I thought I share some statistics about our localizable strings. I’m currently trying to create a tool that would help localizers to find terms or phrases that show up in Firefox often. Roughly, an automated way to do glossaries. So, the basic idea is to go through our localizable files, and search for phrases that come up elsewhere. Example:
I love to localize.
I don’t really love to blog.
should factor out “love to”. So, how does one do that? First, you get all localizable strings. Or not all, just the ones in properties files and DTDs. And neglect those that are just simple chars, those are likely access and commandkeys, not much to see there. Some of those entries have multiple sentences in them, so split those. Then split all words. Now you have a sequence of sequences of words. So you “just” have to find the unique subsequences of those sequences.
Let’s do the math. Here’s the number of sentences per length of sentence for Firefox 2, with a logarithmic y-axis.
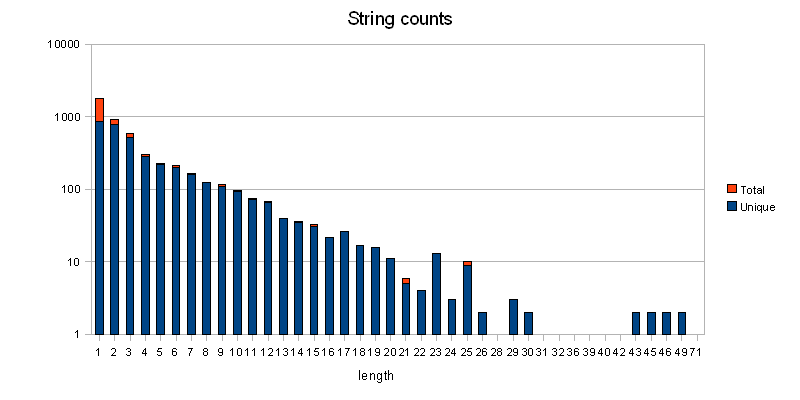
So, the maximum length of a sentence is 71 words, and we have one of that. The other end of the diagram are 1791 localizable strings that are just one word, among of those are 858 uniques.
Now, we talked about subsequences, how many of those do we have then? I’m having a chart for that, too. I dropped the long tail, and don’t do logarithmic scale, as that is hiding some of the more interesting artifacts for the shorter strings.
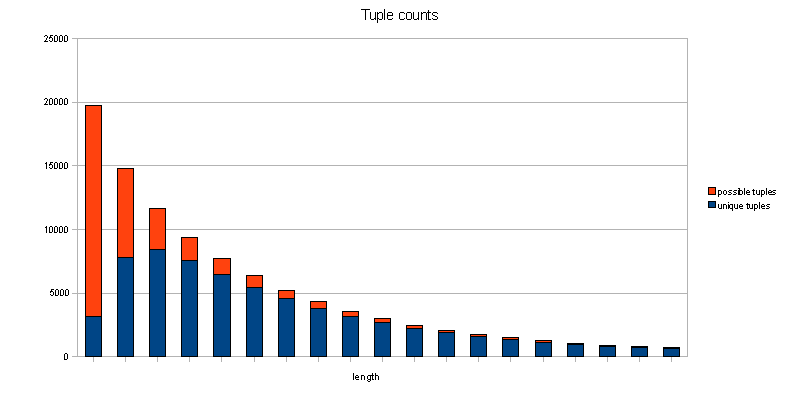
So we’re starting to see repeating strings at a length of 15 words. They stay to be few down to a length of 4 or 5, with a majority of dupes only for single words. For 2-tuples, it’s almost a tie. Yet there are 20k words in our localizable files that need to be compared, and the same for all the subsequences, and doing my ad-hoc math, which I assume to be algorithm-wise not totally clueless, that amounts to half a million tuple compares to find the list of shared n-tuples in our localizable strings, sorted by frequency.
Which is my lengthy math-way of saying: Making a consistent localization is hard.