Prior to being able to display a web page within a browser the rendering engine checks and verifies the MIME type of the document being loaded. In case of an html page, for example, the rendering engine expects a MIME type of ‘text/html’. Unfortunately, time and time again, misconfigured web servers incorrectly use a MIME type which does not match the actual type of the resource. If strictly enforced, this mismatch in types would downgrade a users experience. More precisely, the rendering engine within a browser will try to interpret the resource based on the ruleset for the provided MIME type and at some point simply would have to give up trying to display the resource. To compensate, Firefox implements a MIME type sniffing algorithm – amongst other techniques Firefox inspects the initial bytes of a file and searches for ‘Magic-Numbers’ which allows it to determine the MIME type of a file independently of the one set by the server.
Whilst sniffing of the MIME type of a document improves the browsing experience for the majority of users, it also enables so-called MIME confusion attacks. In more detail, imagine an application which allows hosting of images. Let’s further assume the application allows users to upload ‘.jpg’ files but fails to correctly verify that users of that application actually upload only valid .jpg files. An attacker could craft an ‘evil.jpg’ file containing valid html and upload that through the application. The innocent victim of that application solely expects images to be displayed. Within the browser, however, the MIME sniffer steps in and determines that the file contains valid html and overrides the MIME type to load the file like any other page within the application. Additionally, embedded JavaScript fragments within that page will be treated as same-origin and hence be granted the same permissions as the host application. In turn, the granted permissions allow the attacker to gain access to confidential user information.
To mitigate such MIME confusion attacks Firefox expands support of the header ‘X-Content-Type-Options: nosniff’ to page loads (view specification). Firefox has been supporting ‘XCTO: nosniff’ for JavaScript and CSS resources since Firefox 50 and starting with Firefox 75 will use the provided MIME type for page loads even if incorrect.
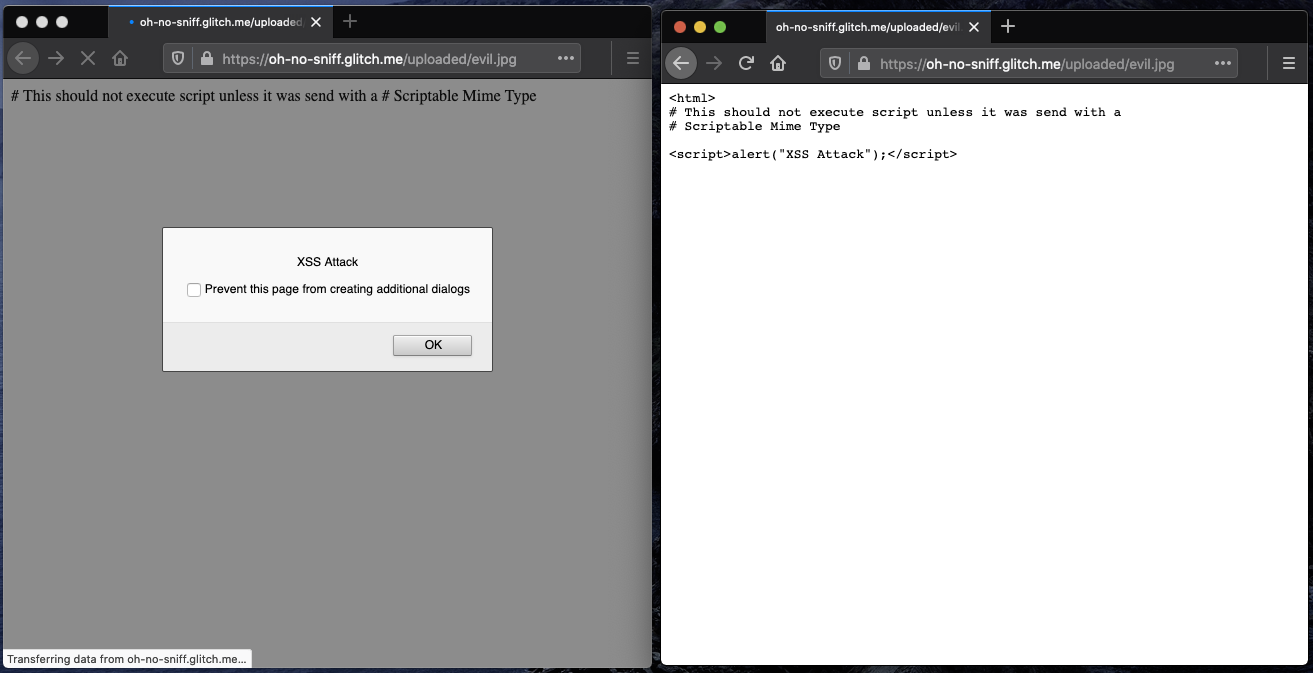
Left: Firefox 74 ignoring XCTO, sniffing HTML, and executing script.
Right: Firefox 75 respecting XCTO, and defaulting to plaintext.
If the provided MIME type does not match the content, Firefox will not sniff the MIME type but will show an error to the user instead. As illustrated above, if no MIME type was provided at all, Firefox will try to use plaintext or prompt a download . Showing the user an error in the case of a detected MIME type mismatch instead of trying to sniff and render a potentially malicious page allows Firefox to mitigate such MIME confusion attacks.