As researchers work to understand and hopefully control the covid-19 pandemic, collaboration and sharing of data is essential. Organizations like Johns Hopkins University Center for Systems Science and Engineering and Italy’s Dipartimento della Protezione Civile are publishing data sets to help others make sense of the impact of this pandemic. At Mozilla, we’ve noticed a recent increase in desktop usage of Firefox. Because this data may have some value to researchers investigating social distancing measures in the current pandemic, we are releasing a dataset to support this collaborative effort.
To explain visually, below is a plot of daily active users (DAU) of Firefox Desktop in France. We include both the actual metric and the forecasted metric, which represents what we would expect to see if everything were normal. Following is a plot of the metric deviation from forecast.
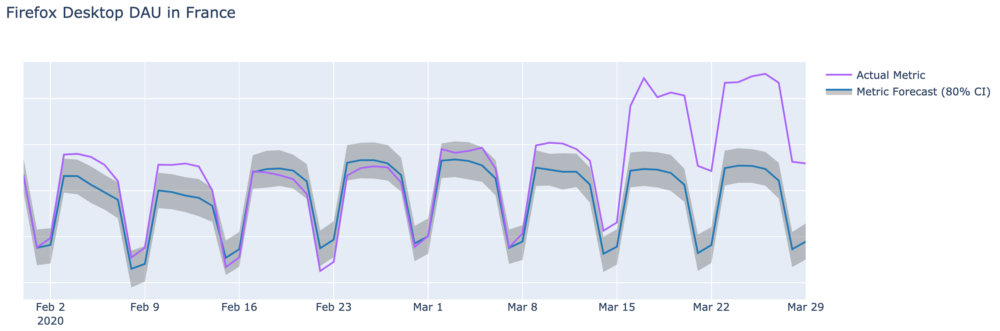
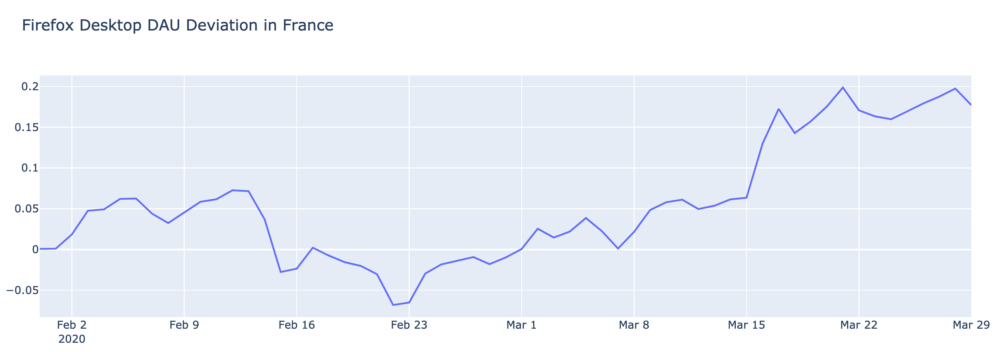
We see there is some normal range of variation, but there is a clear increase in usage outside the normal range starting on March 16th. Given the timing and unprecedented nature of the increase in desktop usage we have recorded, we think it may be related to social distancing measures being taken worldwide, although the relationship is not certain and Mozilla has not investigated alternative explanations for this increase in usage. It is possible that this data may be useful to help evaluate adherence with these measures, or even, by examining how the rate of disease growth changes following changes in Firefox usage, the impact that these measures are having.
As data scientists, we would caution other researchers that our user base may not be representative of the general population and that we are still working to understand how other factors that affect online life (like the proliferation of online education or the increased consumption of news or other covid-19 related material) affect our data, but we hope that this data will provide some value to the research community and other interested organizations. We also hope to set an example and encourage our industry colleagues to collaborate openly and share data that may be of value in ways that are consistent with respect for the privacy of their users.
We are making a table available that identifies deviations in our metrics over time for a large set of geographical units at the country and city level. As an organization steeped in openness and respect for individuals’ privacy, we are publishing this non-personal data in accordance with our commitment to an internet that catalyzes collaboration for the common good and with data practices that preserve anonymity for our users, by ensuring that all released data are based on an aggregation of at least 5000 users. Mozilla is making this database available under the Creative Commons CC0 public domain dedication. That means we have waived all copyrights to the extent we can under the law and the data is public and free to use. The data are currently available as a CSV download here or as a JSON endpoint here. This will be replaced with a public BigQuery table and a JSON endpoint soon (this post will be updated). We describe the data briefly below. Inquiries can be directed to publicdata@mozilla.com.
Details of the data
Our metrics have normal variation over time for many reasons, so rather than sharing the raw metrics, we are providing the deviation from a forecast. The forecast models what would have happened to our metrics since January 30th (the date the WHO declared a global public-health emergency) if “everything was normal,” so deviations from the forecast represent an anomaly. Not all anomalies will be related to social distancing measures, but by analyzing the patterns over time, it may be possible to develop confidence that a deviation is attributable to the measures.
The code used to produce this data is available here. We would like to acknowledge our use of Facebook’s Prophet forecasting library. Its robustness makes it possible to develop useful forecasts for thousands of different geographical units over multiple metrics in a very short time. The library is freely available under an MIT open source license and does not require sharing any data with Facebook.
The data describe the deviation from forecast of various usage metrics. Currently we include:
- “desktop_dau”, or daily active users of our desktop browser. Note that increases in DAU may be due to more frequent use by existing users or due to an influx of new users.
- “mean_active_hours_per_client” attempts to measure the mean number of hours that users in the region were actively using the browser each day.
- We hope to add more metrics in the near future.
The deviation is described as a proportion of the actual, thus the computation of deviation would be (actual – forecast) / actual. A value of 0 indicates no deviation while more extreme positive or negative values indicate unexpectedly high or low values respectively.
As it is normal that the actual values will deviate slightly from the forecasted value, the forecast provides a “80% credible interval” to capture the range of “normal” values. We also include a deviation relative to the forecast credible interval. This is calculated as (actual – forecast) / (ci_upper – forecast) where actual > forecast or (actual – forecast) / (forecast – ci_lower) otherwise. A metric just on the upper edge of the credible interval would have a value of “1” here and a value just on the lower edge would have a value of “-1”. Depending on your analysis, you may wish to consider all anomalies with an absolute value of ci_deviation less than 1 (or more) to be non-anomalous.
Schema
| date | We provide the metric deviation values for dates ranging from the beginning of 2020 to the most recent data available |
| metric | The metric being analyzed. Currently always “desktop_dau”. |
| deviation | The deviation of the metric from its forecast. |
| ci_deviation | The deviation relative to the credible interval. |
| geography | Either:
|
Caveats
As with any observational data, there are many caveats and interpretation must be done carefully. Below is a list of issues we have considered, but it is not exhaustive.
- Firefox users may not be representative of the general population in their region.
- We are applying a constantly-configured forecast model across more than a thousand geographical units. The forecast is remarkably robust, but will not perform perfectly in every case. Some deviations may be due to forecast misspecification.
- Geo data is based on IPGeo databases. These databases are imperfect, so some activity may be attributed to the wrong location. As well, updates in the IPGeo database create noise that introduces many artifactual anomalies, as such, we use only the most recent geo per profile for this analysis, which may have interactions with pandemic-related travel. Further, proxy and VPN usage can create geo-attribution errors.
- Our desktop product can be used on portable products (such as notebook computers). In our data we assume a fixed location for each profile based on the most recent telemetry ping from that profile, which may introduce some errors for users that have traveled during this time.
Updates
- 2020-4-1: Added “mean_active_hours_per_client” metric.