
Two weeks ago the Socorro Eng/Ops team, in charge of Socorro and Tecken, had its first remote 1-day Data Sprint to onboard folks from ops and engineering.
The Sprint was divided into three main parts, according to the objectives we initially had:
- Onboard new folks in the team
- Establish a rough roadmap for the next 3-6 months.
- Find a more efficient way to work together,
The sprint was formatted as a conversation followed by a presentation guided by Will Kahn-Greene, who leads the efforts in maintaining and evolving the Socorro/Tecken platforms. In the end we went through the roadmap document to decide what our immediate future would look like.
Finding a more efficient way to work together
We wanted to track our work queue more efficiently and decided that a GitHub project would be a great candidate for the task. It is simple to set up and maintain and has different views that we can lightly customize.
That said, because our main issue tracker is Bugzilla, one slightly annoying thing we still have to do while creating an issue on our GitHub project is place the full url to the bug in the issue title:
- tecken: [research] figure out why uploads pages are so slow https://bugzilla.mozilla.org/show_bug.cgi?id=1668371
If we could place links as part of the title, then we could do something like:
- bug: 1668371 figure out why upload pages are so slow.
Which is much nicer, but GitHub doesn’t support that.
Here’s the link to our work queue: https://github.com/orgs/mozilla-services/projects/16/views/1
Onboarding new people to Socorro/Tecken
This was a really interesting part of the day in which we went through different aspects of the crash reporting ecosystem and crash ingestion pipeline.
Story time
The story of Mozilla’s whole Crash Reporting system dates back to 2007, when the Socorro project was created. Since then, Crash Reporting has been an essential part of our products. It is present in all stages, from development to release, and is comprised of an entire ecosystem of libraries and systems maintained by different teams across Mozilla.
Socorro is one of the longer-running projects we have at Mozilla. Along with Antenna and Crash Stats it comprises the Crash Ingestion pipeline, which is maintained by the socorro-eng team. The team is also in charge of the Symbol and Symbolication Servers a.k.a. Tecken.
Along with that story we also learned interesting facts about Crash Reporting, such as:
-
- Crash Reports are not the same as Crash Pings: Both things are emitted by the Crash Reporter when Firefox crashes, but Reports go to Socorro and Pings go to the telemetry pipeline
-
- Not all Crash Reports are accepted: The collector throttles crash reports according to a set of rules that can be found here
-
- Crash Reports are pretty big compared to telemetry pings: They’re 600Kb aggregate but stack overflow crashes can be bigger than 25MB
-
- Crash Reports are reprocessed regularly: Whenever something that is involved in generating crash signatures or crash stacks is changed or fixed we reprocess the Crash Reports to regenerate their signatures and stacks
What’s what
There are lots of names involved in the Crash Reporting. We went over what most of them mean:
Symbols: A symbol is an entry in a .sym file that maps from a memory location (a byte number) to something that’s going on in the original code. Since binaries don’t contain information about the code such as code lines, function names and stack navigation, symbols are used to enrich minidumps emitted by binaries with such info. This process is called symbolication. More on symbol files: https://chromium.googlesource.com/breakpad/breakpad/+/HEAD/docs/symbol_files.md
Crash Report: When an application process crashes, the Crash Reporter will submit a Crash Report with metadata annotations (BuildId, ProductName, Version, etc) and minidumps which contain info on the crashed processes.
Crash Signature: Generated to every Crash Report by an algorithm unique to Socorro with the objective of grouping similar crashes.
Minidump: A file created and managed by the Breakpad library. It holds info on a crashed process such as CPU, register contents, heap, loaded modules, threads etc.
Breakpad: A set of tools to work with minidump files. It defines the sym file format and includes components to extract information from processes as well as package, submit and process them. More on Breakpad: https://chromium.googlesource.com/breakpad/breakpad/+/master/docs/getting_started_with_breakpad.md#the-minidump-file-format
A peek at how it works
Will also explained how things work under the hood and we had a look on the diagrams that show what comprises Tecken and Socorro:
Tecken/Eliot
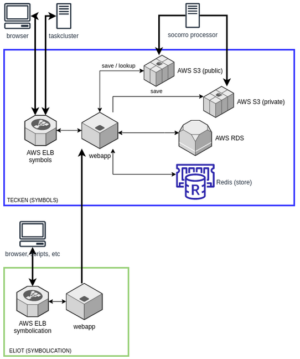
Tecken (https://symbols.mozilla.org/) is a Django web application that uses S3 for storage and RDS for bookkeeping.
Eliot (https://symbolication.services.mozilla.com/) is a webapp that downloads sym files from Tecken for symbolication.
Socorro
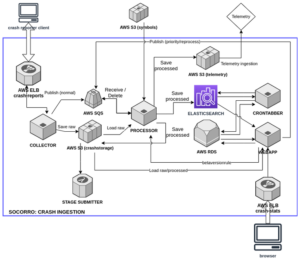
Socorro has a Crash Report Collector, a Processor and a web application (https://crash-stats.mozilla.org/) for searching and analyzing crash data. Notice the Crash Ingestion pipeline processes Crash Reports and exports a safe form of the processed crash to Telemetry.
More on Crash Reports data
The Crash Reporter is an interesting piece of an application since it needs to do its work while the world around it is collapsing. That means a number of unusual things can happen to the data it collects to build a Report. That being said, there’s a good chance the data it collects is ok, and even when it isn’t, it can still be interesting.
A real concern toward Crash Report data is how toxic it can get: While some pieces of the data are things like the ProductName, BuildID, Version and so on, other pieces are highly identifiable such as URL, UserComments and Breadcrumbs.
Add that to the fact that minidumps contain copies of memory from the crashed processes, which can store usernames, passwords, credit card numbers and so on, and you end up with a very toxic dataset!
Establishing a roadmap for the next 3-6 months
Another interesting exercise that made that Sprint feel even more productive was going over the Tecken/Socorro roadmap and reprioritizing things. While Will was explaining the reasons why we should do certain things, I took that chance to also ask questions and get better context on the different decisions we made, our struggles of past and present and where we aim to be.
Conclusion
It was super productive to have a full day on which we could focus completely on all things Socorro/Tecken. That series of activities allowed us to improve the way we work, transfer knowledge and prioritize things for the not-so-distant future.
Big shout out to Will Kahn-Greene for organizing and driving this event, and also for the patience to explain things carefully and precisely.