As per my previous blog post, we migrated Socorro to the new data center in Phoenix successfully on Saturday.
This has been a mammoth exercise, that sprang from two separate roots:
- In June last year, we had a configuration problem that looked like a spike in crashes for a pre-release version of Firefox (3.6.4). This incident (known inaccurately, as “the crash spike”) made it clear that crash-stats is on the critical path to shipping Firefox releases.
- Near the end of Q3 we realized we were rapidly approaching the capacity of the current Socorro infrastructure.
Around that time we also had difficulty with Socorro stability. This spawned the creation of a master Socorro Stability Plan, with six key areas. I’ll talk about each of these in turn.
Improve stability
Here, we solved some Hbase related issues, upgraded our software, scheduled restarts three times a week and, most importantly, sat down to conduct an architectural review.
The specific HBase issue that we finally solved had to do with intra-cluster communication. (We needed to upgrade our Broadcomm NIC drivers and kernel to solve a known issue when used with HBase. This problem surfaces as the number of TCP connections growing and growing until the box crashes. Solving this removed the need for constant system restarts.)
Architectural improvements
We collect incoming crashes directly to HBase. We determined that as HBase is relatively new and as we’d had stability problems, that we should get Hbase off the critical path for production uptime. We rewrote collectors to seamlessly fall back to disk if HBase was unavailable, and for them optionally to use disk as primary. As part of this process, the system that moves crashes from disk to HBase was replaced. It went from single threaded to multi-threaded, which makes playing catchup after an HBase downtime much much faster.
We still want to put a write through caching layer in front of HBase. This quarter, the Metrics team is prototyping a system for us to test, using Hazelcast.
Build process
We now have an automated build system. When code is checked into svn, Hudson notices, creates a build and runs tests. This build is then deployed in staging. Now we are on the new infrastructure, we will deploy new releases from Hudson as well.
Improved release practices
We have a greatly improved set of release guidelines, including writing a rollback plan for every major release. We did this as part of the migration, too. Developers now have read only access to everything in production: we can audit configs and tail logs.
The biggest change here, though, is switching to Puppet to manage all of our configurations. Socorro has a lot of moving parts, each with its own configuration, and thanks to the fine work by the team, all of these configurations are automatically and centrally managed and can be changed and deployed at the push of a button.
Improved insight into systems
As part of the migration, we audited our monitoring systems. We now have many more nagios monitors on all components, and have spent a lot of time tuning these. We also set up ganglia and have a good feel for what the system looks like under normal load.
We still intend to build a better ops dashboard so we can see all of these checks and balances in one place.
Move to bigger, better hardware in PHX
This one is the doozy. Virtually all Socorro team resources have been on this task full time since October, and we managed to subsume half of the IT/Ops team as well. I’d like to give a special shout-out here to NetOps, who patiently helped with our many many requests.
It’s worth noting that part of the challenge here is that Socorro has a fairly large number of moving parts. I present, for your perusal, a diagram of our current architecture.
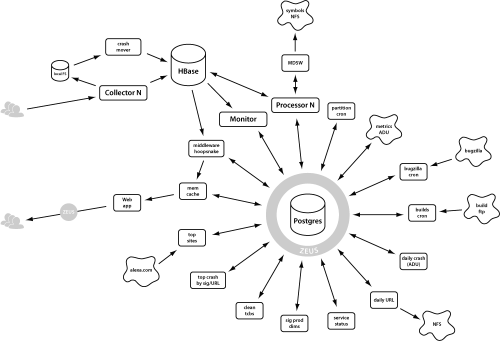
I’ve blogged about our architecture before, and will do so again, soon, so this is just a teaser.
One of the most interesting parts of the migration was the extensive smoke and load testing we performed. We set up a farm of 40 Seamicro nodes and used them to launch crashes at the new infrastructure. This allowed us to find network bottlenecks, misconfigurations, and perform tuning, so that on the day of the migration we were really confident that things would go well. QA also really helped here because with the addition of a huge number of automated tests on the UI, we knew that things were looking great from an end user perspective.
The future
We now have a great infrastructure and set of processes to build on. The goal of Socorro – and Webtools in general – is to help Firefox ship as fast and seamlessly as possible, by providing information and tools that help to build the best possible browser. (I’ll talk more about this in future blog posts, too.)
Thanks
I’ll wrap up by thanking every member of the team that worked on the migration, in no particular order:
- Justin Dow, Socorro Lead Sysadmin, Puppetmaster
- Rob Helmer, Engineer, Smoke Tester Extraordinaire and Automater of Builds
- Lars Lohn, Lead Engineer
- Ryan Snyder, Web Engineer
- Josh Berkus, PostgreSQL consultant DBA
- Daniel Einspanjer, Metrics Architect
- Xavier Stevens, HBase wizard
- Corey Shields, Manager, Systems
- Matthew Zeier, Director of Ops and IT
- Ravi Pina, NetOps
- Derek Moore, NetOps
- Stephen Donner, WebQA lead
- David Burns, Automated Tester
- Justin Lazaro, Ops
Good job!

Justin Dolske wrote on
:
wrote on
: