We are building a marketplace expected to reach millions of users. All of them should be able to rely on the Marketplace for browsing and installing apps from Firefox OS and Android phones.
Part of Mozilla’s job is to make it handle these hundreds of concurrent requests without falling down.
Unfortunately, we don’t have this kind of load at the moment, until our official public release. We needed an automated way of simulating all the server calls (e.g., API calls and page requests) to simulate expected site usage.
Because we’re computer scientists nerds, we like to automate whatever can be automated, and we came up with some tools to do the work for us; let’s face it: none of us wants to manually click all these links.
Okay, but what do we want to test? We mainly want to ensure that browsing apps categories, viewing app listing pages and rating apps all work fine. Of course, we also want to check that submitting a lots of apps in parallel still work as expected when you have an heavy server load.
Introducing Marteau
We’ve created a Web application named Marteau (meaning “hammer” – in french), which is using FunkLoad to create some load to our beloved marketplace. Here is how it works:
- You go the Marteau web interface and indicate the location of the loadtests you want to run. In our case, the loadtests are located in a git repository.
- Marteau downloads the tests and spawns multiple nodes on several machines. You can specify the number of nodes to spawn either manually or via a file in the git repository.
- Each of these nodes run the “scenarios” — that is, the tests in the loadtest suite. These tests contain HTTP calls to the system you want to test. Because there are many nodes (1 to 25 nodes, each of them doing between 50 and 500 requests), it sends a lot of queries in parallel.
- Each client locally writes to a file containing the results for the calls it just made. Each file is sent back to the marteau server so they can all be aggregated and analysed.
The marteau interface
The load tests looks a lot like unittest testcases, which is useful because most python developers are used to writing unittests.
Here is a really simple load test you can write and run with Funkload. This one does nothing more that hitting “/resource” with some params and checks that the returned status codes are 200 or 302.
Have a look at our tests and you’ll see what we have done for load testing the Marketplace.
Bending the TCP connections
From the tests we ran on our staging server, it seemed that we are able to “handle” the load. But now what happens if for whatever reason, we lose the connection to MySQL, elasticsearch, memcached, etc?
The fact is that we just don’t know, so we need to analyze this as well.
We created a kind of chaos monkey, a TCP proxy named Vaurien (which means “rapscallion” in French).
All our TCP connections, instead of going through our backends (eg. elasticsearch, memcached, etc), go trough Vaurien which can selectively drop connections, add network delays, etc. This lets us assess how the application under stress handles the load and how it is able to recover.
Vaurien is currently able to handle connections to HTTP, memcached, MySQL, redis, SMTP and raw TCP, but it’s possible to extend its behaviour to other protocols depending on your needs.
Vaurien runs as a simple TCP server and connects to two ports, the front-end one (the one exposed to you) and the backend one (that’s used to communicate with the actual service being proxied). In addition to that, Vaurien can listen for HTTP requests and change its behaviour on the fly, for instance start to add delay when you ask it to. We tried to document it pretty well so you can use it for your own needs.
Our findings
For each load test we’ve been doing, we correlated the number of errors occured with the number of concurrent requests. Using Marteau, we were able to ask for a series of concurrent requests to do on each client: for instance, asking to first spawn 50 users, then 100, 500, and finally 1000.
It got us nice graphs and we were able to see in Sentry what was wrong during the heavy load. For instance, we were able to see which tracebacks were related to our load test to the servers. This allowed us to fix some problems related to high load and to detect more clearly what can go wrong when under pressure.
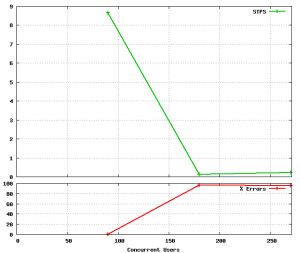 We can see what happens under load when our servers aren’t able to answer properly
We can see what happens under load when our servers aren’t able to answer properly
We created a wiki page containing the results for the differents backends we’ve been testing. Some of the tests here have been done manually, because it’s not possible to unplug everything automatically (e.g., Celery, our task queue manager)
One good step forward would be to run automatically these tests each week to avoid speed regression.
And don’t forget: Load testing can be loads of fun!