I last wrote in October about my work on speeding up the Rust compiler. With the year’s end approaching, it’s time for an update.
Doc comments
#65750: Normal comments are stripped out during parsing and not represented in the AST. But doc comments have semantic meaning (`/// blah` is equivalent to the attribute #[doc="blah"]) and so must be represented explicitly in the AST. Furthermore:
- In a multi-line doc comment using
///or//!comment markers every separate line is treated as a separate attribute; - Multi-line doc comments using
///and//!markers are very common, much more so than those using/** */or/*! */markers, particularly in the standard library where doc comment lines often outnumber code lines; - The AST representation of attributes is quite expensive, partly because it retains the original tokens for complex reasons involving procedural macros.
As a result, doc comments had a surprisingly high cost. This PR introduced a special, cheaper representation for doc comments, giving wins on many benchmarks, some in excess of 10%.
Token streams
#65455: This PR avoided some unnecessary conversions from TokenTree type to the closely related TokenStream type, avoiding allocations and giving wins on many benchmarks of up to 5%. It included one of the most satisfying commits I’ve made to rustc.
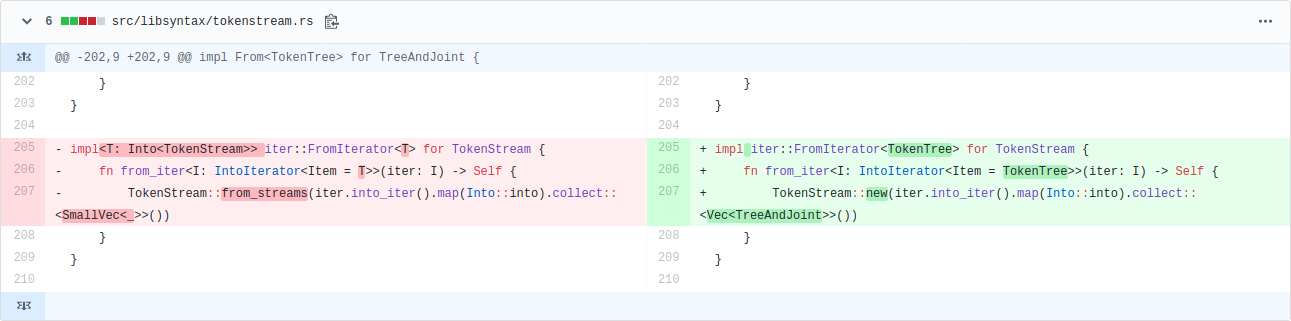
Up to 5% wins by changing only three lines. But what intricate lines they are! There is a lot going on, and they’re probably incomprehensible to anyone not deeply familiar with the relevant types. My eyes used to just bounce off those lines. As is typical for this kind of change, the commit message is substantially longer than the commit itself.
It’s satisfying partly because it shows my knowledge of Rust has improved, particularly Into and iterators. (One thing I worked out along the way: collect is just another name for FromIterator::from_iter.) Having said that, now that a couple of months have passed, it still takes me effort to remember how those lines work.
But even more so, it’s satisfying because it wouldn’t have happened had I not repeatedly simplified the types involved over the past year. They used to look like this:
pub struct TokenStream { kind: TokenStreamKind };
pub enum TokenStreamKind {
Empty,
Tree(TokenTree),
JointTree(TokenTree),
Stream(RcVec<TokenStream>),
}
(Note the recursion!)
After multiple simplifying PRs (#56737, #57004, #57486, #58476, #65261), they now look like this:
pub struct TokenStream(pub Lrc<Vec<TreeAndJoint>>);
pub type TreeAndJoint = (TokenTree, IsJoint);
pub enum IsJoint { Joint, NonJoint }
(Note the lack of recursion!)
I didn’t set out to simplify the type for speed, I just found it ugly and confusing. But now it’s simple enough that understanding and optimizing intricate uses is much easier. When those three lines appeared in a profile, I could finally understand them. Refactoring FTW!
(A third reason for satisfaction: I found the inefficiency using the improved DHAT I worked on earlier this year. Hooray for nice tools!)
#65641: This was a nice follow-on from the previous PR. TokenStream had custom impls of the RustcEncodable/RustcDecodable traits. These were necessary when TokenStream was more complicated, but now that it’s much simpler the derived impls suffice. As well as simplifying the code, the PR won up to 3% on some benchmarks because the custom impls created some now-unnecessary intermediate structures.
#65198: David Tolnay reported that basic concatenation of tokens, as done by many procedural macros, could be exceedingly slow, and that operating directly on strings could be 100x faster. This PR removed quadratic behaviour in two places, both of which duplicated a token vector when appending a new token. (Raise a glass to the excellent Rc::make_mut function, which I used in both cases.) The PR gave some very small (< 1%) speed-ups on the standard benchmarks but sped up a microbenchmark that exhibited the problem by over 1000x, and made it practical for procedural benchmarks to use tokens. I also added David’s microbenchmark to rustc-perf to avoid future regressions.
unicode_normalization
#65260: This PR added a special-case check to skip an expensive function call in a hot function, giving a 7% win on the unicode_normalization benchmark.
#65480: LexicalResolver::iterate_until_fixed_point() was a hot function that iterated over some constraints, gradually removing them until none remain. The constraints were stored in a SmallVec and retain was used to remove the elements. This PR (a) changed the function so it stored the constraints in an immutable Vec and then used a BitSet to record which which constraints were still live, and (b) inlined the function at its only call site. These changes won another 7% on unicode_normalization, but only after I had sped up BitSet iteration with some micro-optimizations in #65425.
#66537: This PR moved an expensive function call after a test and early return that is almost always taken, giving a 2% win on unicode_normalization.
Miscellanous
#66408: The ObligationForest type has a vector of obligations that it processes in a fixpoint manner. Each fixpoint iteration involves running an operation on every obligation, which can cause new obligations to be appended to the vector. Previously, newly-added obligations would not be considered until the next fixpoint iteration. This PR changed the code so it would consider those new obligations in the iteration in which they were added, reducing the number of iterations required to reach a fixpoint, and winning up to 8% on a few benchmarks.
#66013: The Rust compiler is designed around a demand-driven query system. Query execution is memoized: when a query is first invoked the compiler will perform the computation and store the result in a hash table, and on subsequent invocations the compiler will return the result from the hash table. For the parallel configuration of rustc this hash table experiences a lot of contention, and so it is sharded; each query lookup has two parts, one to get the shard, and one within the shard. This PR changed things so that the key was only hashed once and the hash value reused for both parts of the lookup, winning up to 3% on the single-threaded configuration of parallel compiler. (It had no benefit for the non-parallel compiler, which is what currently ships, because it does not use sharding.)
#66012: This PR removed the trivial_dropck_outlives query from the query system because the underlying computation is so simple that it is faster to redo it whenever necessary than to look up the result in the query hash table. This won up to 1% on some benchmarks, and possibly more for the parallel compiler, due to the abovementioned contention over the query hash table.
#65463: The function expand_pattern() caused many arena allocations where a 4 KiB arena chunk was allocated that only ever held a single small and short-lived allocation. This PR avoided these, reducing the number of bytes allocated by up to 2% for various benchmarks, though the effect on runtime was minimal.
#66540 – This PR changed a Vec to a SmallVec in Candidate::match_pairs, reducing allocation rates for a tiny speed win.
symbols
The compiler has an interned string type called Symbol that is widely used to represent identifiers and other strings. The compiler also had two variants of that type, confusingly called InternedString and LocalInternedString. In a series of PRs (#65426, #65545, #65657, #65776) I removed InternedString and minimized the functionality and uses of LocalInternedString (and also renamed it as SymbolStr). This was made possible by Matthew Jasper’s work eliminating gensyms. The changes won up to 1% on various benchmarks, but the real benefit was code simplicity, as issue #60869 described. Like the TokenStream type I mentioned above, these types had annoyed me for some time, so it was good to get them into a nicer state.
Progress
The storage of historical benchmark data changed recently, which (as far as I can tell) makes comparisons to versions earlier than early November difficult. Nonetheless, wall-time results for the past month (2019-11-07 to 2019-12-08) cover the second half of that period, and they are generally good, as the following screenshot shows.
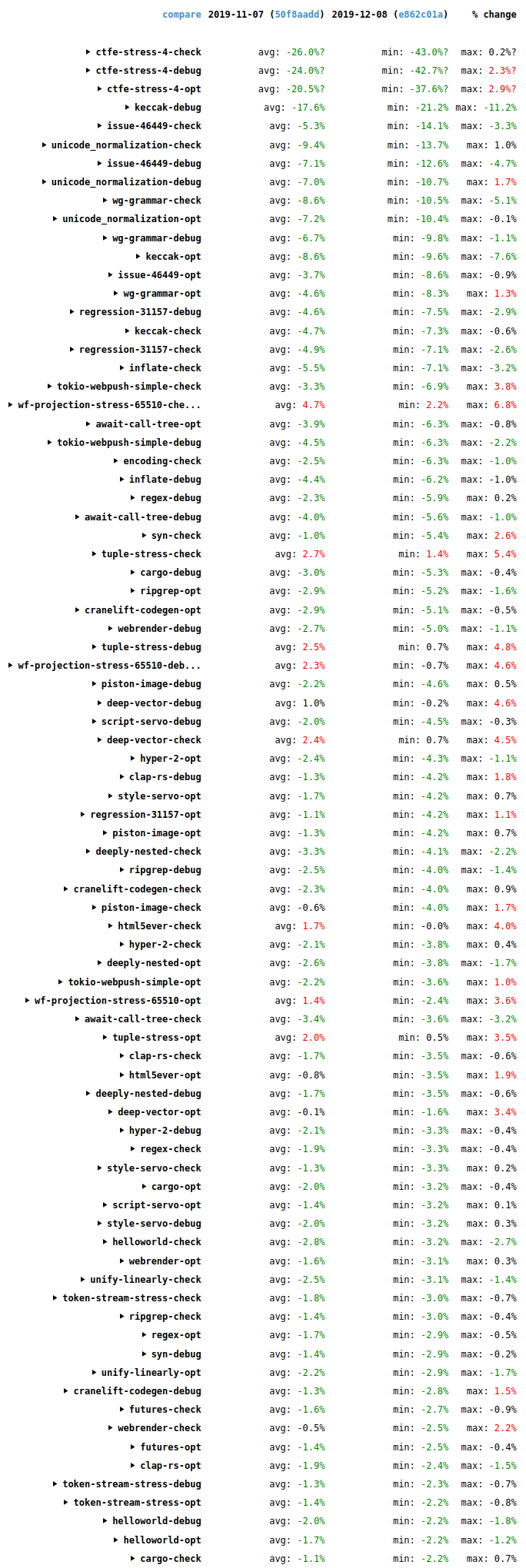
Overall, lots of improvements (green), some in the double digits, and only a small number of regressions (red). It’s a good trend, and it’s not just due to the PRs mentioned above. For example, MIR constant propagation won 2-10% in a lot of cases. It duplicates an optimization that LLVM also does, but performs it earlier in the pipeline when there’s less code. This saves time because it makes LLVM’s job easier, and it also helps the code quality of debug builds where the LLVM constant propagation isn’t run.
Final words
All of the above improvements (and most of the ones in my previous posts) I found by profiling with Cachegrind, Callgrind, DHAT, and counts, but there are plenty of other profilers out there. I encourage anyone who has interest and even slight familiarity with profiling (or a willingness to learn) to give it a try. The Rust compiler is an easy target, profiling-wise, because it’s a batch program that is mostly single-threaded and almost deterministic. (Compare it to Firefox, for example, which is interactive, multi-threaded, and highly non-deterministic.) Give it a go!
One reply on “How to speed up the Rust compiler one last time in 2019”
Thanks for making Rust so great!