In July I wrote about my efforts to speed up the Rust compiler in 2019. I also described how the Rust compiler has gotten faster in 2019, with compile time reductions of 20-50% on most benchmarks. Now that Q3 is finished it’s a good time to see how things have changed since then.
Speed improvements in Q3 2019
The following image shows changes in time taken to compile many of the standard benchmarks used on the Rust performance tracker. It compares a revision of the the compiler from 2019-07-23 with a revision of the compiler from 2019-10-09.
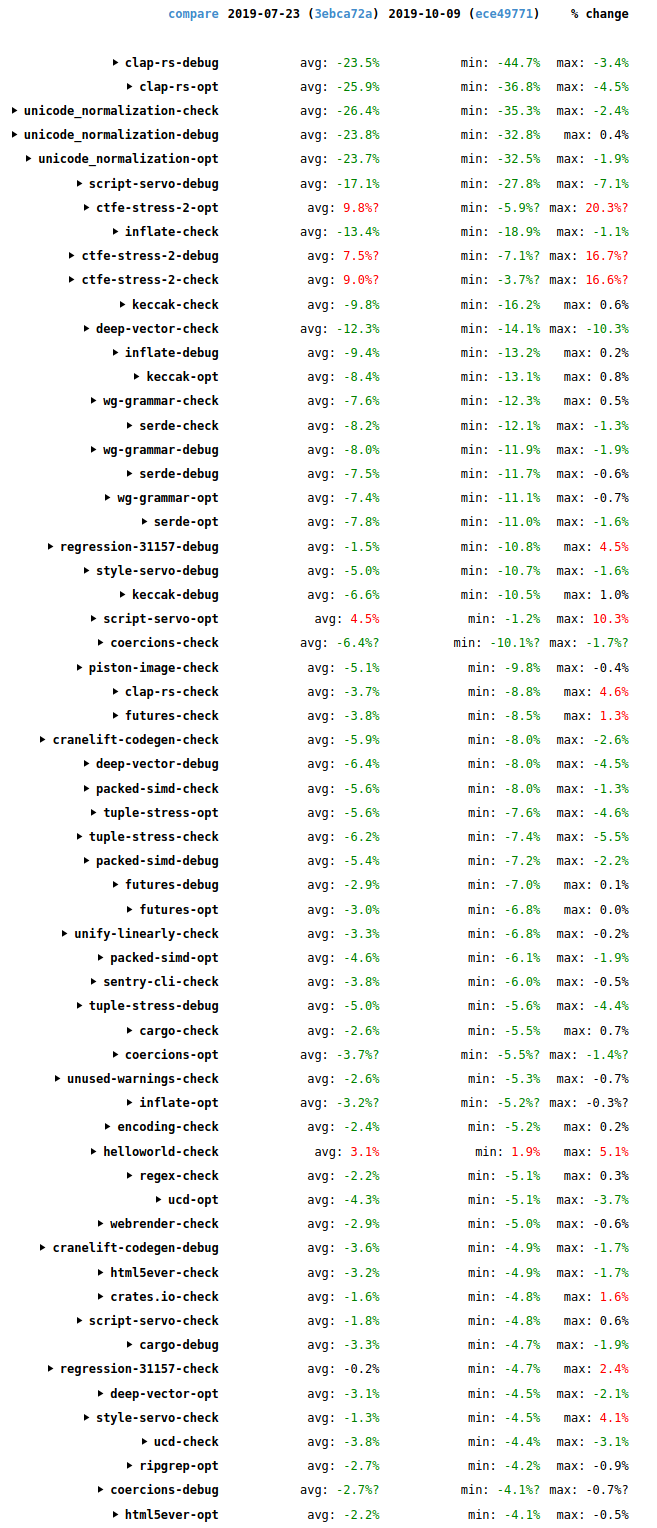
These are the wall-time results. There are three different build kinds measured for each one: a debug build, an optimized build, and a check build (which detects errors but doesn’t generate code). For each build kind there is a mix of incremental and non-incremental runs done. The numbers for the individual runs aren’t shown here but you can see them if you view the results directly on the site and click around. (Note that the site has had some reliability issues lately. Apologies if you have difficulty with that link.) The “avg” column shows the average change for those runs. The “min” and “max” columns show the minimum and maximum changes among those same runs.
There are a few regressions, mostly notably for the ctfe-stress-2 benchmark, which is an artificial stress test of compile-time function evaluation and so isn’t too much of a concern. But there are many more improvements, including double-digit improvements for clap-rs, inflate, unicode_normalization, keccak, wg-grammar, serde, deep-vector, script-servo, and style-servo. There have been many interesting things going on.
memcpy
For a long time, profilers like Cachegrind and Callgrind have shown that 2-6% of the instructions executed by the Rust compiler occur in calls to memcpy. This seems high! Curious about this, I modified DHAT to track calls to memcpy, much in the way it normally tracks calls to malloc.
The results showed that most of the memcpy calls come from a relatively small number of code locations. Also, all the memcpy calls involved values that exceed 128 bytes. It turns out that LLVM will use inline code for copies of values that are 128 bytes or smaller. (Inline code will generally be faster, but memcpy calls will be more compact above a certain copy size.)
I was able to eliminate some of these memcpy calls in the following PRs.
#64302: This PR shrank the ObligationCauseCode type from 56 bytes to 32 bytes by boxing two of its variants, speeding up many benchmarks by up to 2.6%. The benefit mostly came because the PredicateObligation type (which contains an ObligationCauseCode) shrank from 136 bytes to 112 bytes, which dropped it below the 128 byte memcpy threshold. I also tried reducing the size of ObligationCauseCode to 24 bytes by boxing two additional variants, but this had worse performance because more allocations were required.
#64374: The compiler’s parser has this type:
pub type PResult<'a, T> = Result<T, DiagnosticBuilder<'a>
It’s used as the return type for a lot of parsing functions. The T value is always small, but DiagnosticBuilder was 176 bytes, so PResult had a minimum size of 184 bytes. And DiagnosticBuilder is only needed when there is a parsing error, so this was egregiously inefficient. This PR boxed DiagnosticBuilder so that PResult has a minimum size of 16 bytes, speeding up a number of benchmarks by up to 2.6%.
#64394: This PR reduced the size of the SubregionOrigin type from 120 bytes to 32 bytes by boxing its largest variant, which sped up many benchmarks slightly (by less than 1%). If you are wondering why this type caused memcpy calls despite being less than 128 bytes, it’s because it is used in a BTreeMap and the tree nodes exceeded 128 bytes.
ObligationForest
One of the biggest causes of memcpy calls is within a data structure called ObligationForest, which represents a bunch of constraints (relating to type checking and trait resolution, I think) that take the form of a collection of N-ary trees. ObligationForest uses a single vector to store the tree nodes, and links between nodes are represented as numeric indices into that vector.
Nodes are regularly removed from this vector by a function called ObligationForest::compress. This operation is challenging to implement efficiently because the vector can contain thousands of nodes and nodes are removed only a few at a time, and order must be preserved, so there is a lot of node shuffling that occurs. (The numeric indices of all remaining nodes must be updated appropriately afterwards, which further constrains things.) The shuffling requires lots of swap calls, and each one of those does three memcpy calls (let tmp = a; a = b; b = tmp, more or less). And each node is 176 bytes! While trying to get rid of these memcpy calls, I got very deep into ObligationForest and made the following PRs that aren’t related to the copying.
#64420: This PR inlined a hot function, speeding up a few benchmarks by up to 2.8%. The function in question is indirectly recursive, and LLVM will normally refuse to inline such functions. But I was able to work around this by using a trick: creating two variants of the function, one marked with #[inline(always)] (for the hot call sites) and one marked with #[inline(never)] (for the cold call sites).
#64500: This PR did a bunch of code clean-ups, some of which helped performance to the tune of up to 1.7%. The improvements came from factoring out some repeated expressions, and using iterators and retain instead of while loops in some places.
#64545: This PR did various things, improving performance by up to 13.8%. The performance wins came from: combining a split parent/descendants representation to avoid frequent chaining of iterators (chained iterators are inherently slower than non-chained iterators); adding a variant of the shallow_resolve function specialized for the calling pattern at a hot call site; and using explicit iteration instead of Iterator::all. (More about that last one below.)
#64627: This PR also did various things, improving performance by up to 18.4%. The biggest improvements came from: changing some code that dealt with a vector to special-case the 0-element and 1-element cases, which dominated; and inlining an extremely hot function (using a variant of the abovementioned #[inline(always)] + #[inline(never)] trick).
These PRs account for most of the improvements to the following benchmarks: inflate, keccak, cranelift-codegen, and serde. Parts of the ObligationForest code was so hot for these benchmarks (especially inflate and keccak) that it was worth micro-optimizing them to the nth degree. When I find hot code like this, there are always two approaches: (a) try to speed it up, or (b) try to avoid calling it. In this case I did (a), but I do wonder if the users of ObligationForest could be more efficient in how they use it.
The above PRs are a nice success story, but I should also mention that I tried a ton of other micro-optimizations that didn’t work.
- I tried
drain_filterincompress. It was slower. - I tried several invasive changes to the data representation, all of which ended up slowing things down.
- I tried using
swap_and_removeinstead ofswapincompress, This gave speed-ups, but changed the order that predicates are processed in, which changed the order and/or contents of error messages produced in lots of tests. I was unable to tell if these error message changes were legitimate — some were simple, but some were not — so I abandoned all approaches that altered predicate order. - I tried boxing
ObligationForestnodes, to reduce the number of bytes copied incompress. It reduced the amount of copying, but was a net slowdown because it increased the number of allocations performed. - I tried inlining some other functions, for no benefit.
- I used
unsafecode to remove theswapcalls, but the speed-up was only 1% in the best case and I wasn’t confident that my code was panic-safe, so I abandoned that effort. - There were even a number of seemingly innocuous code clean-ups that I had to abandon because they hurt performance measurably. I think this is because the code is so hot in some benchmarks that even tiny changes can affect code generation adversely. (I generally use instruction counts rather than wall time to make these evaluations, because instruction counts have very low variance.)
Amusingly enough, the memcpy calls in compress were what started all this, and despite the big wins, I didn’t manage to get rid of them!
Inlining and code bloat
I mentioned above that in #64545 I got an improvement by replacing a hot call to Iterator::all with explicit iteration. The reason I tried this was that I looked at the implementation of Iterator::all and saw that it was surprisingly complicated: it wrapped the given predicate in a closure that
returned a LoopState, passed that closure to try_for_each which
wrapped the first closure in a second closure, and passed that second closure
to try_fold which did the actual iteration using the second
closure. Phew!
Just for kicks I tried replacing this complex implementation with the obvious, simple implementation, and got a small speed-up on keccak, which I was using for most of my performance testing. So I did the same thing for three similar Iterator methods (any, find and find_map), submitted #64572, and did a CI perf run. The results were surprising and extraordinary: 1-5% reductions for many benchmarks, but double-digits for some, and 20-50% reductions for some clap-rs runs. Uh, what? Investigation showed that the reduction came from LLVM doing less work during code generation. These functions are all marked with #[inline] and so the simpler versions result in less code for LLVM to process. Sure enough, the big wins all came in debug and opt builds, with little effect on check builds.
This surprised me greatly. There’s been a long-running theory that the LLVM IR produced by the Rust compiler’s front end is low quality, that LLVM takes a long time to optimize it, and more front-end optimization could speed up LLVM’s code generation. #64572 demonstrates a related, but much simpler prospect: we can speed up compilation by making commonly inlined library functions smaller. In hindsight, it makes sense that this would have an effect, but the size of the effect is nonetheless astounding to me.
But there’s a trade-off. Sometimes a simpler, smaller function is slower. For the iterator methods there are some cases where that is true, so the library experts were unwilling to land #64572 as is. Fortunately, it was possible to obtain much of the potential compile time improvements without compromising runtime.
- In #64600, scottmcm removed an aggressive specialization of
try_foldfor slices that had an unrolled loop that called the given closure four times. This got about 60% of the improvements of #64572. - In #64885, andjo403 simplified the four
Iteratormethods to calltry_folddirectly, removing one closure layer. This got about another 15% of the improvements of #64572.
I had a related idea, which was to use simpler versions for debug builds and complex versions for opt builds. I tried three different ways of doing this.
- Use
if cfg!(debug_assertions)within the method bodies. - Have two versions of each method, one marked with
#[cfg(debug_assertions)], the other marked with#[cfg(not(debug_assertions))]. - Mark each method with
#[cfg_attr(debug_assertions, inline)]so that the methods are inlined only in optimized builds.
None of these worked; they either had little effect or made things worse. I’m hazy on the details of how library functions get incorporated; maybe there’s another way to make this idea work.
In a similar vein, Alex Crichton opened #64846, which changes hashbrown (Rust’s hash table implementation) so it is less aggressive about inlining. This got some sizeable improvements on some benchmarks (up to 18% on opt builds of cargo) but also caused small regressions for a lot of other benchmarks. In this case, the balance between “slower hash tables” and “less code to compile” is delicate, and a final decision is yet to be made.
Overall, this is an exciting new area of investigation for improving Rust compile times. We definitely want new tooling to help identify which library functions are causing the most code bloat. Hopefully these functions can be tweaked so that compile times improve without hurting runtime performance much.
Miscellaneous
As well as all the above stuff, which all arose due to my investigations into memcpy calls, I had a few miscellaneous improvements that arose from normal profiling.
#65089: In #64673, simulacrum got up to 30% wins on the unicode_normalization benchmark by special-casing a type size computation that is extremely hot. (That benchmark is dominated by large match expressions containing many integral patterns.) Inspired by this, in this PR I made a few changes that moved the special case to a slightly earlier point that avoided even more unnecessary operations, for wins of up to 11% on that same benchmark.
#64949: The following pattern occurs in a few places in the compiler.
let v = self.iter().map(|p| p.fold_with(folder)).collect::<SmallVec<[_; 8]>>()
I.e. we map some values into a SmallVec. A few of these places are very hot, and in most cases the number of elements produced is 0, 1, or 2. This PR changed those hot locations to handle one or more of the 0/1/2 cases directly without using iteration and SmallVec::collect, speeding up numerous benchmarks by up to 7.8%.
#64801: This PR avoided a chained iterator in a hot location, speeding up the wg-grammar benchmark by up to 1.9%.
Finally, in #64112 I tried making pipelinined compilation more aggressive by moving crate metadata writing before type checking and borrow checking. Unfortunately, it wasn’t much of a win, and it would slightly delay error message emission when compiling code with errors, so I abandoned the effort.
4 replies on “How to speed up the Rust compiler some more in 2019”
> Unfortunately, it wasn’t much of a win, and it would slightly delay error message emission when compiling code with errors, so I abandoned the effort.
That seems like a win; optimizing for code that *doesn’t* have errors optimizes for the case of compiling dependencies.
It slightly improves some workloads and slightly hurts others. It wasn’t clear to me that this was a net benefit — evaluating the trade-off between those different workloads is difficult — so I did the conservative thing and left the code unchanged.
Incredible work! I’m extremely grateful there are people working hard to improve Rust compile times.
Thanks for posting this, it’s really interesting to follow