TL;DR: Firefox’s built-in PDF viewer is on track to benefit from additional large reductions in memory consumption when Firefox 33 is released in mid-October.
Earlier this year I made some major improvements to the memory usage and speed of pdf.js, Firefox’s built-in PDF viewer. At the time I was quite pleased with myself. I had picked all the low-hanging fruit and reached a point of diminishing returns.
Some unexpected measurements
Shortly after that, while on a plane I tried pdf.js on my Mac laptop. I was horrified to find that memory usage was much higher than on the Linux desktop machine on which I had done my optimizations. The first document I measured made Firefox’s RSS (resident set size, a.k.a. physical memory usage) peak at over 1,000 MiB. The corresponding number on my Linux desktop had been 400 MiB! What was going on?
The short answer is “canvases”. pdf.js uses HTML canvas elements to render each PDF page. These can be millions of pixels in size, and each canvas pixel takes 32-bits of RGBA data. But on Linux this data is not stored within the Firefox process. Instead, it gets passed to the X server. Firefox’s about:memory page does report the canvas usage under the “canvas-2d-pixels” and “gfx-surface-xlib” labels, but I hadn’t seen those — during my optimization work I had only measured the RSS of the Firefox process. RSS is usually the best single number to focus on, but in this case it was highly misleading.
In contrast, on Mac the canvas data is stored within the process, which is why Firefox’s RSS is so much higher on Mac. (There’s also the fact that my MacBook has a retina screen, which means the canvases used have approximately four times as many pixels as the canvases used on my Linux machine.)
Fixing the problem
It turns out that pdf.js was intentionally caching an overly generous number of canvases (20) and then unintentionally failing to dispose of them in a timely manner. This could result in hundreds of canvases being held onto unnecessarily if you scrolled quickly through a large document. On my MacBook each canvas is over 20 MiB, so the resultant memory spike could be enormous.
Happily, I was able to fix this behaviour with four tiny patches. pdf.js now caches only 10 canvases, and disposes of any excess ones immediately.
Measurements
I measured the effects of both rounds of optimization on the following three documents on my Mac.
- TraceMonkey: This is an academic paper about the TraceMonkey JIT compiler. It’s a 14 page Latex document containing several pictures and graphs.
- Telefónica: This is the 2009 annual report from Telefónica. It’s a 122 page full-colour document with many graphs, tables and pictures.
- Decontamination: This is an old report about the decontamination of an industrial site in New Jersey. It’s a 226 page scan of a paper document that mostly consists of black and white typewritten text and crude graphs, with only few pages featuring colour.
For each document, I measure the peak RSS while scrolling quickly from the first page to the last by holding down the “fn” and down keys at the same time. Although this is a stress test, it’s not unrealistic; it’s easy to imagine people quickly scrolling through 10s or even 100s of pages of a PDF to find a particular page.
I did this three times for each document and picked the highest value. The results are shown by the following graph. The “Fx28” bars show the original peak RSS values; the “Fx29” bars show the peak RSS values after my first round of optimizations; and the “Fx33” bars show the peak RSS values after my second round of optimizations.
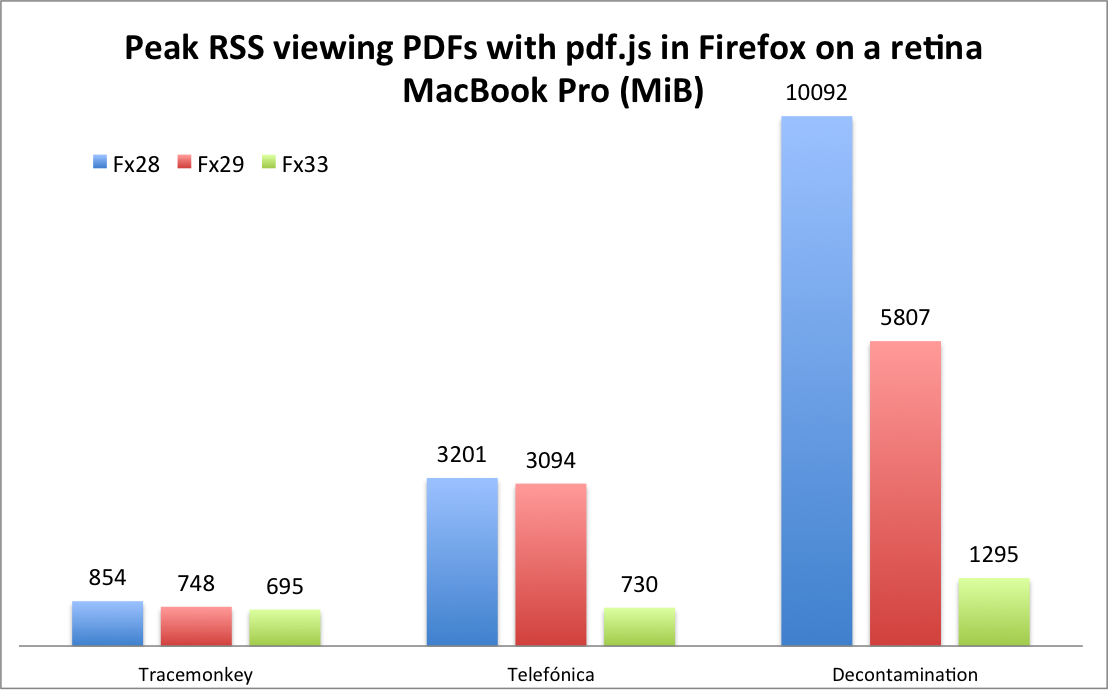
Comparing Firefox 28 and Firefox 33, the reductions in peak RSS for the three documents are 1.2x, 4.4x, and 7.8x. It makes sense that the relative improvements increase with the length of the documents.
Despite these major improvements, pdf.js still uses substantially more memory than native PDF viewers. So we need to keep chipping away… but it’s also worth recognizing how far we’ve come.
Status
These patches have landed in the master pdf.js repository. They have not yet imported into Firefox’s code, but this will happen at some point during the development cycle for Firefox 33. Firefox 33 is on track to be released in mid-October.
24 replies on “An even slimmer pdf.js”
You mention Linux but not BSD. Does FreeBSD gain anything from this improvement.
All platforms will benefit. Even Linux — even though the memory is not stored within the Firefox process on Linux, it’s still being used. The size of the improvement depends on the length of the documents you’re viewing, how quickly you scroll through them, and your screen resolution.
Does the Windows version store the canvases in the FF process or somewhere in OSland?
I suspect within the Firefox process, though I haven’t checked.
In terms of physical memory usage, it doesn’t make much difference whether Firefox is using lots of memory or directly causing another process to use lots of memory… if your machine starts to swap, performance will drop through the floor either way.
In terms of virtual memory usage, it could make a difference if you’re near the 2/3/4 GiB virtual address limit (the exact limit depends on your OS configuration).
With the standard windows version still 32bit, until e10s is finished having the allocations in the main FF process matters because on a medium/high end system the process memory limit would be hit well before the system as a whole runs out.
Yes, that’s what I was referring to in my last paragraph. But this second round of improvements means that the amount of memory used for canvases is much less than it used to be, so we’re much less likely to hit that limit.
Yes, I’d think that it can have a major impact on Windows as OOM is our largest stability issue right now, and this should improve *both* cases – both virtual and physical memory exhaustion is probably becoming harder to hit with pdf.js after those optimizations, so I’ll keep an eye open for this landing on our actual trees (making me somewhat wonder if we’d want to uplift hose “tiny patches” to 32 or even 31, actually).
Hello,
you mentioned that since canvases use a lot of memory PDF.js now limits the number of them to 10. I presume the measurements you did were displayed at 100% zoom level.
My question is, what about zooming in and the memory usage? Native readers are easily able to zoom to 6400% and perhaps beyond. I too have Retina display and PDF.js on Chrome has quite a bit of trouble dealing with such scales.
I also read that there is Google SoC project for an SVG backend, is Mozilla actively exploring this option as well?
Thanks for reply in advance!
I haven’t looked at zooming at all. Might be an interesting one to investigate — thanks for the suggestion!
Thanks to a recent PR, we now impose a limit on the size of canvases and use CSS zooming when they exceed that value.
See: https://github.com/mozilla/pdf.js/pull/4834
Jonas: doesn’t CSS zooming mean that the content of canvas becomes “pixelated” at higher zoom levels?
So this comes down to memory vs CPU – and in this case, what the user actually does. What if a user scrolls between 2 pages rapidly but there are 10 pages in between, wouldn’t this result in severe cache drops and excessive re-rendering of the 2 pages a user is interested in? How does this impact energy/battery because of the CPU having to re-render?
The use case might behave worse, yes. With a 20 page cache, you could posit a use cases where the two pages of interest are 20 pages apart. Software is full of trade-offs, and I think these changes benefit the common cases.
How about compress the cached canvas with some fast straight forward lossless compression algrithm? 20MB of raw pixel should be compressed well.
Nick, it is utterly important to note that > 80% of all Firefox users use Windows. The lack of attention that the Windows platform gets within the Firefox developer community is appalling. We need to make concious efforts to dogfood what our users are getting.
While working on the front-end of Firefox, it is very easy for me to see that Linux has the smoothest and most fluid UI animations of all platforms, yet we use the same front-end styling, animations, and behaviors between the platforms.
Please continue your great work but at the same time, can you start using a Windows machine as your default environment? Fixing platform issues on Linux has a good chance of not helping the vast majority of the poeple that use Firefox, as this post shows.
The problem is that android, Firefox OS, Linux and osx share many similarities. The future of Mozilla is mobile, and that future doesn’t look to include Windows.
That aside, you’re looking at this ONE developer whose desktop is Linux. Look at the rest of Mozilla, and indeed their benchmarks, and you’ll see that they optimize against windows more than anywhere else.
Lastly, did you not read what he said this will benefit everyone? He did the appropriate thing and tasted his changes on another platform and found issues… and fixed them.
Except for the guys hacking on D2D/D3D I’m only ever seeing Linux and OSX, especially in the UI/UX- and memory-department.
Got some links?
Yeah, haven’t done any tests, but doing some run-length encoding compression should be both fast enough, and provide decent compression for most use-cases.
What uses more CPU cycles though, redrawing or uncompressing it?
At $JOB we use X terminals with a beefy Linux server, and we ran into this problem: whenever users viewed a PDF in Firefox, the canvases would be offloaded into the X server, meaning over the network and into the limited RAM of the terminals, which would often run out of memory, aborting the user’s session. I’ll be looking forward to the fix making it into the Firefox ESR release. Until then we’ve disabled pdf.js and reverted to Adobe Reader (ugh).
I wonder what happens when you set gfx.xrender.enabled to false.
It keeps the canvas memory in-process! Thanks, I didn’t know about that option.
If you can wait until 38 ESR…
700 mb to render freaking PDF?
Still looks unusable mess as far as my non-quantum non-64GB non-100core computer is concerned.