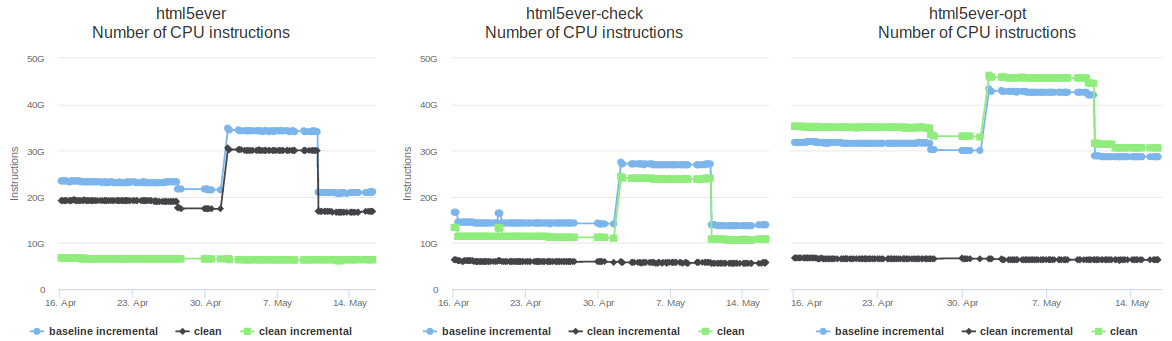
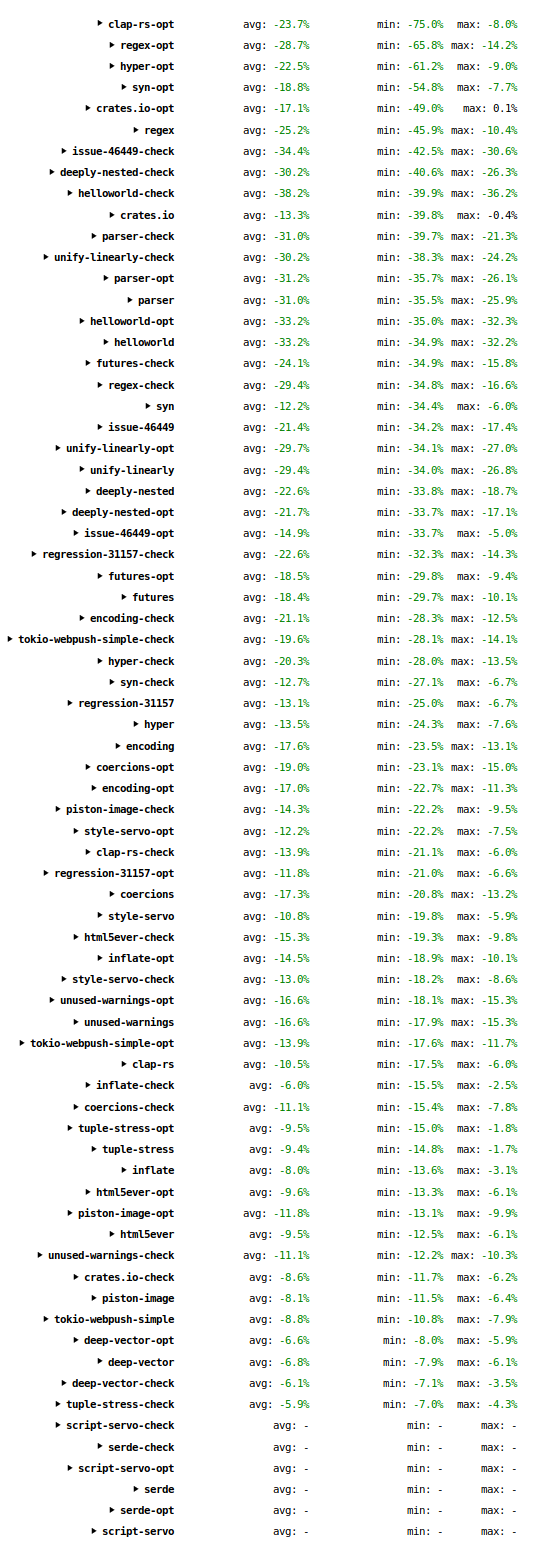
I recently wrote about some work I’ve done to speed up the Rust compiler. Since then I’ve done some more.
rustc-perf improvements
Since my last post, rustc-perf — the benchmark suite, harness and visualizer — has seen some improvements. First, some new benchmarks were added: cargo, ripgrep, sentry-cli, and webrender. Also, the parser benchmark has been removed because it was a toy program and thus not a good benchmark.
Second, I added support for several new profilers: Callgrind, Massif, rustc’s own -Ztime-passes, and the use of ad hoc eprintln! statements added to rustc. (This latter case is more useful than it might sound; in combination with post-processing it can be very helpful, as we will see below.)
Finally, the graphs shown on the website now have better y-axis scaling, which makes many of them easier to read. Also, there is a new dashboard view that shows performance across rustc releases.
Failures and incompletes
After my last post, multiple people said they would be interested to hear about optimization attempts of mine that failed. So here is an incomplete selection. I suggest that rustc experts read through these, because there is a chance they will be able to identify alternative approaches that I have overlooked.
nearest_common_ancestors 1: I managed to speed up this hot function in a couple of ways, but a third attempt failed. The representation of the scope tree is not done via a typical tree data structure; instead there is a HashMap of child/parent pairs. This means that moving from a child to its parent node requires a HashMap lookup, which is expensive. I spent some time designing and implementing an alternative data structure that stored nodes in a vector and the child-to-parent links were represented as indices to other elements in the vector. This meant that child-to-parent moves only required stepping through the vector. It worked, but the speed-up turned out to be very small, and the new code was significantly more complicated, so I abandoned it.
nearest_common_ancestors 2: A different part of the same function involves storing seen nodes in a vector. Searching this unsorted vector is O(n), so I tried instead keeping it in sorted order and using binary search, which gives O(log n) search. However, this change meant that node insertion changed from amortized O(1) to O(n) — instead of a simple push onto the end of the vector, insertion could be at any point, which which required shifting all subsequent elements along. Overall this change made things slightly worse.
PredicateObligation SmallVec: There is a type Vec<PredicationObligation> that is instantiated frequently, and the vectors often have few elements. I tried using a SmallVec instead, which avoids the heap allocations when the number of elements is below a threshold. (A trick I’ve used multiple times.) But this made things significantly slower! It turns out that these Vecs are copied around quite a bit, and a SmallVec is larger than a Vec because the elements are inline. Furthermore PredicationObligation is a large type, over 100 bytes. So what happened was that memcpy calls were inserted to copy these SmallVecs around. The slowdown from the extra function calls and memory traffic easily outweighed the speedup from avoiding the Vec heap allocations.
SipHasher128: Incremental compilation does a lot of hashing of data structures in order to determine what has changed from previous compilation runs. As a result, the hash function used for this is extremely hot. I tried various things to speed up the hash function, including LEB128-encoding of usize inputs (a trick that worked in the past) but I failed to speed it up.
LEB128 encoding: Speaking of LEB128 encoding, it is used a lot when writing metadata to file. I tried optimizing the LEB128 functions by special-casing the common case where the value is less than 128 and so can be encoded in a single byte. It worked, but gave a negligible improvement, so I decided it wasn’t worth the extra complication.
Token shrinking: A previous PR shrunk the Token type from 32 to 24 bytes, giving a small win. I tried also replacing the Option<ast::Name> in Literal with just ast::Name and using an empty name to represent “no name”. That change reduced it to 16 bytes, but produced a negligible speed-up and made the code uglier, so I abandoned it.
#50549: rustc’s string interner was structured in such a way that each interned string was duplicated twice. This PR changed it to use a single Rc‘d allocation, speeding up numerous benchmark runs, the best by 4%. But just after I posted the PR, @Zoxc posted #50607, which allocated the strings out of an arena, as an alternative. This gave better speed-ups and was landed instead of my PR.
#50491: This PR introduced additional uses of LazyBTreeMap (a type I had previously introduced to reduce allocations) speeding up runs of multiple benchmarks, the best by 3%. But at around the same time, @porglezomp completed a PR that changed BTreeMap to have the same lazy-allocation behaviour as LazyBTreeMap, rendering my PR moot. I subsequently removed the LazyBTreeMap type because it was no longer necessary.
#51281: This PR, by @Mark-Simulacrum, removed an unnecessary heap allocation from the RcSlice type. I had looked at this code because DHAT’s output showed it was hot in some cases, but I erroneously concluded that the extra heap allocation was unavoidable, and moved on! I should have asked about it on IRC.
Wins
#50339: rustc’s pretty-printer has a buffer that can contain up to 55 entries, and each entry is 48 bytes on 64-bit platforms. (The 55 somehow comes from the algorithm being used; I won’t pretend to understand how or why.) Cachegrind’s output showed that the pretty printer is invoked frequently (when writing metadata?) and that the zero-initialization of this buffer was expensive. I inserted some eprintln! statements and found that in the vast majority of cases only the first element of the buffer was ever touched. So this PR changed the buffer to default to length 1 and extend when necessary, speeding up runs for numerous benchmarks, the best by 3%.
#50391: When compiling certain annotations, rustc needs to convert strings from unescaped form to escaped form. It was using the escape_unicode function to do this, which unnecessarily converts every char to \u{1234} form, bloating the resulting strings greatly. This PR changed the code to use the escape_default function — which only escapes chars that genuinely need escaping — speeding up runs of most benchmarks, the best by 13%. It also slightly reduced the on-disk size of produced rlibs, in the best case by 15%.
#50525: Cachegrind showed that even after the previous PR, the above string code was still hot, because string interning was happening on the resulting string, which was unnecessary in the common case where escaping didn’t change the string. This PR added a scan to determine if escaping is necessary, thus avoiding the re-interning in the common case, speeding up a few benchmark runs, the best by 3%.
#50407: Cachegrind’s output showed that the trivial methods for the simple BytePos and CharPos types in the parser are (a) extremely hot and (b) not being inlined. This PR annotated them so they are inlined, speeding up most benchmarks, the best by 5%.
#50564: This PR did the same thing for the methods of the Span type, speeding up incremental runs of a few benchmarks, the best by 3%.
#50931: This PR did the same thing for the try_get function, speeding up runs of many benchmarks, the best by 1%.
#50418: DHAT’s output showed that there were many heap allocations of the cmt type, which is refcounted. Some code inspection and ad hoc instrumentation with eprintln! showed that many of these allocated cmt instances were very short-lived. However, some of them ended up in longer-lived chains, in which the refcounting was necessary. This PR changed the code so that cmt instances were mostly created on the stack by default, and then promoted to the heap only when necessary, speeding up runs of three benchmarks by 1–2%. This PR was a reasonably large change that took some time, largely because it took me five(!) attempts (the final git branch was initially called cmt5) to find the right dividing line between where to use stack allocation and where to use refcounted heap allocation.
#50565: DHAT’s output showed that the dep_graph structure, which is a IndexVec<DepNodeIndex,Vec<DepNodeIndex>>, caused many allocations, and some eprintln! instrumentation showed that the inner Vec‘s were mostly only a few elements. This PR changed the Vec<DepNodeIndex> to SmallVec<[DepNodeIndex;8]>, which avoids heap allocations when the number of elements is less than 8, speeding up incremental runs of many benchmarks, the best by 2%.
#50566: Cachegrind’s output shows that the hottest part of rustc’s lexer is the bump function, which is responsible for advancing the lexer onto the next input character. This PR streamlined it slightly, speeding up most runs of a couple of benchmarks by 1–3%.
#50818: Both Cachegrind and DHAT’s output showed that the opt_normalize_projection_type function was hot and did a lot of heap allocations. Some eprintln! instrumentation showed that there was a hot path involving this function that could be explicitly extracted that would avoid unnecessary HashMap lookups and the creation of short-lived Vecs. This PR did just that, speeding up most runs of serde and futures by 2–4%.
#50855: DHAT’s output showed that the macro parser performed a lot of heap allocations, particular on the html5ever benchmark. This PR implemented ways to avoid three of them: (a) by storing a slice of a Vec in a struct instead of a clone of the Vec; (b) by introducing a “ref or box” type that allowed stack allocation of the MatcherPos type in the common case, but heap allocation when necessary; and (c) by using Cow to avoid cloning a PathBuf that is rarely modified. These changes sped up runs of html5ever by up to 10%, and crates.io by up to 3%. I was particularly pleased with these changes because they all involved non-trivial changes to memory management that required the introduction of additional explicit lifetimes. I’m starting to get the hang of that stuff… explicit lifetimes no longer scare me the way they used to. It certainly helps that rustc’s error messages do an excellent job of explaining where explicit lifetimes need to be added.
#50932: DHAT’s output showed that a lot of HashSet instances were being created in order to de-duplicate the contents of a commonly used vector type. Some eprintln! instrumentation showed that most of these vectors only had 1 or 2 elements, in which case the de-duplication can be done trivially without involving a HashSet. (Note that the order of elements within this vector is important, so de-duplication via sorting wasn’t an option.) This PR added special handling of these trivial cases, speeding up runs of a few benchmarks, the best by 2%.
#50981: The compiler does a liveness analysis that involves vectors of indices that represent variables and program points. In rare cases these vectors can be enormous; compilation of the inflate benchmark involved one that has almost 6 million 24-byte elements, resulting in 143MB of data. This PR changed the type used for the indices from usize to u32, which is still more than large enough, speeding up “clean incremental” builds of inflate by about 10% on 64-bit platforms, as well as reducing their peak memory usage by 71MB.
What’s next?
These improvements, along with those recently done by others, have significantly sped up the compiler over the past month or so: many workloads are 10–30% faster, and some even more than that. I have also seen some anecdotal reports from users about the improvements over recent versions, and I would be interested to hear more data points, especially those involving rustc nightly.
The profiles produced by Cachegrind, Callgrind, and DHAT are now all looking very “flat”, i.e. with very little in the way of hot functions that stick out as obvious optimization candidates. (The main exceptions are the SipHasher128 functions I mentioned above, which I haven’t been able to improve.) As a result, it has become difficult for me to make further improvements via “bottom-up” profiling and optimization, i.e. optimizing hot leaf and near-leaf functions in the call graph.
Therefore, future improvement will likely come from “top-down” profiling and optimization, i.e. observations such as “rustc spends 20% of its time in phase X, how can that be improved”? The obvious place to start is the part of compilation taken up by LLVM. In many debug and opt builds LLVM accounts for up to 70–80% of instructions executed. It doesn’t necessarily account for that much time, because the LLVM parts of execution are parallelized more than the rustc parts, but it still is the obvious place to focus next. I have looked at a small amount of generated MIR and LLVM IR, but there’s a lot to take in. Making progress will likely require a lot broader understanding of things than many of the optimizations described above, most of which require only a small amount of local knowledge about a particular part of the compiler’s code.
If anybody reading this is interested in trying to help speed up rustc, I’m happy to answer questions and provide assistance as much as I can. The #rustc IRC channel is also a good place to ask for help.