance improvements on Mac (64-bit only) range from 60% in the best case to 44% when AES-NI or PCLMUL is not available.

Mac OSX AES-GCM 128 encryption performance improvements
The numbers in Firefox
NSS 3.32 (Firefox 56) ships with the new accelerated AES-GCM code. It provides significantly reduced CPU usage for most TLS connections or higher download rates – meaning better energy efficiency, too. NSS 3.32 is more intelligent in detecting the CPU’s capabilities and using hardware acceleration whenever possible. Assuming that all intrinsics and mathematical operations (other than division) are constant-time on the CPU, the new code doesn’t have any timing side-channels.
On the very basic laptop with the AMD C-70 download rates increased from ~3MB/s to ~6MB/s, and this is a device that has no hardware acceleration support.
To see the performance improvement we can look at the case where AVX is not available (which is the case for about 2/3 of the Firefox population). Assuming that at least AES-NI and PCLMUL is supported by the CPU we see the CPU usage drop from 15% to 3%.
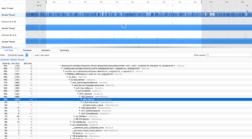
AES_Decrypt CPU usage with NSS 3.31 without AVX hardware support
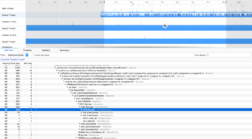
AES_Decrypt CPU usage with NSS 3.32 without AVX hardware support
The most immediate effect can be seen on Mac. AES_Decrypt NSS 3.31 used 9% CPU while in NSS 3.32 it uses only 4%.
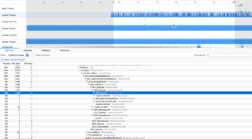
AES_Decrypt CPU usage with NSS 3.31 on Mac OSX
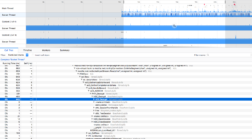
AES_Decrypt CPU usage with NSS 3.32 on Mac OSX
The most significant performance improvements are summarise din the following table depicting the time in seconds to decrypt a ~500MB file with AES-GCM 128; lower is better.
| Linux 32-bit | Mac | No AVX support | |
| NSS 3.31 (Firefox 55) | 20.3 | 11.5 | 21.3 |
| NSS 3.32 (Firefox 56) | 3.4 | 4.6 | 3.5 |
These improvements to AES-GCM in NSS make Firefox 56 significantly faster, more side-channel resistant, and more energy efficient on most platforms using hardware support.