As many of you are probably already aware, Mozilla has recently gotten into the mobile OS space with Firefox OS. Firefox OS is built using web technologies like HTML, CSS, and of course Javascript. All Firefox OS apps are built on these technologies, including core platform apps.
Given that app logic in Firefox OS will be written in Javascript, one of the questions facing Mozilla’s Javascript engine (SpiderMonkey) is how it stacks up against other language platforms on mobile devices. To try to get some insight into that question, I spent a little time over the last two weeks conducting a small performance experiment.
the experiment
Starting with the SunSpider benchmark as a base, I ported a handful of programs from Javascript to both Java and C++, being as faithful as possible to the original logic. I compiled the Java version into an Android Dalvik app, and I compiled the C++ version with emscripten to produce asm.js code.
Then I measured the following times on a Nexus 4:
- Dalvik app, running directly on Android
- Asm.js code (compiled from C++), running on Mobile Firefox Nightly
- Native code (compiled from C++), running directly on Android (compiled using
ndk-build V=1 TARGET_ARCH_ABI=armeabi-v7a)
I took the inverse of the running times (so that higher scores would be better), and scaled all results so that Dalvik had a score of 1 for each program.
I also looped the runs 10 to 1000 times (depending on the program) to give the optimizing engines an opportunity to compile the hot code. Typically, SunSpider programs take a fraction of a second to run. Longer runtimes make SunSpider mimic app execution conditions, since apps typically run from dozens of seconds to minutes at a time.
The ported programs were binary-trees, 3D-morph, partial-sums, fasta, spectral-norm, nsieve, and nbody. You can obtain the source code at:
http://github.com/kannanvijayan/benchdalvik
the disclaimer
I want to be very clear about this up-front: I don’t think SunSpider is a great benchmark for sophisticated performance analysis. It’s really much closer to a collection of micro-benchmarks that cover a limited baseline level of performance measurement.
I chose SunSpider for this experiment because it contains small benchmarks that are easy to hand port, and because there is a clear translation from the Javascript source to a comparable C++ or Java source. Comparing different language platforms is not an exact science. Even in these simple micro benches, it behooves us to properly analyze and evaluate the results.
the results
Disclaimers aside, you may be surprised at the results:
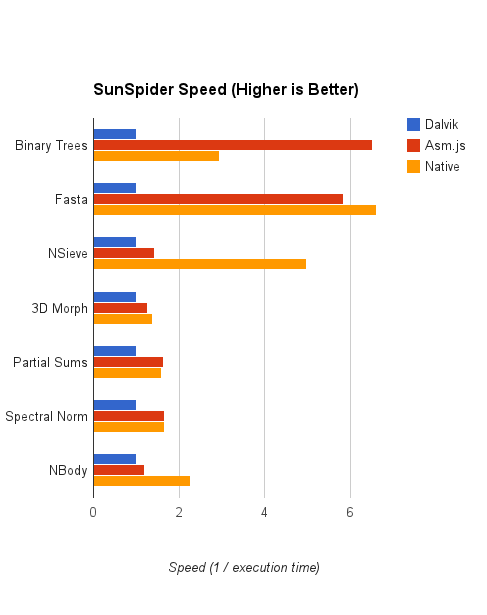
The graph above shows asm.js doing pretty well, rivaling or beating native on some benchnmarks (binary-trees). The numbers by themselves, however, aren’t as useful or as interesting as the reasons why. Let’s dissect the results from most interesting to least interesting.
the analysis
Binary Trees
The binary trees score is very surprising. Here, the asm.js version actually does significantly better than native. This result seems very counter-intuitive, but it may have a reasonable explanation.
Notice that binary-trees allocates a lot of objects. In C++, this causes many calls to malloc. When compiled to native code, the malloc implementation occasionally uses expensive system calls to allocate new memory from the system.
In asm.js, the compiled C++ is executed using a Javascript typed array as the “machine memory”. The machine memory is allocated once and then used for the entire program runtime. Calls to malloc from asm.js programs perform no syscalls. This may be the reason behind asm.js-compiled C++ doing better than native-compiled C++, but requires further investigation to confirm.
Another question is why Dalvik does so badly. This is the kind of thing Java should excel at: simple, fixed size class, lots of small allocations, etc. I don’t have a good answer to this question – this score actually genuinely surprised me, as I was expecting Dalvik to come out stronger than it did.
This is pure speculation, but I think Dalvik’s score may be a consequence of its tracing JIT. After speaking to people with tracing JIT experience, I learned that compiling recursion using tracing JITs can be very difficult. Given that binary trees spends most of its time in a few recursive functions, this might explain Dalvik’s result. If a reader has better insight into this score and what might be causing it, I would love your feedback.
Fasta
Note that the fasta program has been modified to move the makeCumulative operation out of the main loops and into the the setup code.
Asm.js and native C++ both come out far ahead of Dalvik, with native gaining a bit of an edge over asm.js. Let’s analyze what’s going on here.
It’s easy to see from the code that the program spends a LOT of time iterating across an associative array and accessing its values. In the C++/asm.js implementation, this is turned into an efficient iteration across a hash_map composed of inlined char keys and double values. In Java, this is an iteration across a java.util.HashMap, which stores heap-boxed Character and Double instances.
The Java hash table iteration incurs heavy overhead and indirection. The iteration traverses pointers to Map.Entry objects instead of directly iterating across fixed-size entries (as in C++), and it is forced to extract char and double values from heap-allocated Character and Double objects. Java collections are extremely powerful, but they tend to show their strengths more on large collections of more complex objects than on small collections of primitive values. The tiny lookup tables in fasta work against Java’s strengths.
The C++/asm.js version has a more efficient storage of these values, as well as a more efficient iteration across them. C++/asm.js also uses one-byte chars, as opposed to Java and Javascript’s two-byte chars, which means the C++/asm.js implementation generally touches less memory.
Breaking it down, the fasta benchmark’s main measurement is how fast the language can do lookups on small associative arrays. I believe Dalvik doesn’t do too well here because of Java peculiarities: collections not holding primitive values, and collection iteration having heavy overhead.
That said, it’s nice to see asm.js coming reasonably close behind native.
NSieve
In this benchmark, asm.js comes in about 3x slower than native, and slightly ahead of Dalvik.
This was an unexpected result – I had expected asm.js to be much closer to native speed. Alon Zakai (Mozilla researcher and author of emscripten, the tool that compiles C++ to asm.js) informs me that on desktop (x86) machines, the asm.js score is around 84% of the native score. This suggests that the problem lies in Spidermonkey’s ARM code-generation, and should be able to be improved upon.
3D Morph, Partial Sums, and Spectral Norm
I’m lumping these together because I feel that their scores all have basically the same explanation.
Native, asm.js, and Dalvik all have pretty similar scores, with native beating asm.js by a bit, and asm.js beating Dalvik by a slightly bigger bit. (Ignore the part where asm.js seems to come ahead of native on partial sums – I’m pretty sure that’s just measurement noise, and that the scores are actually just neck and neck).
The thing about these programs is that they’re all very double-precision-floating-point-heavy. These operations on an ARM cpu tend to be very expensive, and speed differences in other parts of the code would be underrepresented in the overall score.
The most surprising aspect of these results is not the asm.js vs native score, but the fact that Dalvik seems to lag behind about 20-30% from the asm.js scores.
NBody
In nbody, asm.js edges out Dalvik, but clocks in at about half the speed of the native code.
I have a guess about why asm.js is only half as fast as native here. The nbody code performs a lot of double-indirections: pulling a pointer out of an array, and then reading from memory at an offset from that pointer. Each of those reads can be implemented on ARM in a single instruction using the various addressing modes for the ARM LDR instruction.
For example, reading an object pointer from an array of pointers, and then reading a field within that object, would take two instructions:
LDR TargetReg, [ArrayReg + (IndexReg leftshift 2)]
LDR TargetReg, [TargetReg + OffsetOfField]
(Above, ArrayReg is a register holding a pointer to the array, IndexReg is a register holding the index within the array, and OffsetOfField is a constant value)
However, in asm.js, the “memory” reads are actually reads within a typed array, and “pointers” are just integer offsets within that array. Pointer dereferences in native code become array reads in asm.js code, and these reads must be bounds-checked as well. The equivalent read in asm.js would take five instructions:
LDR TargetReg, [ArrayReg + (IndexReg leftshift 2)]
CMP TargetReg, MemoryLength
BGE bounds-check-failure-address
LDR TargetReg, MemoryReg + TargetReg
LDR TargetReg, [TargetReg + OffsetOfField]
(Above, ArrayReg, IndexReg, and OffsetOfField are as before, and MemoryReg is a register holding a pointer to the base of the TypedArray used in asm.js to represent memory)
Basically, asm.js adds an extra level of indirection into the mix, making indirect memory reads more expensive. Since this benchmark relies heavily on performing many of these within its inner loops, I expect that this overhead weighs heavily.
Please keep in mind that the above reasoning is just an educated guess, and shouldn’t be taken as fact without further verification.
the takeaway
This experiment has definitely been interesting. There are a couple of takeaway conclusions I feel reasonably confident drawing from this:
1. Asm.js is reasonably competitive with native C++ code on ARM. Even discarding the one score where asm.js did better, it executes at around 70% of the speed of native C++ code. These results suggest that apps with high performance needs can use asm.js as the target of choice for critical hot-path code, achieving near native performance.
2. Asm.js competes very well on mobile performance compared to Dalvik. Even throwing out the benchmarks that are highly favourable to asm.js (binary-trees and fasta), there seems to be a consistent 10-50% speedup over comparable Dalvik code.
the loose ends
The astute reader may at this point be wondering what happened to the plain Javascript scores. Did regular Javascript do so badly that I ignored them? Is there something fishy going on here?
To be frank, I didn’t include the regular Javascript scores in the results because regular Javascript did far too well, and I felt that including those scores would actually confuse the analysis instead of help it.
The somewhat sad fact is that SunSpider scores have been “benchmarketed” beyond reason. All Javascript engines, including SpiderMonkey, use optimizations like transcendental math caches (a cache for operations such as sine, cosine, tangent, etc.) to improve their SunSpider scores. These SunSpider-specific optimizations, ironically, make SunSpider a poor benchmark for talking about plain Javascript performance.
If you really want to see how plain Javascript scores alongside the rest, click the following link:
http://blog.mozilla.org/javascript/files/2013/08/Dalvik-vs-ASM-vs-Native-vs-JS.png
{kind=link}
the errata
HackerNews reader justinsb pointed out a bug in my C++ and Java code for spectral norm (https://news.ycombinator.com/item?id=6174204). Programs have been re-built and the relevant numbers re-generated. The chart in the main post has been updated. The old chart is available here:
https://blog.mozilla.org/javascript/files/2013/08/Dalvik-vs-ASM-vs-Native.png
{kind=link}
Osvaldo Pinali Doederlein wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
panzi wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
Zac Bowling wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
voidlogic wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
Wukix Inc wrote on
:
wrote on
:
David Illsley wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
Nestor wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
Mikael Ståldal wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
Simon wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
A wrote on
:
wrote on
:
Kannan Vijayan wrote on
:
wrote on
:
Lefteris Stamatogiannakis wrote on
:
wrote on
:
Luke Wagner wrote on
:
wrote on
:
Matthew Holloway wrote on
:
wrote on
: