SIMD.js is a new API for performing SIMD (Single Instruction Multiple Data) computations in JavaScript which is being developed by Google, Intel, Mozilla, and others. For example, it defines a new Float32x4 type which represents 4 float32 values packed up together. The API contains functions which operate in parallel on each value, including all basic arithmetic operations, and operations to rearrange, load, and store such values. For a more complete introduction to SIMD.js, see Dan Gohman’s recent blog post about SIMD.js.
SIMD operations map closely to processor instructions, so they can be made very efficient on modern processors. In theory this means that a SIMD program using float32x4 instead of float32 may be up to four times faster than a non-SIMD program. In practice there is some overhead when using SIMD instructions — this is due to inserting and extracting values into / from a vector, shuffles, and programs sometimes need to be reorganized in order to have multiple values to operate on at the same time. Also note that only the parts of a program which will use float32x4 instead of float32 will benefit from the speedup, and other computations not using float32x4 obviously won’t get the speedup.
SIMD in OdinMonkey (asm.js)
Firefox Nightly began shipping SIMD.js support by adding it for asm.js code. Initially this covered the two SIMD types int32x4 and float32x4 as these are commonly used in SIMD compute kernels and are well supported across different architectures.
Implementing the SIMD operations for these two types in asm.js on a single platform (x86) allowed us to see that the performance of applications cross-compiled from C++ by Emscripten and using these intrinsics was close to native performance. Moreover, it gave us a platform to quickly iterate on the API, and allowed us to find numerous corner cases and gaps in the API, such as particular value inputs to some operations and architecture specific issues.
This work also paved the way for optimization in the general case (that is, not specific to asm.js) as the asm.js compiler and IonMonkey share a lot of the backend code which takes care of generating the assembly sequences which map to the SIMD instrinsics. It also made unit testing way simpler, as each operation can be tested separately in a consistent fashion.
Demos of SIMD code complying to the asm.js type system rules can be found on Intel’s demo site. You can even test it at home if you have a Nightly build of Firefox!
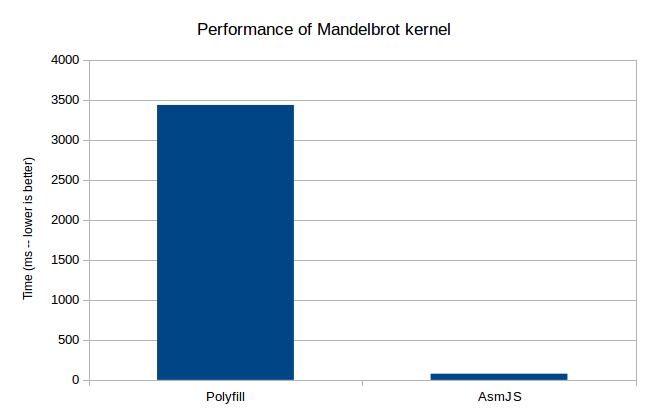
We’ve extracted the SIMD kernel code from the Mandelbrot demo, taken above, to be able to benchmark it. Here is a graphic that shows performance difference between the official SIMD.js polyfill (which mostly uses Typed Arrays) and the performance in OdinMonkey (asm.js). Note that the Y axis is in milliseconds, so the lower, the better.
SIMD in IonMonkey
As most of the work on implementing SIMD in asm.js was complete the next step was obviously to make it efficient in “regular” JavaScript, that is, non-asm.js.
The main difference between OdinMonkey (asm.js) and IonMonkey (“regular” JavaScript) is that IonMonkey has to cohabit with the Baseline compiler and the Interpreter. Thus it has to avoid object allocations while executing SIMD instructions and while boxing the SIMD values when calling back or returning to Baseline or the Interpreter, which expect objects.
The Base
Before running the code produced by IonMonkey, we first have to execute code produced by the baseline compiler. Baseline is mostly composed of inline caches, and at the moment it does not attempt any optimizations on SIMD objects. On the other hand, the inline caches do record which functions are being executed. The functions recorded by Baseline are then inlined by IonMonkey to generate SIMD instructions.
One of the challenges we had to face when implementing SIMD in Ion was that our register allocator, which is the algorithm choosing where values should live (e.g. in a register or on the stack) in JIT code, didn’t know about registers with widths larger than 64 bits — the size of a double floating-point value. Also, SIMD instructions have expectations on stack alignment, so we needed to adjust most trampolines code sections of the engine to have them respect the stack requirements.
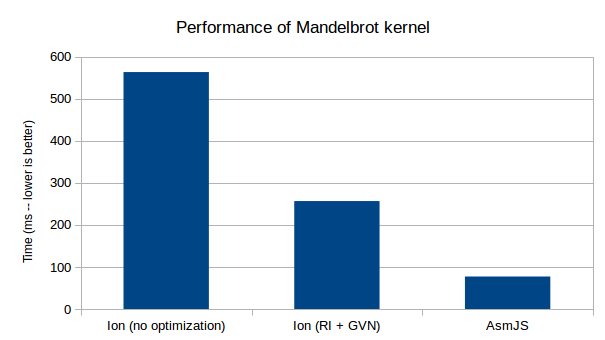
With these changes completed, Ion could successfully execute SIMD code. However, compared to Odin, the performance was still quite slow. Odin uses the same backend code as Ion, so it serves as a rough theoretical lower-bound for Ion. Here is a graph comparing performance between the polyfill, Ionmonkey at this point, and OdinMonkey.

Recover instructions & Global Value Numbering
The reason why SIMD instructions were not extremely fast is ultimately because JavaScript has dynamic types. We use Baseline whenever we don’t know anything about what the types will be, or when we think we know something but then find out that we were wrong. When the latter case happens, we have to bail out of the code that Ion produced under the now-wrong assumption, and start back over again in Baseline. This means we need to have support for capturing values from Ion execution and packaging them up to work in Baseline code. Any fallible instruction contains an implicit path back to resume the execution in Baseline. Baseline primarily operates on boxed objects, so that it can be independent of the actual dynamic types. Consequently, when Ion bails out into Baseline, it must box up any live SIMD values into objects.
Fortunately for us, this was addressed by the addition of Recover Instructions last June. Recover Instructions are used to move any instruction unused by IonMonkey to the implicit paths to Baseline. In this case, it means that we can box the SIMD values only on the fallible (extremely cold) paths, preventing lot of allocations in other code paths.
Combined with Global Value Numbering — an algorithm which can find redundant code and simplify operations sequences — we can remove any sequences where one SIMD instruction result is boxed and the next instruction unboxes it. Once again, this optimization prevents SIMD object allocations by removing uses of the boxed values.
Here is the same Mandelbrot benchmark (without the slow polyfill version, so that we can better compare Ion and Odin). The new Ion bar represents the state of performance in Ion after the two previously mentioned optimizations.
Eager Unboxing
In fact the above solution applies to any known objects/array, with the help of Escape Analysis and Scalar Replacement but it is not perfect, and it might still be slower compared to the asm.js version of the same benchmark.
The problem with any object is that the allocation-site of any object is observable. Thus we can detect whether an object is the same that the one we’ve used before, or if it was duplicated. The strict equality / difference operators (=== and !==) can distinguish between two objects pointers. Thus if you call a black-box function named “id” which returns a similar object, you can determine if the object is the same as the input of the function or a different one.
// Returns the initial object if it has some properties
// or a new one otherwise.
function id (x) {
if (Object.getOwnPropertyNames(x).length)
return x;
return {};
}
var o1 = {};
console.log(o1 === id(o1)); // false, different objects
var o2 = {js_is_awesome: true};
console.log(o2 === id(o2)); // true, same object
Fortunately, the specification intends that SIMD values are implemented as first class-citizen values, not as objects. This means that an object is defined by its content and not by its container. Thus, an optimizing compiler such as IonMonkey can eagerly unbox the content of the value and box the content before it exits. As a matter of fact, the last object allocations caused by boxing are removed by eagerly unboxing any potential SIMD values, and boxing them as late as possible.
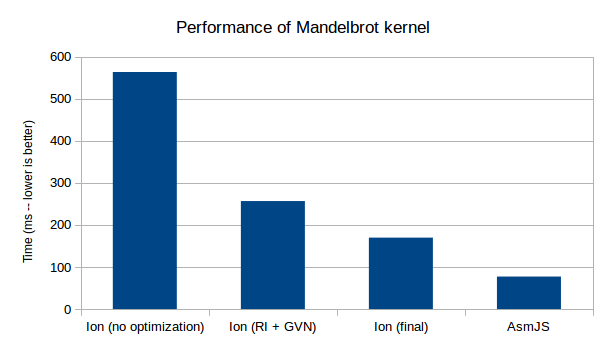
Here is the current state of performance. Ion (final) contains all optimizations, including the one described in this paragraph. Ion’s execution time of this benchmark is in the ballpark of twice the time spent in asm.js execution, which is really nice.
Future work
All the SIMD optimization work, be it in asm.js or in “regular” JS, has been done only for the x86 and x64 platforms, as a proof-of-concept. It is already available in Nightly builds of Firefox. That work needs to be extended to other platforms, in particular ARM, so that the phones running under Firefox OS benefit from fast SIMD.
If you look closely at the specification, you’ll see that there are more types than the two mentioned earlier: float64x2 (two double floating-point values packed), int16x8 (eight integers of 16 bits) and int8x16 (sixteen integers of 8 bits). Future work will include mapping these new types and their operations to assembly instructions as well, in Odin and Ion.
Currently, our SIMD values are represented by objects in the interpreter, even though the specification expects them to be instances of value types. In particular, they should have value identity, which means that two SIMD values are the same if, and only if, their components are the same, pairwise. This isn’t true as of today in our implementation, as SIMD values are represented by objects and thus have object identity in the interpreter. This depends on the value types specification moving forward in TC39 and this specification being implemented in Spidermonkey.
As compiler writers, we’re naturally thinking about auto-vectorization too, where the compiler converts regular scalar code into SIMD code, either by restructuring loops, or by finding concurrency among groups of statements. Implementing SIMD.js support today will actually make it easier for us to start experimenting with auto-vectorization in the future, since all the backend support for SIMD will already be in place.
And lastly, the SIMD.js spec itself is still in development, and we are continuing to work with others on the SIMD.js project to propose SIMD.js to TC-39 for standardization.
This blog post has been co-written by Nicolas B. Pierron (:nbp) and Benjamin Bouvier (:bbouvier). Thanks to the blog post reviewers, to all the SpiderMonkey team who has helped reviewing the SIMD patches and to the contributors who helped implementing features!
Edward Kmett wrote on
:
wrote on
:
Benjamin Bouvier wrote on
:
wrote on
: