What is RMCAT congestion control, and how will it affect WebRTC?
RMCAT is an IETF Working Group which came out of proposal by myself and Harald Alvestrand, and an associated Congestion Control IAB/IRTF workshop at IETF 84 in Vancouver in 2012. The report from the workshop is RFC 7295.
tl;dr:
The RMCAT WG is working to develop new congestion control protocols for realtime RTP traffic to improve on state-of-the-art, to ensure that media streams don’t harm other users of the networks (both non-RTP and other RTP media streams), and to maximize quality. There are several proposed algorithms, and this work will feed back into mainline WebRTC implementations to improve network usage and media quality.
History:
Historically, RTP was unmanaged from a congestion-control perspective. If there wasn’t enough bandwidth for a stream, packets would queue somewhere, and if the queue overflowed, it would drop packets from the tail of the queue. This was seen as loss and delay, and in the case of the router being susceptible to Bufferbloat, it would cause major delay (even seconds of delay).
In response to problems with this, some VoIP devices would let you choose high or low bandwidth. For audio it did this using different codecs, like G.711 (64Kbps payload) vs G.729 (8Kbps). For video, the fixed video codec rate would be set according to the bandwidth the user said they had.
As you might guess, this was not a very good solution. Users often didn’t know their bandwidth; it would vary (especially if there was competing traffic at the bottleneck); if you guessed too low (or set it low to deal with an occasional problem), then quality would always be low. If you guessed too high, the call might totally fall apart.
The next logical step was to use congestion control, which is how most traffic on the internet is managed. TCP uses various algorithms for congestion control, but in general uses variations on AIMD algorithms.
Problems with traditional congestion control:
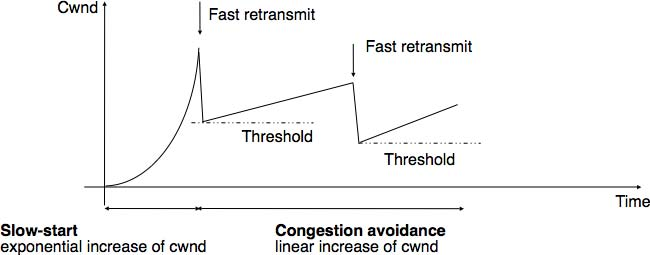
AIMD causes a sawtooth in the transmission rate when loss is seen. Loss is the indicator of congestion to TCP; in classic routers it means a buffer-queue overflowed due to congestion. Typically in TCP a loss will cause a 50% reduction in bitrate, and then a steady increase until loss is seen again. Needless to say, this is not ideal (or even OK) behavior for video codecs (or non-fixed-rate audio codecs). And because the signal for reduction was queue overflow, serious delay would build up, then start to drain away, then build up again.
You can see a nice graph of AIMD sawtooth here (the “Fast Retransmit” points are in response to loss).
{kind=link}
Proprietary Solutions:
So people started thinking about it (I was one of them, working on the Worldgate Ojo videophone – image in a call), and came up with more media-friendly methods. What I did and what GIPS (now part of Google) did was to build a delay-sensitive congestion mechanism, which as a side-effect tries to avoid the conditions (queue overflow) that lead to packet loss. Typically they worked something like this:
{kind=link}
- Measure the inter-packet timing of incoming RTP packets, and compare with expected arrival times (typically using RTP timestamps).
- If packets are arriving consistently late, tell the sender to reduce bitrate The amount of reduction is typically not dramatic, but may be proportional to the arrival slowdown (in the case of my algorithm in the Ojo).
- If it appears that packets are arriving faster than expected, a queue is draining, so maintain bitrate.
- If packets are arriving on-time, allow the sender to increase bitrate (how fast is one of many ad-hoc proprietary details to these schemes).
Lo and behold, these algorithms generally worked! (And often, though not always, worked well.)
Hallelujah! We’re done, right?
No…
Problems with proprietary schemes:
So there were (are) still problems:
- These schemes were all proprietary, to one degree or another. (Google open-sourced the scheme used in webrtc.org code.)
- They were not specified in general other than the implementation.
- No one was really sure how much impact they had on other traffic (do they hog all the bandwidth? Do they fail when competing with TCP flows?)
- Are they fair with other media streams? (Often algorithms aren’t without proper tuning.)
- What happens when someone implementing proprietary scheme Foo tries to talk to someone who implements scheme Bar?
- How efficient are they, and how well do they avoid impairments of quality?
- How well they were tuned varied a lot, especially use-cases outside the norm.
- Some of these schemes would also lose badly when faced with enough TCP traffic, as long TCP flows (file transfers, etc) would eventually end up with all the bits
Standards work:
In 2012, Harald and I (and others) thought trying to standardize this mess was a really good idea. We proposed starting a Working Group, and there was enough interest in discussing the issues that the IRTF decided to hold
a full-day workshop on realtime media congestion control before the IETF meeting. You can see the results of this workshop in RFC 7295. It went very well, and the working group was approved.
Since then a lot of work has happened. We have several proposed algorithms, including NADA from Cisco, Scream from Ericsson and Google Congestion Control algorithm (this paper has a lot of good details on Google’s currently-implemented algorithm, tested using the evaluation framework developed for RMCAT) These algorithms have improved considerably since they were first proposed, particularly in the areas of Fairness (to other flows using the same algorithm), and in competing with short- and long-lived TCP flows, but considerable tuning and updates still need to be made. You can see materials and the presentations from the latest IETF RMCAT meeting at the IETF 96 RMCAT Proceedings page.
Notably, some of these algorithms are at least able to “hold their own” with some TCP flows, though at the cost of expected additional delay. One good sign is that the few results available with routers configured to use modern AQM (Active Queue Management) algorithms such as CODEL show almost no additional delay when competing with a TCP stream. I believe that improved variants on CODEL (fq_codel, etc) will work as well or better.
To simplify future development of congestion algorithms for RTP, the WG has been defining a standard feedback RTCP packet indicating arrival times and ECN notifications, so that the receiver side can be
generic and the algorithm can run solely on the sender side. Earlier versions of the Google algorithm (and others) ran part of the algorithm on the receiver side, and sent indications of available bandwidth using RTCP REMB packets.
One thing to remember is that most of these algorithms are being tested and evaluated using network simulators like NS2 and NS3, and usually with “fake” video codecs or sometimes canned video sequences.
Integration with browsers:
An older version of Google’s algorithm (using REMB) is being used by both Chrome and Firefox currently. We hope to enable some of the other algorithms (preferably all of them!) in Firefox soon, on an optional (or custom-build)
basis. This will let people experiment with these algorithms in real-world situations. We hope to have these available in some test versions of Firefox this winter, and also to implement the proposed generic feedback packet.
Look for more announcements here as this work progresses, and perhaps additional articles about the individual algorithms (hint hint).