Editors Note: This is a guest post by Ashish Gaurav, Harsh Vardhan, and Rishabh Saxena
Maintaining a large number of servers and keeping them secure is a tough job! System administrators rely on tools like Puppet and Ansible to manage system configurations. However, they often lack the means of independently testing these systems to ensure expectations match reality.
ssh_scan was created in an effort to provide a “simple to configure and use” tool that fills this gap for system administrators and security professionals seeking to validate their ssh configurations against a predefined policy. It aims to provide control over what policies and configurations you self-identify as important.
As CS undergraduates, we had the opportunity to participate in the 2016-2017 edition of Mozilla Winter of Security (MWoS), where we volunteered to improve the scalability and feature set of ssh_scan.
The goal of the project was to improve the existing scanner to make securing your ssh servers easier. It scans ssh servers by initiating a remote unauthenticated connection, enumerates all the attributes about the service and compares them against a user defined policy. For providing a sane baseline policy recommendation for SSH configuration parameters the Mozilla OpenSSH Security Guide was used.
Early Work
Before we started working on the project, ssh_scan was a simple command-line tool. It had limited fingerprinting support and no logging capability. We started with introducing some key features to improve the CLI tool, like adding logging, making it multi-threaded, and extending its dev-ops usability. However, we really wanted to make the tool more accessible for everyone, so we decided to evolve ssh_scan into a web API. As soon as the initial CLI tool was leveled up, we moved on to architecture planning for the web API.
The API
Since ssh_scan is written in Ruby, we looked at different Ruby web frameworks to implement the web API. We finally settled on Sinatra, as it was a lightweight framework which gave us the power and flexibility to adapt and evolve quickly.
We started with providing a REST API around the existing command-line tool so that it could be integrated into the Mozilla Observatory as another module. Because the Observatory receives a large number of scan requests per day, we had to make our API scale enough to keep pace with that high demand if it was ever to be enabled by default.
High-level Design Overview
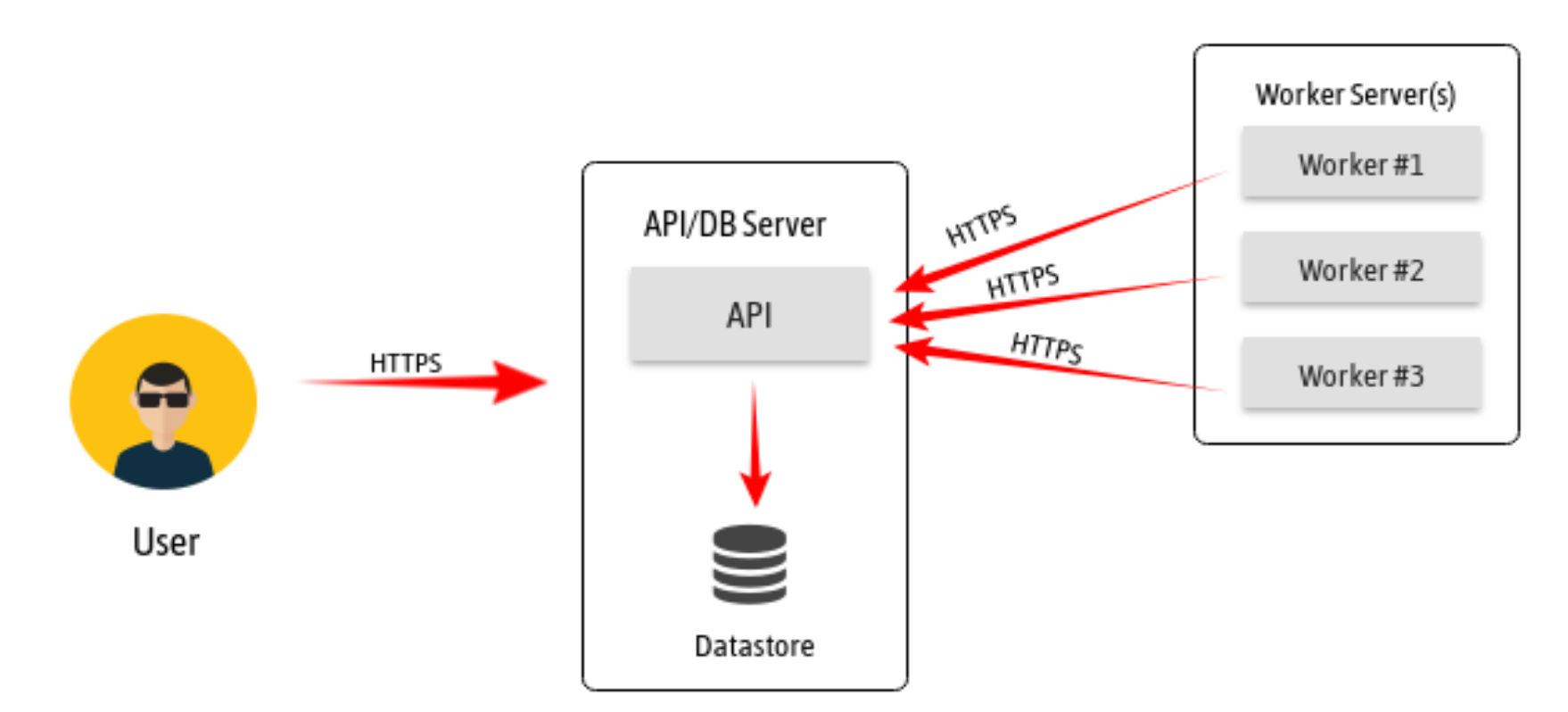
Our high-level design evolved around a producer/consumer model. We also tried to keep things simple and modular so that it was easy to trade out or upgrade components as needed, using HTTPS as a transport where-ever possible. This flexibility was invaluable as we progressed throughout the project, learned where the bottlenecks were, and upgraded individual sub-components when they showed strain.
In our approach, a user makes a request to the API which is queued in the database as a state machine to track a scans progress throughout. The worker then polls the API for work, takes the work off the database queue, performs the scan and sends the scan results back to API server. The scan results are then stored in the database. As a starting point, an ssh_scan_api operator can have a single worker process running on the API/DB server. As the workload requirements increases and queues build up, which we can monitor through our stats API route, we simply scale workers horizontally with Docker to pick up the additional load with relative ease without the need to disrupt other system components.
Challenges
Asynchronous job management was a totally new concept for us before we started this this project. Because of this, it took us some time to settle on the components to efficiently handle our use-cases. Fortunately, with the help of our mentors, we settled on implementing many things from scratch to start, which gave us a more detailed insight on the following:
- How asynchronous API systems work
- How to make it scale by identifying and removing the bottlenecks
As the end-to-end scan time depends mainly in completing the scan, we have achieved scalability with the help of multiple workers doing the scans in parallel. Also to avoid API abuse, we provided authentication requirements around the API to prevent the abuse of essential functions.
Current Status of Project
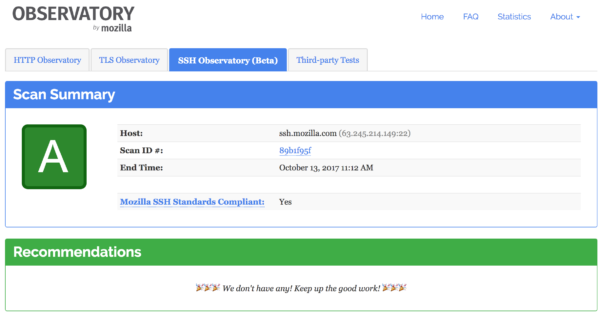
We have already integrated ssh_scan_api as a supporting sub-module of the Mozilla Observatory and it is deployed as a beta here. However, even as a beta service, we’ve already run over 4,000+ free scans for public SSH services, which is far more than we could have ever done with the single-threaded command-line version we started with. We also expect usage to increase significantly as we raise awareness of this free tool.
Future Plans
We plan to do more performance testing of the API to continue to identify and plan for future scaling needs as demand presents itself. Outcomes of this effort might also include an even more robust work management strategy, as well as performance stressing the API. The process continues to be iterative and we are solving challenges one step at a time.
Thanks Mozilla!
This project was a great opportunity to help Mozilla in building a more secure and open web and we believe we’ve done that. We’d like to give special thanks to claudijd, pwnbus and kang who supported us as mentors and helped guide us through the project. Also, a very special thanks to April for doing all the front-end web development to add this as a submodule in the Observatory and helping make this real.
If you would like to contribute to ssh_scan or ssh_scan_api in any way, please reach out to us using GitHub issues on the following respective projects as we’d love your help:
Best,