We here on the Mozilla Services team are happy to announce our first beta release (v0.2b1) of Heka, a tool for high performance data gathering, analysis, monitoring, and reporting. Heka’s main component is hekad, a lightweight daemon program that can run on nearly any host machine which does the following:
- Gathers data through reading and parsing log files, monitoring server health, and/or accepting client network connections using any of a wide variety of protocols (syslog, statsd, http, heka, etc.).
- Converts the acquired data into a standardized internal representation with a consistent metadata envelope to support effective handling and processing by the rest of the Heka system.
- Evaluates message contents and metadata against a set of routing rules and determines all of the processing filters and external endpoints to which a message should be delivered.
- Processes message contents in-flight, to perform aggregation, sliding-window event processing and monitoring, extraction of structured data from unstructured data (e.g. parsing log file output text to generate numeric stats data and/or more processing-friendly data structures), and generation of new messages as reporting output.
- Delivers any received or internally generated message data to an external location. Data might be written to a database, a time series db, a file system, or a network service, including an upstream hekad instance for further processing and/or aggregation.
Heka is written in Go, which has proven well-suited to building a data pipeline that is both flexible and fast; initial testing shows a single hekad instance is capable of receiving and routing over 10 gigabits per second of message data. We’ve also borrowed and extended some great ideas from Logstash and have built Heka as a plugin-based system. Developers can build custom Input, Decoder, Filter (i.e. data-processing), and Output plugins to extend functionality quickly and easily.
All four of the plugin types can be implemented in Go, but managing these plugins requires editing the config file and restarting and, if you’re introducing new plugins, even recompiling the hekad binary. Heka provides another option, however, by allowing for “Sandboxed Filters,” written in Lua instead of Go. They can be added to and removed from a running Heka instance without the need to edit the config or restart the server. Heka also provides some Lua APIs that Sandboxed Filters can use for managing a circular buffer of time-series data, and for generating ad-hoc graph reports (such as the following example) that will show up on Heka’s reporting dashboard:
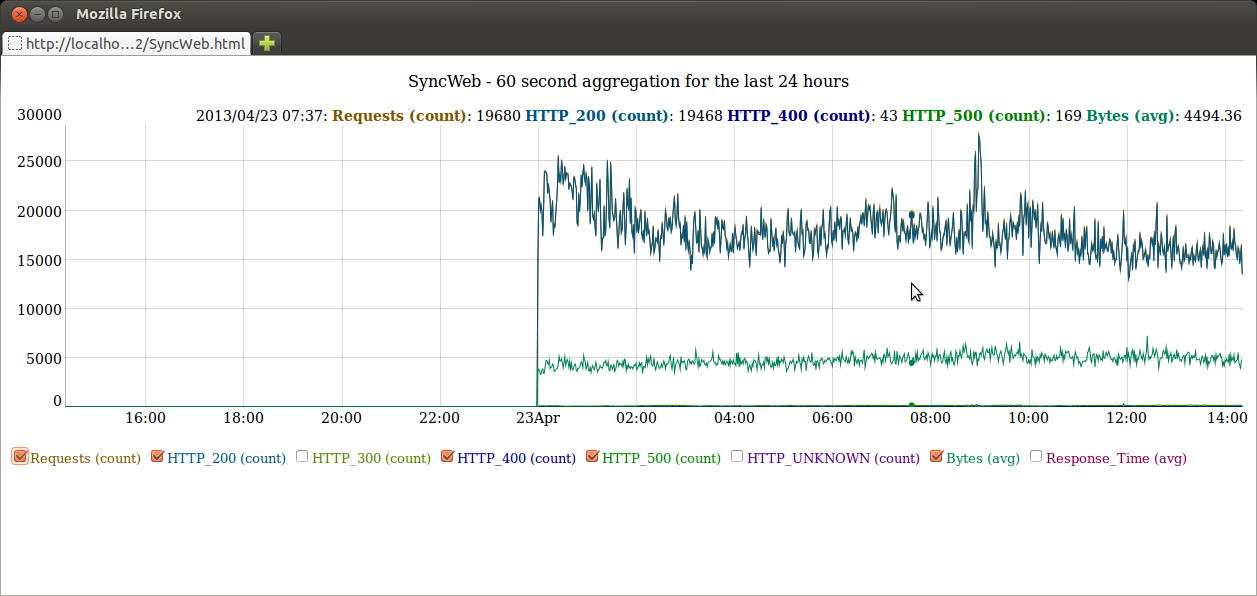
Heka is a new technology. We’re running it in production in a few places inside Mozilla, but it’s still a bit rough around the edges. Like everything Mozilla produces, however, it’s open source, so we’re releasing early and often to make it available to interested developers (contributors / pull requests welcome!) and early adopters. Here’s a list of resources for those who’d like to learn more:
- Heka v0.2 binaries
- Intro to Heka HTML presentation slides
- Heka project documentation
- Heka github project
- Heka mailing list (for developer support)
- IRC: #heka channel on irc.mozilla.org
Jeff Darcy wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
:
Royi wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
:
RDC wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
:
mheim wrote on
:
wrote on
:
nduthoit wrote on
:
wrote on
:
tk wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
:
Mateusz wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
:
Joe Shaw wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
:
boopathi wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
:
stu wrote on
:
wrote on
:
rmiller wrote on
:
wrote on
: