
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.) All “This Week in Glean” blog posts are listed in the TWiG index).
I’ve just recently started my sixth year working at Mozilla on data and data-adjacent things. In those years I’ve started to notice some patterns in how data is approached, so I thought I’d set them down in a TWiG because Glean’s got a role to play in them.
Data Engagements
A Data Engagement is when there’s a question that needs to engage with data to be answered. Something like “How many bookmarks are used by Firefox users?”.
(No one calls these Data Engagements but me, and I only do because I need to call them _something_.)
I’ve noticed three roles in Data Engagements at Mozilla:
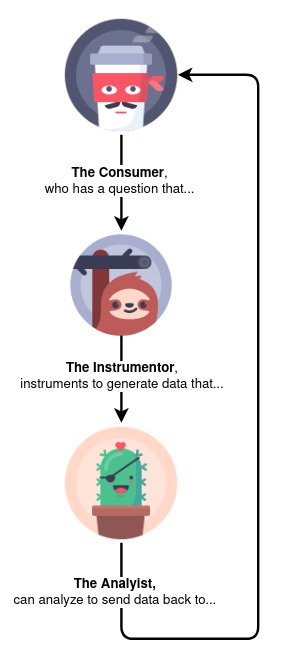
- Data Consumer: The Question-Asker. The Temperature-Taker. This is the one who knows what questions are important, and is frustrated without an answer until and unless data can be collected and analysed to provide it. “We need to know how many bookmarks are used to see if we should invest more in bookmark R&D.”
- Data Analyst: The Answer-Maker. The Stats-Cruncher. This is the one who can use Data to answer a Consumer’s Question. “Bookmarks are used by Canadians more than Mexicans most of the time, but only amongst profiles that have at least one bookmark.”
- Data Instrumentor: The Data-Digger. The Code-Implementor. This one can sift through product code and find the correct place to collect the right piece of data. “The Places database holds many things, we’ll need to filter for just bookmarks to count them.”
(diagrams courtesy of :brizental)
It’s through these three working in concert — The Consumer having a question that the Instrumentor instruments to generate data the Analyst can analyse to return an answer back to the Consumer — that a Data Engagement succeeds.
At Mozilla, Data Engagements succeed very frequently in certain circumstances. The Graphics team answers many deeply-technical questions about Firefox running in the wild to determine how well WebRender is working. The Telemetry team examines the health of the data collection system as a whole. Mike Conley’s old Tab Switcher Dashboard helped find and solve performance regressions in (unsurprisingly) Tab Switching. These go well, and there’s a common thread here that I think is the secret of why:
In these and the other high-success-rate Data Engagements, all three roles (Consumer, Analyst, and Instrumentor) are embodied by the same person.
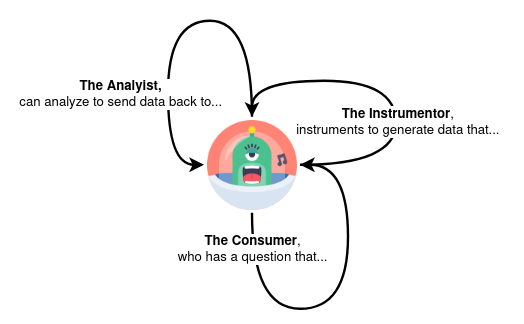
It’s a common problem in the industry. It’s hard to build anything at all, but it’s least hard to build something for yourself. When you are in yourself the Question-Asker, Answer-Maker, and Data-Digger, you don’t often mistakenly dig the wrong data to create an answer that isn’t to the question you had in mind. And when you accidentally do make a mistake (because, remember, this is hard), you can go back in and change the instrumentation, update the analysis, or reword the question.
But when these three roles are in different parts of the org, or different parts of the planet, things get harder. Each role is now trying to speak the others’ languages and infer enough context to do their jobs independently.
In comes the Data Org at Mozilla which has had great successes to date on the theme of “Making it easier for anyone to be their own Analyst”. Data Democratization. When you’re your own Analyst, then there’s fewer situations when the roles are disparate: Instrumentors who are their own Analysts know when data won’t be the right shape to answer their own questions and Consumers who are their own Analysts know when their questions aren’t well-formed.
Unfortunately we haven’t had as much success in making the other roles more accessible. Everyone can theoretically be their own Consumer: curiosity in a data-rich environment is as common as lanyards at an industry conference[1]. Asking _good_ questions is hard, though. Possible, but hard. You could just about imagine someone in a mature data organization becoming able to tell the difference between questions that are important and questions that are just interesting through self-serve tooling and documentation.
As for being your own Instrumentor… that is something that only a small fraction of folks have the patience to do. I (and Mozilla’s Community Managers) welcome you to try: it is possible to download and build Firefox yourself. It’s possible to find out which part of the codebase controls which pieces of UI. It’s… well, it’s more than possible, it’s actually quite pleasant to add instrumentation using Glean… but on the whole, if you are someone who _can_ Instrument Firefox Desktop you probably already have a copy of the source code on your hard drive. If you check right now and it’s not there, then there’s precious little likelihood that will change.
(Unless you come and work for Mozilla, that is.)
So let’s assume for now that democratizing instrumentation is impossible. Why does it matter? Why should it matter that the Consumer is a separate person from the Instrumentor?
Communication
Each role communicates with each other role with a different language:
- Consumers talk to Instrumentors and Analysts in units of Questions and Answers. “How many bookmarks are there? We need to know whether people are using bookmarks.”
- Analysts speak Data, Metadata, and Stats. “The median number of bookmarks is, according to a representative sample of Firefox profiles, twelve (confidence interval 99.5%).”
- Instrumentors speak Data and Code. “There’s a few ways we delete bookmarks, we should cover them all to make sure the count’s correct when the next ping’s sent”
Some more of the Data Org and Mozilla’s greatest successes involve supplying context at the points in a Data Engagement where they’re most needed. We’ve gotten exceedingly good at loading context about data (metadata) to facilitate communication between Instrumentors and Analysts with tools like Glean Dictionary.
Ah, but once again the weak link appears to be the communication of Questions and Answers between Consumers and Instrumentors. Taking the above example, does the number of bookmarks include folders?
The Consumer knows, but the further away they sit from the Instrumentor, the less likely that the data coming from the product and fueling the analysis will be the “correct” one.
(Either including or excluding folders would be “correct” for different cases. Which one do you think was “more correct”?)
So how do we improve this?
Glean
Well, actually, Glean doesn’t have a solution for this. I don’t actually know what the solutions are. I have some ideas. Maybe we should share more context between Consumers and Instrumentors somehow. Maybe we should formalize the act of question-asking. Maybe we should build into the Glean SDK a high-enough level of metric abstraction that instead of asking questions, Consumers learn to speak a language of metrics.
The one thing I do know is that Glean is absolutely necessary to making any of these solutions possible. Without Glean, we have too many systems that are fractally complex for any context to be relevantly shared. How can we talk about sharing context about bookmark counts when we aren’t even counting things consistently[2]?
Glean brings that consistency. And from there we get to start solving these problems.
Expect me to come back to this realm of Engagements and the Three Roles in future posts. I’ve been thinking about:
- how tooling affects the languages the roles speak amongst themselves and between each other,
- how the roles are distributed on the org chart,
- which teams support each role,
- how Data Stewardship makes communication easier by adding context and formality,
- how Telemetry and Glean handle the same situations in different ways, and
- what roles Users play in all this. No model about data is complete without considering where the data comes from.
I’m not sure how many I’ll actually get to, but at least I have ideas.
:chutten
[1] Other rejected similes include “as common as”: maple syrup on Canadian breakfast tables, frustration in traffic, sense isn’t.
[2] Counting is harder than it looks.
(( This post is a syndicated copy of the original. ))