June 14, 2014 was the third anniversary of the first MemShrink meeting. MemShrink is a mature effort at this point, and many of the problems that motivated its creation have been fixed. Nonetheless, there are still some areas for improvement. So, as I did at this time last year, I’ll take the opportunity to update the “big ticket items” list.
The Old Big Ticket Items List
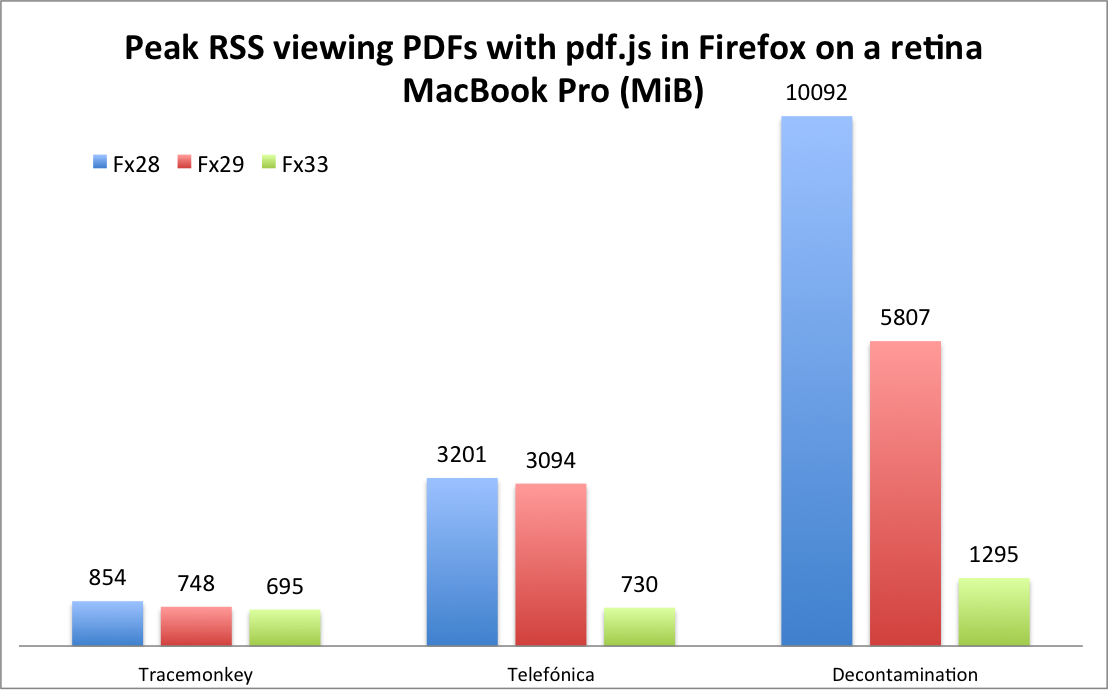
#5: pdf.js
pdf.js is the PDF viewer that now ships by default in Firefox. I greatly reduced its memory usage in two rounds, first in February, and again in June. The first round of improvements were released in Firefox 29, and the second round is due to be released in Firefox 33, which should be out in mid-October.
pdf.js will still use more memory than native PDF viewers, but the situation has improved enough that it can be removed from this list.
#4: Dev tools
See below.
#3: B2G Nuwa
Cervantes Yu, Thinker Li, and others succeeded in landing Nuwa, an impressive technical achievement that increased the amount of memory sharing between different processes on Firefox OS. This allows many more apps to run at once. I think this is present in Firefox OS 1.3 and later.
#2: Compacting Generational GC
See below.
#1: Better Foreground Tab Image Handling
Timothy Nikkel completely fixed the massive spikes in decoded image data that we used to get on image-heavy pages. This was a fantastic improvement that shipped in Firefox 26.
The New Big Ticket Items List
In a break from tradition, I will present the items in alphabetical order, rather than ranking them. This reflects the fact that I don’t have a clear opinion on the relevant importance of these different items. (I view this as a good thing, because it means that I feel there aren’t any hair-on-fire problems.)
Better regression detection
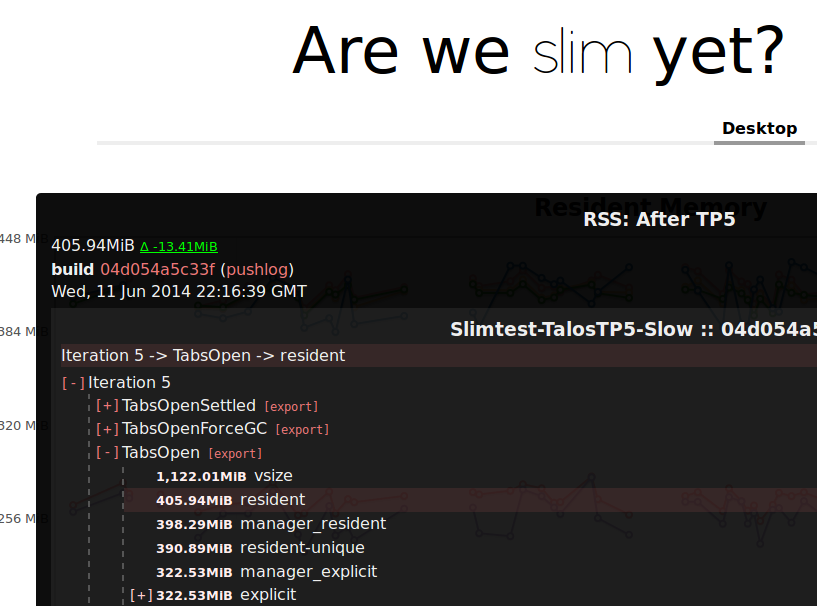
areweslimyet.com (a.k.a. AWSY) is our best tool for detecting memory usage regressions. It currently tracks Firefox and Firefox for Android, and there are plans to integrate Firefox OS.
Unfortunately, although AWSY has been successful at detecting large regressions, leading to them being fixed, its measurements are noisy enough that detecting smaller regressions is difficult. As a result, the general trend of the graphs has been upward. I do not think this is as bad as it looks at first glance, because Firefox’s behaviour in the worst cases — which matter more than the average case — is much better than it used to be. Nonetheless, improved sensitivity here would be an excellent thing, and Eric Rahm is actively working on this.
Developer tools
Developer-oriented memory profiling tools are under active development by Nick Fitzgerald, Jim Blandy, and others. A lot of the necessary profiling infrastructure is in place, and this seems to be progressing well, though I don’t know when it’s expected to be finished.
By the way, if you haven’t tried Firefox’s dev tools recently, you should! They have improved an incredible amount in the past year or so.
GC Arena Fragmentation
Generational GC landed a few months ago. I had been hoping that this would help reduce GC fragmentation, but the effect was small. It looks like compacting GC is what’s needed to make a big difference here, though some smaller tweaks may help things a little.
Tarako
Tarako is the codename for the “$25 phone” running Firefox OS that will ship in India and other countries later this year. It has a paltry 128 MiB of RAM, so memory usage is critical. Since the hardware first became available to Mozilla employees at the start of the year, Tarako has improved from “almost unusable” to “not bad”. But apps still close due to OOMs fairly frequently, especially when a user does something that involves two apps working together in some way.
There is no single change that will decisively fix this problem for Tarako; further improvements will require an ongoing grind of work from many engineers. Improvements made for Tarako are also likely to benefit higher-end Firefox OS devices as well.
Windows OOM crashes
The number of out-of-memory (OOM) crashes that occur on Windows is relatively high. A sizeable fraction of these appear to be 32-bit virtual OOM crashes, caused by running out of address space.
Things that will mitigate this include modifications to jemalloc and the JS allocator, as well as Electrolysis. And some additional data and analysis may help us understand the problem better.
The ultimate solution, for users on 64-bit versions of Windows, is 64-bit Firefox builds for Windows, though it’ll be a while before those builds are in good enough shape to ship to regular users.
Summary
Three items from the old list (pdf.js, Nuwa, image handling) have been ticked off. Two items remain (devtools, GC fragmentation), the latter in altered form, and both are a lot closer to completion than they were. Three new items (regression detection, Tarako, and Windows OOMs) have been added.
Let me know if I’ve omitted anything important!