We recently released a feature in the Firefox iOS mobile app called “Shake to Summarize”. The reception was remarkably positive, earning an honorable mention on Time Magazine’s best inventions of 2025.
For anyone unfamiliar with Shake to Summarize, it’s just what the name implies: when you’re browsing a webpage, you can shake your phone to generate a short summary of the page’s content.
The gesture is fun, the feature is useful, and the whole thing feels simple and natural.
From a technical standpoint, the application works just how you’d imagine: when a shake (or lightning bolt-icon press) is detected, we grab the web page content, pass it to an LLM for summarization, and then return the result to the user.
But with the LLM landscape being as vast as it is, there is a lot to consider when bringing even a relatively straightforward application to the market. In this post, we’ll discuss the ins and outs of our approach to model selection. We will leave prompt development and quality testing for a future article.
Which model?
These days, there are many LLMs available, with a steady stream of new releases arriving almost every week.. Each release is paired with a slate of benchmark scores, showing the new model’s superiority along one dimension or another. The pace of development has been fast and furious and billions of dollars have been spent inching the numbers higher and higher.
But what do these metrics mean in practice? At the end of the day, we are building a product for users. The most important metric for us is, “how useful are the summaries the model produces?” – something that isn’t neatly captured by the benchmark scores. To select the best model for our applications, we need to run our own tests.
For us, the best model had to excel along several dimensions:
- First, summary quality. That’s the whole point, after all.
- Second, speed. The model needs to return summaries relatively quickly. If it takes the same amount of time to produce the summary as it does to read the article – we’ve lost.
- Third, cost. Since we do not charge for use of the Shake to Summarize feature, inference costs are entirely on us (you’re welcome).
- Finally, open source. Supporting open source projects is a core value here at Mozilla. As such, we prefer to use open source models in our applications, when possible (in this case, we had to settle for open weights).
Keeping the above in mind, we selected the following models for our initial evaluation: Mistral Nemo, Mistral Small, Jamba 1.5 mini, Gemini flash 2.0 flash and Llama 4 Maverick – all of which were hosted on Vertex AI. Note: this project began in early 2025
Quality
Standard summary evaluation metrics such as BLEU and ROUGE rely on token overlap and do not correlate well with human judgement. Thus, we decided to use an LLM judge (GPT-4o) to evaluate our model candidates. We had each model generate summaries of the same set of webpages, and then asked the LLM judge to evaluate each summary on the following metrics:
Coherence: Does the summary read logically and clearly as a standalone text?
Consistency: Is the information in the summary accurate and faithful to the source? Are there any hallucinations?
Relevance: Does the summary focus on the most important content from the document?
Fluency: Is the summary grammatically correct, fluent, and well-written?
To get a single, comparable metric, we then averaged these scores.
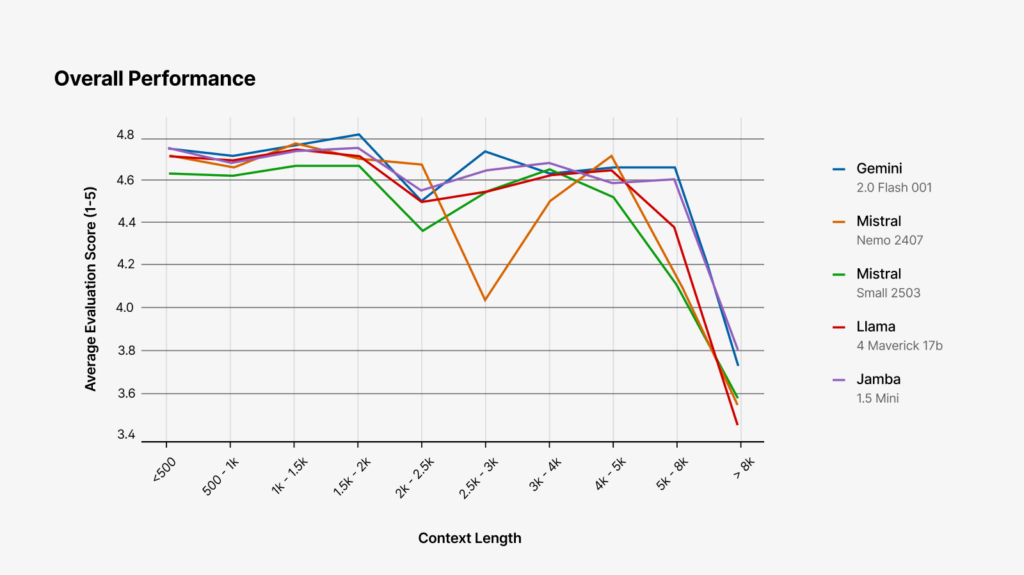
From this analysis, we see that Google’s Gemini 2.0 Flash, Meta’s Llama 4 Maverick, and Mistral small are top performers – with Gemini consistently leading the pack. We see that the top three models are roughly equivalent on short passages up to around 2000 tokens (which is roughly the length of the average webpage), but performance separates more as passages get longer – particularly those containing over 5000 tokens*.
*We note that, due in part to this performance degradation, we summarize only pages that are shorter than this 5000 token threshold.
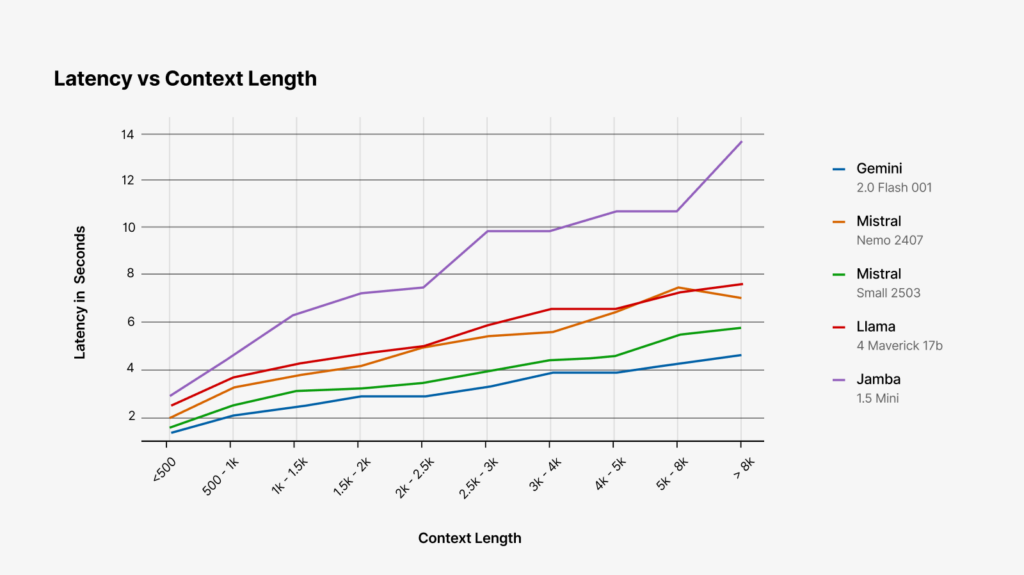
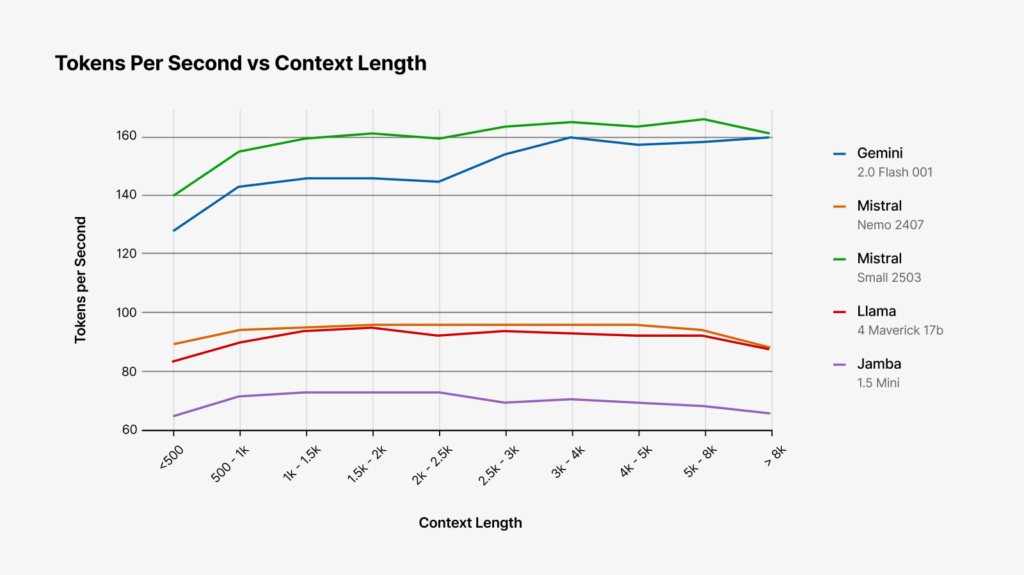
Speed
For speed, the two metrics we looked at were time to first token (i.e. how long do you have to wait before the model starts generating its response) and tokens-per-second (total tokens generated / total generation time, including encoding time).
In both of these tests, Mistral-Small and Gemini-2.0-flash are the clear winners. Both models are faster to begin generating output and produce tokens at a much faster clip than the other models we tested.
Cost
On Vertex AI serverless instances, as of November 2025, the cost for input tokens for our top 3 models are as follows. (See all Vertex AI pricing here):
| Model | Price / M input tokens | Price / M output tokens |
| Gemini 2.5 Flash (2.0 no longer available) | $0.30 | $2.50 |
| Llama4-Maverick | $0.35 | $1.15 |
| Mistral Small | $0.10 | $0.30 |
It’s clear that Mistral small over-performs from a quality and performance / dollar standpoint, costing one-third of the price or less per input token (which is where the bulk of our token usage is) compared to the other two models.
Open source
Our top priority is building a great user experience. We also believe that open source software is an integral part of building a healthy internet. When we can support open source while still delivering the highest quality experience, we will.
In this category, Llama4 Maverick and Mistral Small come out ahead. While neither is fully open source (no training code or data has been released), both models have open weights paired with liberal usage policies. Gemini 2.5 Flash, on the other hand, is a proprietary model.
Model selection
When we considered all of the above, we decided to go with Mistral-Small to power our feature: it’s fast, it’s inexpensive, it has open weights, and it produces high quality summaries. What’s not to like?
Release and future directions
After selecting the model, we iterated on the prompt to ensure that we were delivering the best experience (see the upcoming blog post: Shake to Summarize: Prompt Engineering), and we released the solution in September of 2025.
This project was an early foray in building LLM-powered features into the browser. As such, the model selection process we developed here helped us chart the course for model selection in our later AI integrations. Notably, the soon-to-be released Smart Window required choosing not just one, but multiple models to power the application—giving users increased control over their experience.
Throughout this process, we learned that the “best” model isn’t the one with highest benchmark scores. It’s the one that fits the context in which it’s used—aligning with the task, the budget, and Mozilla’s commitment to open source.