As I have been blogging before, I try to create a glossary for Firefox 2. I’m leaving out all the gory details, but it’s been a hard fight between me trying to be clever and being dumb. I’m still not happy with the code that creates the data, but still, I think this iteration generates output that looks good enough to share, and get busted by others.
With all the grumpiness about my code, I’m pretty happy that I didn’t have to do the web part, so thanks to shaver for poking plasticmillion about exhibit. That went pretty slick up to a site of my standards. Read, with full visual suckage. I did find a bug in exhibit, though.
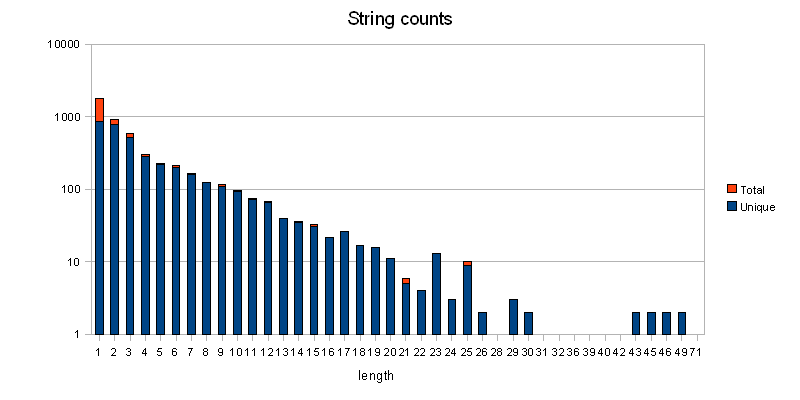
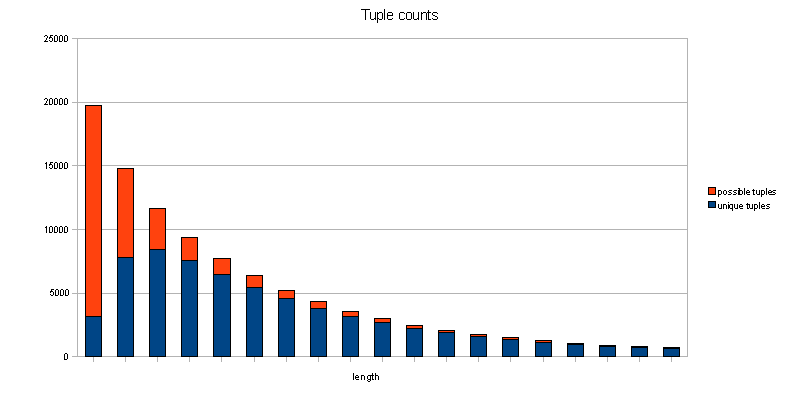
The dataset I have now went through a series of iterations to do the right thing to find phrases, which, by now, should be a nice set of educated guesses. I’m probably wrong with some, so if you find a string that shouldn’t be there, or should be and isn’t, that’s likely a bug.
Ok, beef. Here’s the link. It should have all phrases that appear in Firefox more than once, sortable by length and occurence, but not sequences that are just filler words. I have a short black list for the latter. For each phrase, you can click on it, and it will open an mxr search on the MOZILLA_1_8_BRANCH in all localizable files for it. I didn’t file the mxr bugs, nor did I yet try to work around them, searching for ‘foo’ including ticks doesn’t work, at least. And of course, you can search the glossary, it’d suck otherwise, right? Thanks to exhibit, that was easy.
Before going further into this, is this something worthwhile for the l10n community? Other RFEs? Right now, the source data is in sqlite, which I intend to share, if anyone’s interested, though the database schema and the way I create it needs work.
And before you ask, yes, I tried to run it on Thunderbird, too, but it seemed to make the story harder and dominate the results. I guess it’d be better to just create two separate apps. I’m having perf problems with the code, too, so I wasn’t too keen to do more than initially necessary. I don’t index security/manager, because the localizable files in there are just yucky, and I didn’t want to special case for stuff like # being replaced by a newline.