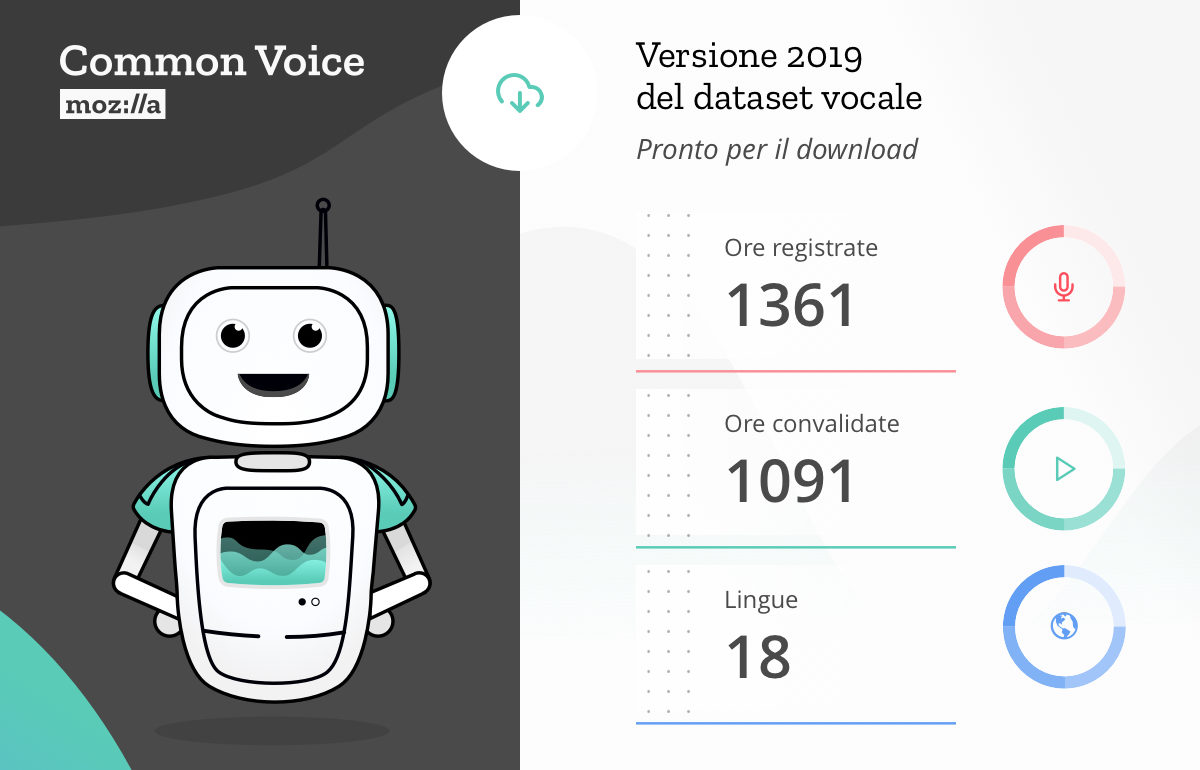
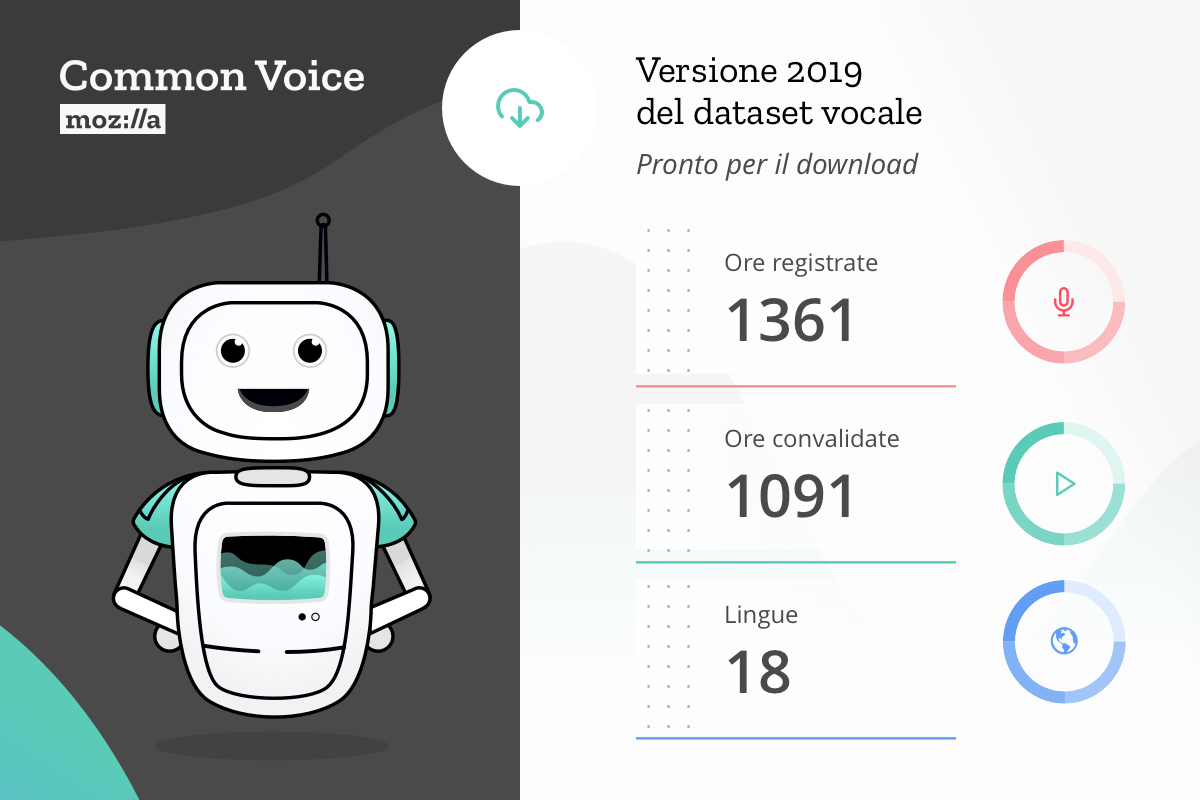
 Mozilla mette a disposizione il più grande dataset di voci generato attraverso un processo di crowdsourcing: 18 lingue, quasi 1.400 ore di registrazioni vocali effettuate da oltre 42.000 persone.
Mozilla mette a disposizione il più grande dataset di voci generato attraverso un processo di crowdsourcing: 18 lingue, quasi 1.400 ore di registrazioni vocali effettuate da oltre 42.000 persone.
Sin dall’inizio la nostra visione di Common Voice è stata quella di produrre il più diversificato dataset vocale al mondo, ottimizzato per la realizzazione di tecnologie vocali. Abbiamo anche promesso “apertura”: tutti i dati vocali trascritti e di alta qualità raccolti sarebbero stati messi a disposizione di startup, ricercatori e chiunque fosse interessato alle tecnologie di riconoscimento vocale.
Oggi siamo lieti di condividere il nostro primo dataset multilingua, comprendente 18 lingue, tra cui inglese, francese, tedesco e cinese mandarino (tradizionale), ma anche gallese e cabilo. Complessivamente, il nuovo dataset comprende circa 1.400 ore di registrazioni effettuate da oltre 42.000 persone.
Con questa versione, il dataset di Common Voice (in costante crescita) è ora il più grande nel suo genere, con decine di migliaia di persone che contribuiscono con le proprie voci e frasi originali di pubblico dominio (CC0). In futuro, il dataset completo sarà disponibile per il download sul sito di Common Voice.

Qualità dei dati
Il dataset di Common Voice è unico non solo per le sue dimensioni e modello di licenza ma anche nella sua diversità, rappresentando una comunità globale di persone che hanno contribuito con la propria voce. Ogni persona può scegliere se fornire metadati come età, sesso e accento. Queste informazioni possono essere associate alle registrazioni immesse, migliorando il processo di addestramento dei motori di riconoscimento vocale.
Questo è un approccio diverso rispetto ad altri dataset disponibili pubblicamente, per i quali la diversità viene ottenuta in modo artificiale (cioè il numero di uomini è uguale a quello delle donne) o il corpus è tanto diverso quanto i dati da cui è ricavato (per esempio il corpus di TEDLIUM, dai talk di TED, include circa 3 uomini per ogni donna).
Sempre più Common Voice: da 3 a 22 lingue in soli 8 mesi
Fin da quando abbiamo attivato il supporto ad altre lingue nel giugno del 2018, Common Voice è cresciuto, diventando sempre più globale e inclusivo. L’evoluzione del progetto ha superato ogni nostra aspettativa: negli ultimi otto mesi, le comunità si sono attivate con entusiasmo sul progetto, lanciando la raccolta dati in 22 lingue, con oltre 70 lingue in lavorazione sul sito di Common Voice.
In qualità di progetto guidato dalla comunità, ogni nuovo lancio è avvenuto grazie a persone da ogni parte del mondo che hanno interesse ad avere un dataset vocale nella propria lingua. Alcuni sono volontari appassionati, altri lavorano nel settore come linguisti o tecnologi. Ognuno di questi sforzi richiede la traduzione del sito web per permettere ai collaboratori di poter aggiungere frasi da leggere.
Le ultime lingue aggiunte includono olandese, hakha-chin, esperanto, persiano (farsi), basco e spagnolo. In alcuni casi, il lancio in Common Voice rappresenta l’inizio assoluto della presenza di una lingua su Internet. Questi sforzi delle comunità dimostrano che tutte le lingue, non solamente quelle che possono generare alti guadagni per le aziende tecnologiche, meritano di essere rappresentate.
Continueremo a collaborare con queste comunità per garantire che le loro voci siano rappresentate e per aiutarli a realizzare tecnologie vocali per loro stessi. Con questo stesso spirito, recentemente abbiamo unito le forze con Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) e ospitato un ideation hackathon a Kigali per creare un corpus per la lingua kinyarwanda, gettando le basi per tecnologie locali in Ruanda al fine di sviluppare tecnologie vocali open source nella loro lingua.
Miglioramenti nell’esperienza per i collaboratori, inclusa la possibilità di creare un profilo
Il sito di Common Voice è uno dei nostri principali strumenti per costruire dataset vocali da utilizzare in tecnologie con interazione vocale. L’aspetto attuale è il risultato di un continuo processo di iterazione. Abbiamo ascoltato i consigli forniti dalle comunità riguardo ai punti carenti per la collaborazione, conducendo anche ricerche per facilitarla, e renderla più divertente e coinvolgente.
Le persone che collaborano non solo possono visualizzare i progressi di registrazione e convalida divisi per lingua, ma hanno anche suggerimenti che variano da registrazione a registrazione; nuove funzionalità per la revisione, possibilità di registrare nuovamente frasi e saltare le registrazioni come parte integrante dell’esperienza; possibilità di muoversi rapidamente tra le sezioni Parla e Ascolta, così come di non registrare per una sessione.
Abbiamo anche aggiunto la possibilità di creare un “vero” profilo, per permettere ai collaboratori di tenere traccia dei loro progressi attraverso lingue diverse. Fornendo alcune informazioni demografiche facoltative è inoltre possibile migliorare l’utilizzo dei dati audio nell’addestramento di precisione del riconoscimento vocale.

Common Voice è nato come un prototipo per dimostrare un concetto ed è stato migliorato con continue interazioni nel corso dell’ultimo anno
Innovare prodotti con un approccio decentralizzato: una maratona piuttosto che una corsa
Mozilla vuole contribuire alla realizzazione di un ecosistema di tecnologie vocali più innovativo e diversificato. Il nostro obiettivo è sia quello di rilasciare prodotti con riconoscimento vocale, sia supportare i ricercatori e i piccoli operatori. Fornire dati attraverso Common Voice è una parte di questo approccio, insieme alla realizzazione di motori di riconoscimento vocale (STT) e di sintesi vocale (TTS) open source e modelli addestrati attraverso il progetto DeepSpeech, guidato dal nostro Machine Learning Group.
Sappiamo che questo richiederà del tempo e crediamo che distribuire velocemente e lavorare alla luce del sole possa attrarre il coinvolgimento e i suggerimenti di tecnologi, organizzazioni e aziende che renderanno questi progetti più rilevanti e solidi. La realtà attuale per entrambi i progetti è che sono ancora in fase di ricerca, anche se DeepSpeech sta facendo grandi progressi verso la fase di produzione.
Ad oggi, con i dati provenienti da Common Voice e da altre fonti, DeepSpeech è tecnicamente in grado di convertire la voce in testo con l’accuratezza di una persona e in “tempo reale”, ovvero mentre si trasmette il flusso audio. Questo permette la trascrizione di conferenze, conversazioni telefoniche, programmi televisivi, programmi radiofonici e altri flussi durante la loro riproduzione.
Il motore di DeepSpeech è già utilizzato da vari progetti non-Mozilla: per esempio in Mycroft, un assistente vocale open source; in Leon, un assistente personale open source; in FusionPBX, un sistema di gestione dei telefoni installato da una piccola organizzazione per trascrivere messaggi telefonici. In futuro vorremmo portare DeepSpeech anche su dispositivi più piccoli, come smartphone e sistemi in-car, sbloccando l’innovazione in Mozilla, ma non solo.
Per Common Voice, il nostro obiettivo nel 2018 era di sviluppare l’idea, renderla uno strumento da poter utilizzare in qualunque comunità, ottimizzare il sito web e costruire un robusto backend (per esempio, aggiungendo un sistema di gestione degli account). Nei prossimi mesi ci dedicheremo alla sperimentazione di approcci diversi per migliorare la quantità e la qualità dei dati che siamo in grado di raccogliere, sia attraverso gli sforzi della comunità sia attraverso nuove collaborazioni.
Il nostro obiettivo principale rimane quello di fornire sempre più dati di qualità a chiunque cerchi, nel mondo, di costruire e utilizzare la tecnologia vocale. Perché la competizione e l’apertura sono salutari per l’innovazione. Perché la salvaguardia delle lingue minoritarie rappresenta un problema di accesso ed equità. Perché la privacy e avere il controllo dei propri dati è importante, specialmente quando si tratta della propria voce.