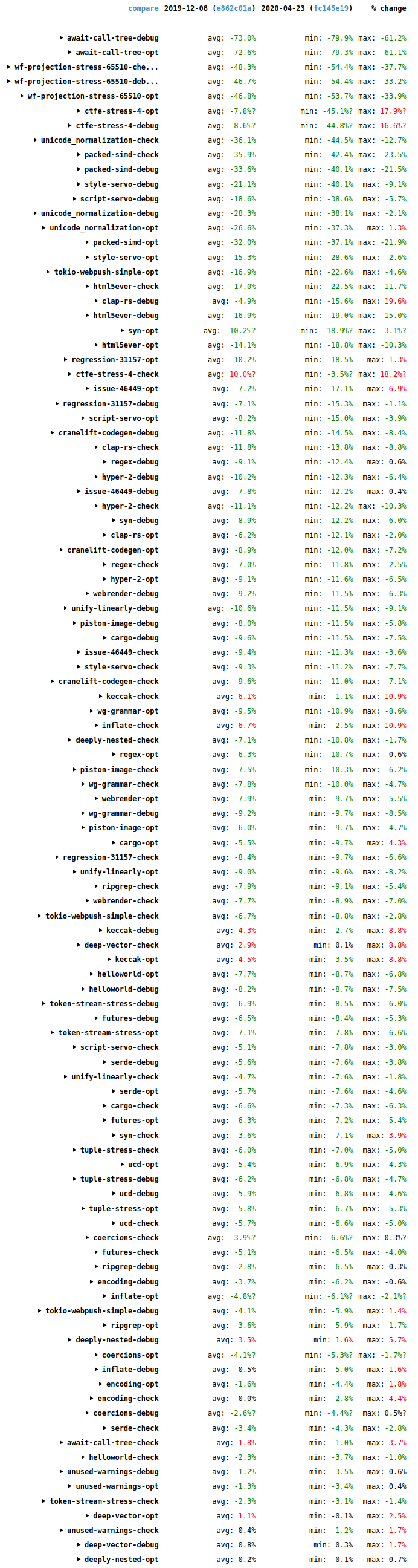
I recently undertook a project to improve the stack fixing tools used for Firefox. This has resulted in some large performance wins (e.g. 10x-100x) and a significant improvement in code quality. The story involves Rust, Python, executable and debug info formats, Taskcluster, and many unexpected complications.
What is a stack fixer?
Within the Firefox code base, a stack fixer is a program that post-processes (“fixes”) the stack frames produced by MozFormatCodeAddress(), which often lack one or more of: function name, file name, or line number. It reads debug info from binaries (libraries and executables) to do so. It reads from standard input and writes to standard output. Lines matching the special stack frame format are modified appropriately. For example, a line like this in the input that names an executable or library:
#01: ???[tests/example +0x43a0]
is changed to a line in the output that names a function, source file, and line number:
#01: main (/home/njn/moz/fix-stacks/tests/example.c:24)
Lines that do not match the special stack frame format are passed through unchanged.
This process is sometimes called “symbolication”, though I will use “stack fixing” in this post because that’s the term used within the Firefox code base.
Stack fixing is used in two main ways for Firefox.
- When tests are run on debug builds, a stack trace is produced if a crash or assertion failure happens.
- The heap profiling tool DMD records many stack traces at heap allocation points. The stack frames from these stack traces are written to an output file.
A developer needs high-quality stack fixing for the stack traces to be useful in either case.
That doesn’t sound that complicated
The idea is simple, but the reality isn’t.
- The debug info format is different on each of the major platforms: Windows (PE/PDB), Mac (Mach-O), and Linux (ELF/DWARF).
- We also support Breakpad symbols, a cross-platform debug info format that we use on automation. (Using it on local builds is something of a pain.)
- Each debug info format is complicated.
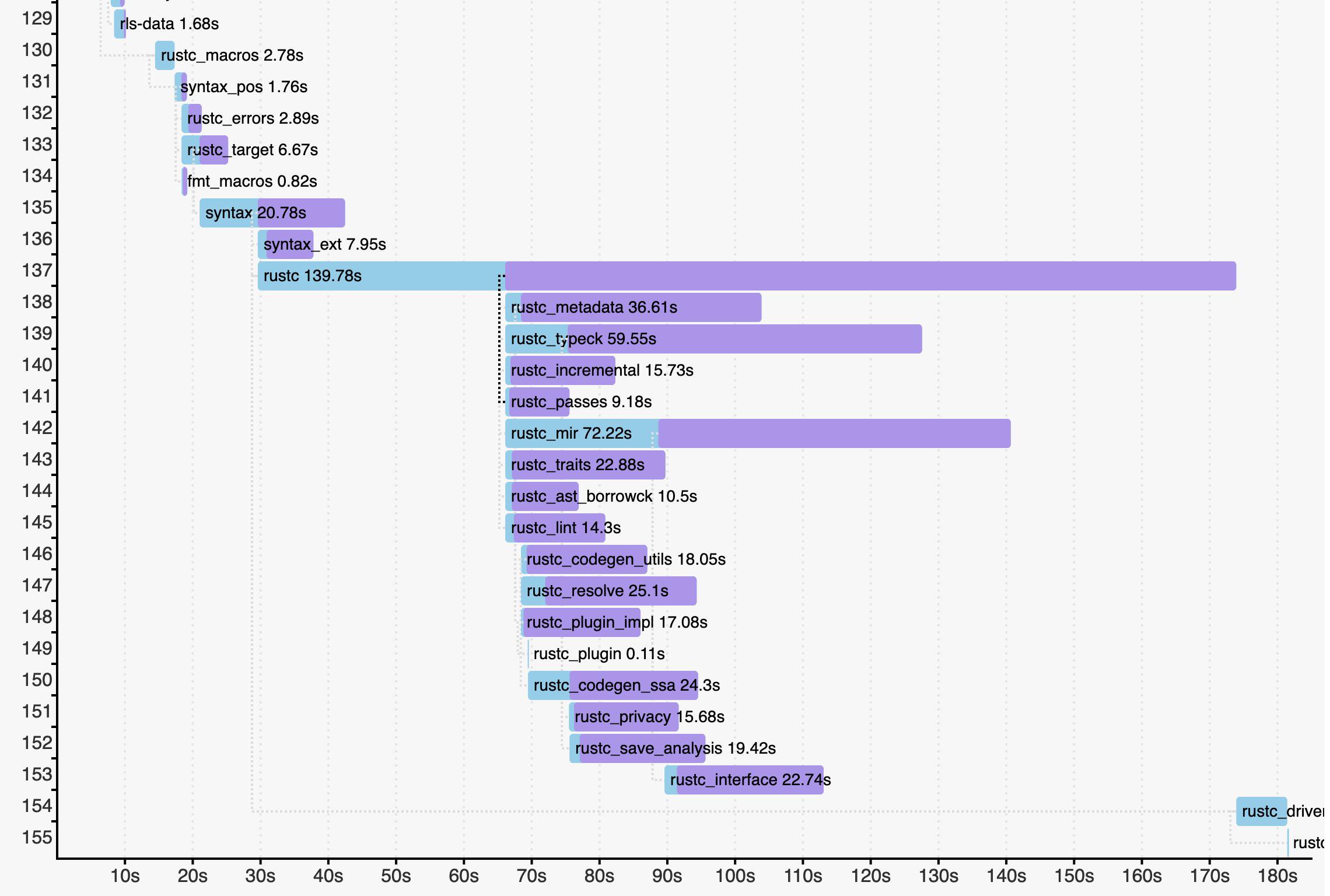
- Firefox is built from a number of libraries, but most of its code is in a single library called libxul, whose size ranges from 100 MiB to 2 GiB, depending on the platform and the particular kind of build. This stresses stack fixers.
Before I started this work, we had three different Python scripts for stack fixing.
fix_linux_stack.py: This script does native stack fixing on Linux. It farms out most of the work to addr2line, readelf, and objdump.fix_macosx_stack.py: This script does native stack fixing on Mac. It farms out most of the work to atos, otool, and c++filt.fix_stack_using_bpsyms.py: This script does stack fixing using Breakpad symbols. It does the work itself.
Note that there is no fix_windows_stack.py script. We did not have a native stack-fixing option for Windows.
This was an inelegant mishmash. More importantly, the speed of these scripts was poor and highly variable. Stack fixing could take anywhere from tens of seconds to tens of minutes, depending on the platform, build configuration, and number of stack frames that needed fixing. For example, on my fast 28-core Linux box I would often have to wait 20 minutes or more to post-process the files from a DMD run.
One tool to rule them all
It would be nice to have a single program that could handle all the necessary formats. It would also be nice if it was much faster than the existing scripts.
Fortunately, the Symbolic Rust crate written by Sentry provided the perfect foundation for such a tool. It provides the multi-platform debug info functionality needed for stack fixing, and also has high performance. In November last year I started a project to implement a new stack fixer in Rust, called fix-stacks.
Implementing the tool
First I got it working on Linux. I find Linux is often the easiest platform to get new code working on, at least partly because it’s the platform I’m most familiar with. In this case it was also helped by the fact that on Linux debug info is most commonly stored within the binary (library or executable) that it describes, which avoids the need to find a separate debug info file. The code was straightforward. The Symbolic crate did the hard part of reading the debug info, and my code just had to use the APIs provided to iterate over the parsed data and build up some data structures that could then be searched.
Then I got it working on Windows. I find Windows is often the hardest platform to get new code working on, but that wasn’t the case here. The only complication was that Windows debug info is stored in a PDB file that is separate from the binary, but Symbolic has a function for getting the name of that file from the binary, so it wasn’t hard to add code to look in that separate file.
Then I got it working on Mac. This was by far the hardest platform, for two reasons. First, the code had to handle fat binaries, which contain code for multiple architectures. Fortunately, Symbolic has direct support for fat binaries so that wasn’t too bad.
Second, the normal approach on Mac is to read debug info from the files produced by dsymutil, in which the debug info is neatly packaged. Unfortunately, dsymutil is very slow and we try to avoid running it in the Firefox build system if possible. So I took an alternative approach: read the binary’s symbol table and then read debug info from the object files and archive files it mentions. I knew that atos used this approach, but unfortunately its source code isn’t available, so I couldn’t see exactly what it did. If I couldn’t get the approach working myself the whole project was at risk; a one-tool-to-rule-them-all strategy falls short it if doesn’t work on one platform.
I spent quite some time reading about the Mach-O file format and using the MachOView utility to inspect Mach-O binaries. Symbolic doesn’t provide an API for reading symbol tables, so I had to use the lower-level goblin crate for that part. (Symbolic uses goblin itself, which means that fix-stacks is using goblin both directly and indirectly.) First I got it working on some very small test files, then on some smaller libraries within Firefox, and finally (to great relief!) on libxul. At each step I had to deal with new complications in the file format that I hadn’t known about in advance. I also had to modify Symbolic itself to handle some edge cases in .o files.
After that, I got fix-stacks working on Breakpad symbols. This was more straightforward; the only tricky part was navigating the directory structure that Firefox uses for storing the Breakpad symbols files. (I found out the hard way that the directory structure is different on Windows.)
One final complication is that DMD’s output, which gets run through the stack fixer, is in JSON format. So fix-stacks has a JSON mode (enabled with --json) that does the appropriate things with JSON escape characters on both input and output. This took three attempts to get completely right.
The end result is a single program that can fix stacks on all four of the formats we need. The stack traces produced by fix-stacks are sometimes different to those produced by the old stack fixing scripts. In my experience these differences are minor and you won’t notice them if you aren’t looking for them.
Code size
The source code for the first version of fix-stacks, which only supported Linux, was 275 lines (excluding tests). The current version, with support for Windows, Mac, Breakpad symbols, and JSON handling, is 891 lines (excluding tests).
In comparison, the Symbolic crate is about 20,000 lines of Rust code in total (including tests), and the three sub-crates that fix-stacks uses (debuginfo, demangle, and common) are 11,400 lines of Rust code. goblin is another 18,000 lines of code. (That’s what I call “leveraging the ecosystem”!)
Beyond Symbolic and goblin, the only other external crates that fix-stacks uses are fxhash, regex, and serde_json.
Testing
Testing is important for a tool like this. It’s hard to write test inputs manually in formats like ELF/DWARF, PE/PDB, and Mach-O, so I used clang to generate inputs from some simple C programs. Both the C programs and the binary files generated from them are in the repository.
Some of the generated inputs needed additional changes after they were generated by clang. This is explained by the testing README file:
The stack frames produced by `MozFormatCodeAddress()` contain absolute paths
and refer to build files, which means that `fix-stacks` can only be sensibly
run on the same machine that produced the stack frames.
However, the test inputs must work on any machine, not just the machine that
produced those inputs. Furthermore, it is convenient when developing if all the
tests works on all platforms, e.g. the tests involving ELF/DWARF files should
work on Windows, and the tests involving PE/PDB files should work on Linux.
To allow this requires the following.
- All paths in inputs must be relative, rather than absolute.
- All paths must use forward slashes rather than backslashes as directory
separators. (This is because Windows allows both forward slashes and
backslashes, but Linux and Mac only allow forward slashes.) This includes the
paths in text inputs, and also some paths within executables (such as a PE
file's reference to a PDB file).
To satisfy these constraints required some hex-editing of the generated input files. Quoting the README again:
`example-windows.exe` and `example-windows.pdb` were produced on a Windows 10
laptop by clang 9.0 with this command within `tests/`:
```
clang -g example.c -o example-windows.exe
```
`example-windows.exe` was then hex-edited to change the PDB reference from the
absolute path `c:\Users\njn\moz\fix-stacks\tests\example-windows.pdb` to the
relative path `tests/////////////////////////////example-windows.pdb`. (The use
of many redundant forward slashes is a hack to keep the path the same length,
which avoids the need for more complex changes to that file.)
A hack, to be sure, but an effective one.
The steps required to produce the Mac test inputs were even more complicated because they involve fat binaries. I was careful to make that README file clearly describe the steps I took to generate all the test inputs. The effort has paid off multiple times when modifying the tests.
Integrating the tool
Once I had the fix-stacks working well, I thought that most of the work was done and integrating it into the Firefox build and test system would be straightforward. I was mistaken! The integration ended up being a similar amount of work.
First, I added three new jobs to Mozilla’s Taskcluster instance to build fix-stacks and make it available for downloading on Windows, Mac, and Linux; this is called a “toolchain”. This required making changes to various Taskcluster configuration files, and writing a shell script containing the build instructions. All of this was new to me, and it isn’t documented, so I had to cargo-cult from similar existing toolchains while asking lots of questions of the relevant experts. You can’t test jobs like these on your own machine so it took me dozens of “try” pushes to Mozilla’s test machines to get it working, with each push taking roughly 10 minutes to complete.
Then I added a wrapper script (fix_stacks.py) and changed the native stack fixing path in DMD to use it instead of fix_linux_stack.py or fix_macosx_stack.py. This took some care, with numerous try pushes to manually check that the stacks produced by fix_stacks.py were as good as or better than the ones produced by the old scripts. To do this manual checking I first had to deliberately break the DMD test, because the stacks produced are not printed in the test log when the test passes. I also had to update mach bootstrap so it would install a pre-built fix-stacks executable in the user’s .mozbuild directory, which was another unfamiliar part of the code for me. Plus I fixed a problem with the fix-stacks toolchain for Mac: the fix-stacks executable was being cross-compiled on a Linux machine, but some errors meant it was not actually cross-compiling, but simply building a Linux executable. Plus I fixed a problem with the fix-stacks toolchain for Windows: it was building a 64-bit executable, but that wouldn’t work on our 32-bit test jobs; cross-compiling a 32-bit Windows executable on Linux turned out to be the easiest way to fix it. Again, these toolchain fixes took numerous trial-and-error try pushes to get things working. Once it was all working, native stack fixing on Windows was available for DMD for the first time.
Then I changed the native stack fixing path in tests to use fix_stacks.py. This required some minor changes to fix_stacks.py‘s output, to make it more closely match that of the old scripts, to satisfy some tests. I also had to modify the Taskcluster configuration to install the fix-stacks executable in a few extra places; again this required some trial-and-error with try pushes. (Some of those modifications I added after my initial landing attempt was backed out due to causing failures in a tier 2 job that doesn’t run by default on try, *cough*.) At this point, native stack fixing on Windows was available for test output for the first time.
Then I re-enabled stack-fixing for local test runs on Mac. It had been disabled in December 2019 because fixing a single stack typically took at least 15 minutes. With fix_stacks.py it takes about 30 seconds, and it also now prints out a “this may take a while” message to prepare the user for their 30 second wait.
Along the way, I noticed that one use point of the old stack fixing scripts, in automation.py.in, was dead code. Geoff Brown kindly removed this dead code.
Then I changed the Breakpad symbols stack fixing path in DMD to use fix_stacks.py, which was simple.
And then Henrik Skupin noticed that the fix-stacks executable wasn’t installed when you ran mach bootstrap for artifact builds, so I fixed that.
And then I was told that I had broken the AWSY-DMD test jobs on Windows. This wasn’t noticed for weeks because those jobs don’t run by default, and to run them on try you must opt into the “full” job list, which is unusual. The problem was some gnarly file locking caused by the way file descriptors are inherited when a child process is spawned on Windows in Python 2; working this out took some time. (It wouldn’t be a problem on Python 3, but unfortunately this code is Python 2 and that cannot be easily changed.) I thought I had a fix, but it caused other problems, and so I ended up disabling stack fixing on Windows for this job, which was a shame, but put us back where we started, with no stack fixing on Windows for that particular job.
And then I changed the Breakpad symbols stack fixing path in tests to use fix_stacks.py, which seemed simple. But it turns out that tests on Android partly run using code from the current Firefox repository, and partly using code from the “host utils”, which is a snapshot of the Firefox repository from… the last time someone updated the snapshot. (This has something to do with part of the tests actually taking place on Linux machines; I don’t understand the details and have probably mis-described the setup.) The host utils in use at the time was several months old and lacked the fix_stacks.py script. So Andrew Erickson kindly updated the host utils for me. And then I fixed a few more Taskcluster configuration issues, and then the “simple” fix could land. And then I fixed another configuration issues that showed up later, in a follow-up bug.
And then I removed the old stack fixing scripts because they weren’t being used any more.
And then I found a better solution to the Windows + Python 2 file descriptor issue, allowing me to re-enable stack fixing for the Windows AWSY-DMD job. (With another host utils update, to keep the Android tests working.)
And then I updated all the online documentation I could find that referred to the old scripts, all of it on MDN.
And then I closed the meta-bug that had been tracking all of this work. Hooray!
And then I was told of another obscure test output issue relating to web platform tests, which I have not yet landed a fix for. One lesson here is that changing code that potentially affects the output of every test suite is a fraught endeavour, with the possibility of a long tail of problems showing up intermittently.
Performance
I did some speed and peak memory measurements on the two common use cases: fixing many stack frames in a DMD file, and fixing a single stack trace from an assertion failure in a test. The machines I used are: a fast 28-core Linux desktop machine, a 2019 16-inch 8-core MacBook Pro, and an old Lenovo ThinkPad Windows laptop. The fix-stacks executable is compiled with LTO, because I found it gives speed-ups of up to 30%.
First, the following measurements are for fixing a DMD output file produced by an optimized Firefox build, old vs. new.
- Linux native: 4m44s / 4.8 GB vs. 21s / 2.4 GB
- Mac native: 15m47s / 1.0 GB vs. 31s / 2.4 GB
- Windows native: N/A vs. 29s / 2.6 GB
- Linux Breakpad symbols: 25s / 2.1 GB vs. 13s / 0.6 GB
(Each platform had a different input file, with some variations in the sizes, so cross-platform comparisons aren’t meaningful.)
On Linux we see a 13x speed-up, and I have seen up to 100x improvements on larger inputs. This is because the old script started quickly, but then each additional stack frame fixed was relatively slow. In comparison, the new script has a slightly higher overhead at start-up but then each additional stack frame fixed is very fast. Memory usage is halved, but still high, because libxul is so large.
On Mac the new script is 30x faster than the old script, but memory usage is more than doubled, interestingly. atos must have a particularly compact representation of the data.
On Windows we couldn’t natively fix stacks before.
For Breakpad symbols we see a 2x speed-up and peak memory usage is less than one-third.
Second, the following measurements are for fixing a single stack trace produced by a debug Firefox build, old vs. new.
- Linux native: 9s / 1.5 GB vs. 13s / 2.5 GB
- Mac native: 15m01s / 1.1 GB vs. 27s / 2.6 GB
- Win native: N/A vs. 30s / 3.2 GB
- Linux Breakpad symbols: 27s / 3.5 GB vs. 13s / 1.1 GB
On Linux, both speed and peak memory usage are somewhat worse. Perhaps addr2line is optimized for doing a small number of lookups.
On Mac the new script is again drastically faster, 33x this time, but memory usage is again more than doubled.
On Windows, again, we couldn’t natively fix stacks before.
For Breakpad symbols we again see a 2x speed-up and peak memory usage of less than one-third.
You might have noticed that the memory usage for the single stack trace was generally higher than for the DMD output. I think this is because the former is an optimized build, while the latter is a debug build.
In summary:
- The speed of native stack fixing is massively improved in many cases, with 10x-100x improvements typical, and slightly slower in only one case. This represents some drastic time savings for Firefox developers.
- The peak memory usage of native stack fixing is sometimes lower, sometimes higher, and still quite high in general. But the amount of memory needed is still much less than that required to compile Firefox, so it shouldn’t be a problem for Firefox developers.
- Native stack fixing is now possible on Windows, which makes things easier for Firefox developers on Windows.
- For Breakpad symbols stack fixing is 2x faster and takes 3x less memory. This represents some significant savings in machine time on automation, and will also reduce the chance of failures caused by running out of memory, which can be a problem in practice.
My experience with Rust
Much of my work using Rust has been on the Rust compiler itself, but that mostly involves making small edits to existing code. fix-stacks is the third production-quality Rust project I have written from scratch, the others being Firefox’s new prefs parser (just under 1000 lines of code) and counts (just under 100 lines of code).
My experience in all cases has been excellent.
- I have high confidence in the code’s correctness, and that I’m not missing edge cases that could occur in either C++ (due to lack of safety checks) or Python (due to dynamic typing).
- The deployed code has been reliable.
- Rust is a very pleasant language to write code in: expressive, powerful, and many things just feel “right”.
- I have been writing C++ a lot longer than Rust but I feel more competent and effective in Rust, due to its safety and expressiveness.
- Performance is excellent.
- As mentioned above, the entire
fix-stacks project wouldn’t have happened without the third-party Symbolic crate.
Rust gives me a feeling of “no compromises” that other languages don’t.
Conclusion
Stack fixing is much better now, and it took more work than I expected!
Many thanks to Mike Hommey, Eric Rahm, and Gabriele Svelto for answering lots of questions and reviewing many patches along the way.