I am very happy to announce the release of Circus 0.10.
I am very happy to announce the release of Circus 0.10.
Circus is a process & socket manager we’ve been developing at Cloud Services to supervise our different processes on our servers It is built using Python and ZeroMQ.
More information is available at http://circus.readthedocs.org
This new version is a major step forward for the project for two reasons. First, we’ve added Python 3 compatibility and second, we did a major refactoring of the core to make it fully asynchronous.
What’s exciting is that most of the work in this release has been done by contributors external to the Cloud Services team, making Circus what we intended at its inception: an open source tool that’s built by and for the Python & Mozilla communities at large.
Below are 3 interviews of Circus contributors. I have asked them the same set of questions.
Fabien Marty
Meet Fabien Marty from Météo France, the French national weather forecast company. He’s one of the main instigators of the core refactoring and explains us what he’s been doing to make it happen.
Tarek: Hello Fabien. Can you tell us who you are?
Fabien: I am Fabien Marty, I am 34 years old and I’ve been working at Météo France as a technical lead for 7 years.
Tarek: How did you end up using Circus?
Fabien: We’re working on a big internal project in my company, where we need to run and supervise a lot of processes (more than 80 per server) and make sure we control every aspect of the processes’ start and stop sequences.
Unlike a classical web stack, we’re working on a stack that receives a huge amount of data — satellite images, numerical modeling data, sensor data, etc. When a server is being stopped, we need to make sure we don’t lose any incoming data. That’s why the stop sequence can last for more than 5 minutes.
We built our own tool to deal with processes, called “launcher”, but it was a bit clunky. Instead of spending more time fixing it, we looked at existing open source projects and found Circus.
Tarek: How did it go with Circus at first?
Fabien: The first tries were very positive. The documentation was clear and detailed and we were able to install it and start using it right away, replacing our own solution.
Tarek: Did you have some issues?
Fabien: Yeah, we had some issues when we tested the stop sequence. As I’ve explained earlier, we have a very specific use case:
we don’t stop our processes with signals – but with flags we’re setting in a Redis server the stop sequence can last for over 5 minutes, because our processes might have to finish processing some data before shutting down we have to start and stop our processes quite often to avoid any memory issues.
Circus was not quite suited for this use case, but we kind of knew we’d hit this problem.
Tarek: What did you do?
Fabien: We started with Alex Marandon (one of the project developers) fixing a few bugs in Circus here and there and pushed them upstream. We also fixed some documentation bugs we found along the way.
Then we wrote a plugin to deal with reloading processes automatically if the process command line is changed in the configuration.
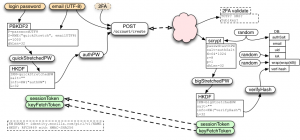
Finally, we worked on the stop sequence: since our processes can take up to 5 minutes to stop and since Circus’ core was not fully asynchronous, this would lock up the event loop and Circus would become unresponsive to any other command during that window.
After some serious design talks with the Cloud Services team, we started to work on a branch to fix this.
Tarek : Was it easy?
Fabien: Not at all ! We knew it was going to be a lot of work. But it was even bigger than we thought. Our first attempt failed: we tried to add a simple callback system hooked into the PyZMQ event loop but that made the code harder to read and understand.
That’s mainly because Circus has high level methods that are doing basic operations, so adding callbacks on those made the whole thing a callback hell.
For our second attempt, we decided to move to a pure Tornado event loop and use its coroutine decorator. That drastically simplified making Circus’ core asynchronous. Moreover, moving Circus code to Tornado coroutines was a no brainer for its PyZMQ compatibility. The library has its own bundled version of a Tornado eventloop but you can use a plain Tornado eventloop if you want, and everything stays compatible.
The bottom line is that we ended up with even simpler code!
Tarek : Are you happy with the result?
Fabien: Yes, very much. There are still a few rough edges,but it works well now and is way better than our initial custom tool. We spent more time than we initially planned but that was worth it – and we don’t regret that investment. 🙂
Rémy Hubscher
Meet Rémy Hubscher from Novapost, a French Software company. Rémy is a long time Circus contributor
Tarek: Hello Rémy. Can you tell us who you are?
Rémy: Hey Tarek, I am Rémy HUBSCHER, 26 years old and I work for Novapost as an R&D engineer.
Tarek: How did you end up using Circus?
Rémy : We’re deploying our apps in clusters from 3 to 25 servers, in a private cloud on Amazon and Rackspace. We previously used Supervisor and Gunicorn to deploy them.
Our main motivation for using Circus is its decentralised behavior: every server has its own circus daemon and manages processes there. With a single circus-web dashboard it’s easy to manage them all; we can watch the socket, cpu and memory loads in realtime.
Circus is also easy to configure with Saltstack and it’s dead easy to add new processes and sockets in our stacks.
Tarek: How did it go with Circus at first?
Rémy: Great! Installing Circus in our environment was easy and the clear documentation helped us a lot there.
Tarek: Did you have some issues?
Rémy: Yes, we did have some but my colleague Boris Feld and I contributed fixes to the project that took care of them.
One issue that remains is the fact that it’s not possible to automatically close a socket when all the processes that use it are shut down. But this is going to be fixed soon.
Tarek : What did you contribute in Circus?
Rémy: We started contributing a year ago, by adding simple features like bash autocompletion and the shell in circusctl. We were also involved in brainstorming about the clustering feature, and added automatic UDP discovery of circus daemons.
We also organized a three-day hackaton on Circus in our office to work on the clustering, since we needed it.
Circus-web (the web dashboard) was initially built with Bottle, but we moved it to Tornado for simpler integration with PyZMQ
Tarek : Was it easy?
Rémy: Well, it’s still Python so we found solutions eventually. But it’s important to understand the overall architecture and design, and how Tornado’s async works. But, when there’s an issue, the services team is quite responsive on IRC
Tarek : Are you happy with the result?
Rémy: Very happy. We’ve been using Circus for three apps in production and we’re gradually moving everything else to it.
Tarek : What’s next?
Rémy: We’ll help in reviewing the pull requests on the project and answer any questions – and we will be organizing a new hackaton in early 2014, to tackle more clustering features.
Scott Maxwell
Meet Scott Maxwell, who made Circus python 3 compatible!
Tarek: Hello Scott. Can you tell us who you are?
Scott: My name is Scott Maxwell. I’m a veteran of the video game industry (since 1983) but, recently I have been working on the app store for one of the American car companies.
Tarek: How did you end up using Circus?
Scott: We are currently using Supervisord to run our servers. I used supervisor at Sony Online Entertainment and it worked fairly well for me. We are on Python 3.3 so I had to port supervisor to Py3 about a year ago.
Lately, our restart logic has gotten more complex, since we want to bounce uWSGI without losing any connections. We had to build more and more outside of Supervisor. Also, we started querying Supervisor through the RPC mechanism for monitoring purposes, and it started to crash periodically. The Supervisor team never accepted my changes so Supervisord is still limited to Py2 today and I cannot easily get any fixes they might make.
I discovered Circus through a post on the uWSGI site. When I saw that it was using ZeroMQ and that it supported signals and much richer restart hooks, it seemed like exactly what we were looking for.
Tarek: How did it go with Circus at first?
Scott: The functionality looked great, so we were very excited about the potential.
Tarek: Did you have some issues?
Scott: It was a bit of arough start because of our Py3 requirement. Porting a client/server application to Py3 is much harder because exceptions are caught in one process and sent to the other, losing much of the context. Also, right around the time I was finishing up, the big async upgrade dropped.
Once I got the Py3 port done, I realized that a few other features were missing. For instance, supervisor lets you specify the signal to use for stopping the process. Fortunately this was a very easy feature to add to circus.
Tarek: What did you do?
Scott: I just put my head down and got the initial port done. Once I had basic functionlity in place, I issued a pull request and got everything integrated. From there, the real collaboration began.
Since I was new to the project, I lacked deep understanding of how everything fit together. I spent many hours trying to resolve the resource warnings that the Py3 runtime exposed, without great success. But you, Tarek, were able to fix the majority of them very quickly. When I ran into trouble with the flapping plugin, Alex (@amarandon) jumped straight in. Rémy (@natim) was also very helpful.
Tarek: Was it easy?
Scott: The work was hard, but the collaboration was easy.
Tarek: Are you happy with the result?
Scott: Very happy so far. I expect to have my entire stack moved over to circus on one environment in the next few days. Then I will be able to fully judge the result.
Tarek: What’s next?
Scott: I think Circus is complete for my needs at this point. But it is very comforting to know that if I need a new feature that is general purpose enough, the Circus team will take my change in a timely manner. It gives me great confidence moving forward.
If you are interested in contributing to Circus – visit http://circus.readthedocs.org/en/latest/contributing/
Many thanks to Toby Elliott for all the English proofreading. 🙂
— Tarek, on behalf of the Circus team