
The future of intelligence is being set right now, and the path we’re on leads somewhere I don’t want to go. We’re drifting toward a world where intelligence is something you rent — where your ability to reason, create, and decide flows through systems you don’t control, can’t inspect, and didn’t shape. In that world, the landlord can change the terms anytime, and you have no recourse but to accept what you’re given.
I think we can do better. Making that happen is now central to what Mozilla is doing.
What we did for the web
Twenty-five years ago, Microsoft Internet Explorer controlled 95% of the browser market, which meant Microsoft controlled how most people experienced the internet and who could build what on what terms. Mozilla was born to change this, and Firefox succeeded beyond what most people thought possible — dropping Internet Explorer’s market share to 55% in just a few years and ushering in the Web 2.0 era. The result was a fundamentally different internet. It was faster and richer for everyday users, and for developers it was a launchpad for open standards and open source that decentralized control over the core technologies of the web.
There’s a reason the browser is called a “user agent.” It was designed to be on your side — blocking ads, protecting your privacy, giving you choices that the sites you visited never would have offered on their own. That was the first fight, and we held the line for the open web even as social networks and mobile platforms became walled gardens.
Now AI is becoming the new intermediary. It’s what I’ve started calling “Layer 8” — the agentic layer that mediates between you and everything else on the internet. These systems will negotiate on our behalf, filter our information, shape our recommendations, and increasingly determine how we interact with the entire digital world.
The question we have to ask is straightforward: Whose side will your new user agent be on?
Why closed systems are winning (for now)
We need to be honest about the current state of play: Closed AI systems are winning today because they are genuinely easier to use. If you’re a developer with an idea you want to test, you can have a working prototype in minutes using a single API call to one of the major providers. GPUs, models, hosting, guardrails, monitoring, billing — it all comes bundled together in a package that just works. I understand the appeal firsthand, because I’ve made the same choice myself on late-night side projects when I just wanted the fastest path from an idea in my head to something I could actually play with.
The open-source AI ecosystem is a different story. It’s powerful and advancing rapidly, but it’s also deeply fragmented — models live in one repository, tooling in another, and the pieces you need for evaluation, orchestration, guardrails, memory, and data pipelines are scattered across dozens of independent projects with different assumptions and interfaces. Each component is improving at remarkable speed, but they rarely integrate smoothly out of the box, and assembling a production-ready stack requires expertise and time that most teams simply don’t have to spare. This is the core challenge we face, and it’s important to name it clearly: What we’re dealing with isn’t a values problem where developers are choosing convenience over principle. It’s a developer experience problem. And developer experience problems can be solved.
The ground is already shifting
We’ve watched this dynamic play out before and the history is instructive. In the early days of the personal computer, open systems were rough, inconsistent, and difficult to use, while closed platforms offered polish and simplicity that made them look inevitable. Openness won anyway — not because users cared about principles, but because open systems unlocked experimentation and scale that closed alternatives couldn’t match. The same pattern repeated on the web, where closed portals like AOL and CompuServe dominated the early landscape before open standards outpaced them through sheer flexibility and the compounding benefits of broad participation.
AI has the potential to follow the same path — but only if someone builds it. And several shifts are already reshaping the landscape:
- Small models have gotten remarkably good. 1 to 8 billion parameters, tuned for specific tasks — and they run on hardware that organizations already own;
- The economics are changing too. As enterprises feel the constraints of closed dependencies, self-hosting is starting to look like sound business rather than ideological commitment (companies like Pinterest have attributed millions of dollars in savings to migrating to open-source AI infrastructure);
- Governments want control over their supply chain. Governments are becoming increasingly unwilling to depend on foreign platforms for capabilities they consider strategically important, driving demand for sovereign systems; and,
- Consumer expectations keep rising. People want AI that responds instantly, understands their context, and works across their tools without locking them into a single platform.
The capability gap that once justified the dominance of closed systems is closing fast. What remains is a gap in usability and integration. The lesson I take from history is that openness doesn’t win by being more principled than the alternatives. Openness wins when it becomes the better deal — cheaper, more capable, and just as easy to use
Where the cracks are forming
If openness is going to win, it won’t happen everywhere at once. It will happen at specific tipping points — places where the defaults haven’t yet hardened, where a well-timed push can change what becomes normal. We see four.
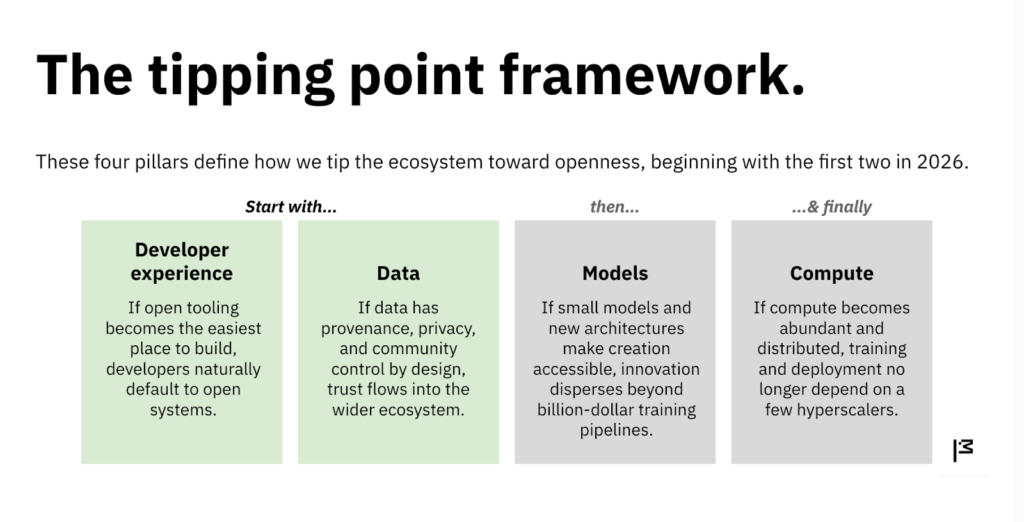
The first is developer experience. Developers are the ones who actually build the future — every default they set, every stack they choose, every dependency they adopt shapes what becomes normal for everyone else. Right now, the fastest path runs through closed APIs, and that’s where most of the building is happening. But developers don’t want to be locked in any more than users do. Give them open tools that work as well as the closed ones, and they’ll build the open ecosystem themselves.
The second is data. For a decade, the assumption has been that data is free to scrape — that the web is a commons to be harvested without asking. That norm is breaking, and not a moment too soon. The people and communities who create valuable data deserve a say in how it’s used and a share in the value it creates. We’re moving toward a world of licensed, provenance-based, permissioned data. The infrastructure for that transition is still being built, which means there’s still a chance to build it right.
The third is models. The dominant architecture today favors only the biggest labs, because only they can afford to train massive dense transformers. But the edges are accelerating: small models, mixtures of experts, domain-specific models, multilingual models. As these approaches mature, the ability to create and customize intelligence spreads to communities, companies, and countries that were previously locked out.
The fourth is compute. This remains the choke point. Access to specialized hardware still determines who can train and deploy at scale. More doors need to open — through distributed compute, federated approaches, sovereign clouds, idle GPUs finding productive use.
What an open stack could look like
Today’s dominant AI platforms are building vertically integrated stacks: closed applications on top of closed models trained on closed data, running on closed compute. Each layer reinforces the next — data improves models, models improve applications, applications generate more data that only the platform can use. It’s a powerful flywheel. If it continues unchallenged, we arrive at an AI era equivalent to AOL, except far more centralized. You don’t build on the platform; you build inside it.
There’s another path. The sum of Linux, Apache, MySQL, and PHP won because that combination became easier to use than the proprietary alternatives, and because they let developers build things that no commercial platform would have prioritized. The web we have today exists because that stack existed.
We think AI can follow the same pattern. Not one stack controlled by any single party, but many stacks shaped by the communities, countries, and companies that use them:
- Open developer interfaces at the top. SDKs, guardrails, workflows, and orchestration that don’t lock you into a single vendor;
- Open data standards underneath. Provenance, consent, and portability built in by default, so you know where your training data came from and who has rights to it;
- An open model ecosystem below that. Smaller, specialized, interchangeable models that you can inspect, tune to your values, and run where you need them; and
- Open compute infrastructure at the foundation. Distributed and federated hardware across cloud and edge, not routed through a handful of hyperscn/lallers.
Pieces of this stack already exist — good ones, built by talented people. The task now is to fill in the gaps, connect what’s there, and make the whole thing as easy to use as the closed alternatives. That’s the work.
Why open source matters here
If you’ve followed Mozilla, you know the Manifesto. For almost 20 years, it’s guided what we build and how — not as an abstract ideal, but as a tool for making principled decisions every single day. Three of its principles are especially urgent in the age of AI:
- Human agency. In a world of AI agents, it’s more important than ever that technology lets people shape their own experiences — and protects privacy where it matters most;
- Decentralization and open source. An open, accessible internet depends on innovation and broad participation in how technology gets created and used. The success of open-source AI, built around transparent community practices, is critical to making this possible; and
- Balancing commercial and public benefit. The direction of AI is being set by commercial players. We need strong public-benefit players to create balance in the overall ecosystem.
Open-source AI is how these principles become real. It’s what makes plurality possible — many intelligences shaped by many communities, not one model to rule them all. It’s what makes sovereignty possible — owning your infrastructure rather than renting it. And it’s what keeps the door open for public-benefit alternatives to exist alongside commercial ones.
What we’ll do in 2026
The window to shape these defaults is still open, but it won’t stay open forever. Here’s where we’re putting our effort — not because we have all the answers, but because we think these are the places where openness can still reset the defaults before they harden.
Make open AI easier than closed. Mozilla.ai is building any-suite, a modular framework that integrates the scattered components of the open AI stack — model routing, evaluation, guardrails, memory, orchestration — into something coherent that developers can actually adopt without becoming infrastructure specialists. The goal is concrete: Getting started with open AI should feel as simple as making a single API call.
Shift the economics of data. The Mozilla Data Collective is building a marketplace for data that is properly licensed, clearly sourced, and aligned with the values of the communities it comes from. It gives developers access to high-quality training data while ensuring that the people and institutions who contribute that data have real agency and share in the economic value it creates.
Learn from real deployments. Strategy that isn’t grounded in practical experience is just speculation, so we’re deepening our engagement with governments and enterprises adopting sovereign, auditable AI systems. These engagements are the feedback loops that tell us where the stack breaks and where openness needs reinforcement.
Invest in the ecosystem. We’re not just building; we’re backing others who are building too. Mozilla Ventures is investing in open-source AI companies that align with these principles. Mozilla Foundation is funding researchers and projects through targeted grants. We can’t do everything ourselves, and we shouldn’t try. The goal is to put resources behind the people and teams already doing the work.
Show up for the community. The open-source AI ecosystem is vast, and it’s hard to know what’s working, what’s hype, and where the real momentum is building. We want to be useful here. We’re launching a newsletter to track what’s actually happening in open AI. We’re running meetups and hackathons to bring builders together. We’re fielding developer surveys to understand what people actually need. And at MozFest this year, we’re adding a dedicated developer track focused on open-source AI. If you’re doing important work in this space, we want to help it find the people who need to see it.
Are you in?
Mozilla is one piece of a much larger movement, and we have no interest in trying to own or control it — we just want to help it succeed. There’s a growing community of people who believe the open internet is still worth defending and who are working to ensure that AI develops along a different path than the one the largest platforms have laid out. Not everyone in that community uses the same language or builds exactly the same things, but something like a shared purpose is emerging. Mozilla sees itself as part of that effort.
We kept the web open not by asking anyone’s permission, but by building something that worked better than the alternatives. We’re ready to do that again.
So: Are you in?
If you’re a developer building toward an open source AI future, we want to work with you. If you’re a researcher, investor, policymaker, or founder aligned with these goals, let’s talk. If you’re at a company that wants to build with us rather than against us, the door is open. Open alternatives have to exist — that keeps everyone honest.
The future of intelligence is being set now. The question is whether you’ll own it, or rent it.
We’re launching a newsletter to track what’s happening in open-source AI — what’s working, what’s hype, and where the real momentum is building. Sign up here to follow along as we build.
Read more here about our emerging strategy, and how we’re rewiring Mozilla for the era of AI.


