En Mozilla creemos que las interfaces de voz serán una pieza clave en la interacción entre las personas y sus dispositivos en el futuro. Hoy nos complace anunciar el lanzamiento de nuestro modelo de reconocimiento de voz de código abierto para que cualquiera pueda desarrollar experiencias comunicativas interesantes.
El equipo de Machine Learning de Mozilla Research ha estado trabajando en un motor de reconocimiento de voz automático de código abierto basado en los trabajos Deep Speech (1, 2) publicados por Baidu. Uno de los principales objetivos desde el principio fue lograr una tasa de error de menos del 10% en las transcripciones en Word. Hemos progresado mucho: nuestra tasa de error de palabra en las pruebas en LibriSpeech es del 6,5%, lo que no solo logra nuestro objetivo inicial, sino que nos acerca a un rendimiento humano.
Este blogpost es una descripción general de los esfuerzos del equipo y finaliza con una explicación más detallada de la última pieza del rompecabezas: el decodificador de CTC.
La arquitectura
Deep Speech es una red neuronal recurrente profunda (RNN) a nivel de caracteres, entrenable y de extremo a extremo. En términos más asequibles, es una red neuronal profunda con capas recurrentes que transforma las características de audio en entradas y salidas de caracteres directamente: transcripciones de audio. Se puede entrenar usando un aprendizaje desde cero supervisado, sin ninguna “fuente de inteligencia” externa, como un conversor de grafema a fonema o de alineamiento forzado en la entrada.
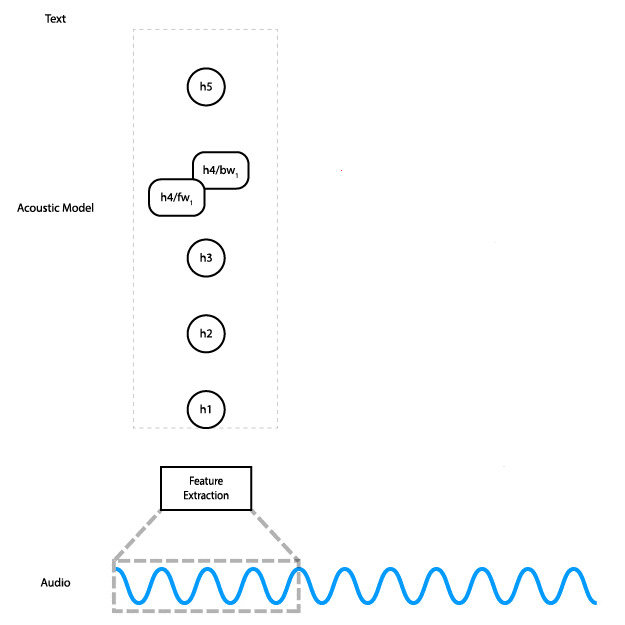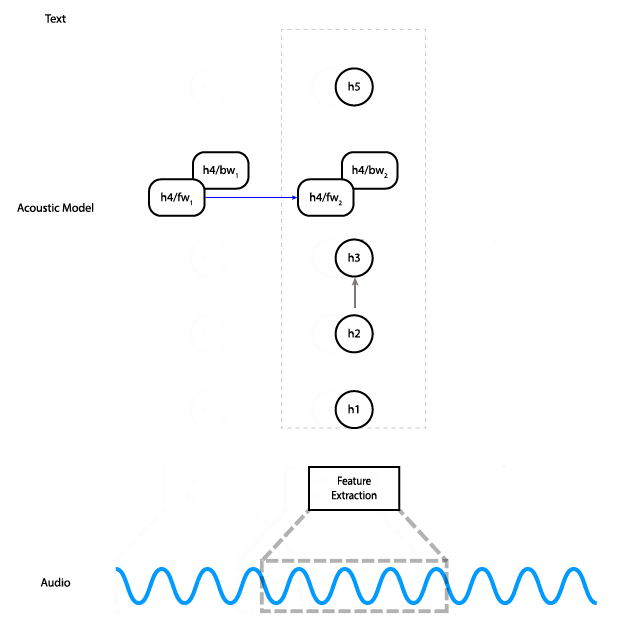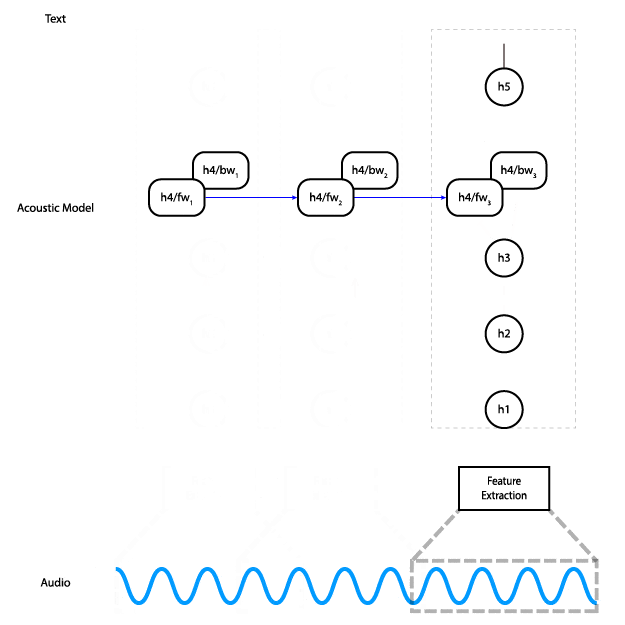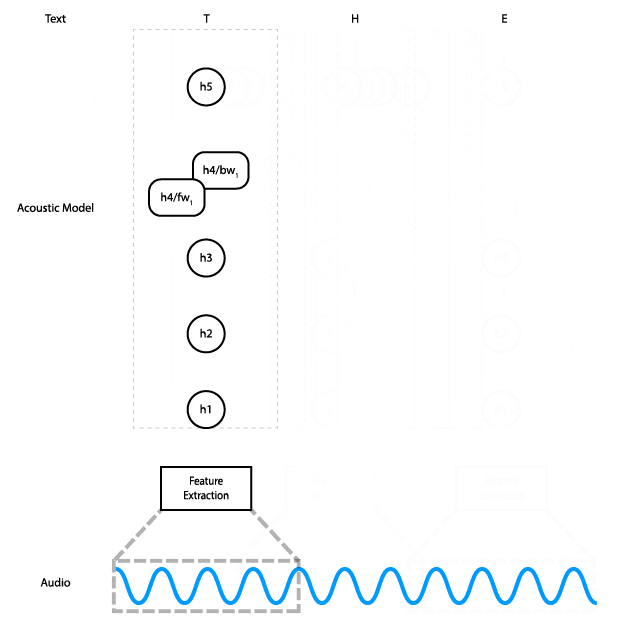
Esta animación muestra cómo fluyen los datos a través de la red. En la práctica, en lugar de procesar fragmentos de la entrada de audio de forma individual, procesamos todos los fragmentos a la vez.
La red tiene cinco capas: la entrada se sirve de tres capas totalmente conectadas, seguidas de una capa RNN bidireccional y, finalmente, una capa totalmente conectada. Las capas completamente conectadas ocultas usan la activación ReLU. La capa RNN usa celdas LSTM con activación de tanh.
El resultado de la red es una matriz de probabilidades de caracteres en el tiempo: en otras palabras, a cada paso en el tiempo la red genera una probabilidad para cada carácter del alfabeto, que representa la probabilidad de que ese carácter corresponda a lo que se dice en el audio en ese momento. La función de pérdida de CTC considera todas las alineaciones del audio y la transcripción al mismo tiempo, lo que nos permite maximizar la probabilidad de que se prediga la transcripción correcta sin preocuparse por la alineación. Finalmente, lo probamos usando el optimizador Adam.
Los datos
El aprendizaje supervisado requiere datos, montones y montones de ellos. Entrenar a un modelo como Deep Speech requiere miles de horas de audio etiquetado, y obtener y preparar esta información puede ser mucho trabajo, incluso más que implementar la red y la lógica de entrenamiento.
Comenzamos descargando corpus de voz disponibles gratuitamente como TED-LIUM y LibriSpeech, así como adquiriendo corpus de pago como Fisher y Switchboard. Escribimos importadores en Python para los diferentes conjuntos de datos que convierten los archivos de audio a WAV, dividimos el audio y limpiamos la transcripción de caracteres innecesarios como la puntuación y los acentos. Finalmente, almacenamos los datos pre-procesados en archivos CSV que se pueden usar para introducir los datos en la red.
El uso de corpus de voz existentes nos permitió comenzar a trabajar rápidamente en el modelo. Pero para lograr excelentes resultados, necesitábamos mucha más información. Tuvimos que ser creativos. Pensamos que tal vez este tipo de datos de voz ya existirían ahí fuera, en los archivos de la gente, así que nos comunicamos con emisoras de radio y TV públicas, departamentos de estudio de idiomas de universidades y, básicamente, con cualquier persona que pudiera haber etiquetado datos de voz para compartirlos. A través de este esfuerzo, pudimos duplicar con creces la cantidad de datos para entrenamiento con los que trabajar, lo que ahora es suficiente para entrenar un modelo en inglés de alta calidad.
Tener un corpus de voz de alta calidad a disposición del público no solo nos ayuda a avanzar en nuestro propio motor de reconocimiento de voz. Con el tiempo permitirá una amplia innovación, porque los desarrolladores, las start-ups y los investigadores podrán entrenar y experimentar con diferentes arquitecturas y modelos para diferentes idiomas. Podría ayudar a democratizar el acceso a Deep Learning para aquellos que no pueden pagar miles de horas de datos para entrenamiento (casi todo el mundo).
Para construir un corpus de voz que fuera gratuito, de código abierto y lo suficientemente grande como para crear productos significativos, trabajamos con el equipo Open Innovation de Mozilla y lanzamos el proyecto Common Voice para recopilar y validar las contribuciones verbales de voluntarios de todo el mundo. Hoy, el equipo lanza una gran colección de datos de voz de dominio público. Obtén más información sobre el lanzamiento en el blog Open Innovation Medium.
El hardware
Deep Speech tiene más de 120 millones de parámetros, y entrenar a un modelo de esta envergadura es una tarea muy costosa desde el punto de vista informático: se necesitan muchas GPU si no quieres tener que esperar los resultados de por vida. Estudiamos el entrenamiento en la nube, pero no funcionó en lo financiero: el hardware dedicado se paga por sí solo si se entrena mucho. Por el contrario, la nube es una buena forma de hacer exploraciones rápidas de hiperparámetros, así que tenlo en cuenta.
Comenzamos con una sola máquina con cuatro GPU Titan X Pascal, y luego compramos otros dos servidores con 8 Titan XPs. Ejecutamos las dos máquinas GPU de 8 como un clúster, y la máquina GPU de 4 anterior se quedó aparte para ejecutar experimentos más pequeños y probar cambios de código que requieren más potencia de procesamiento que la que tienen nuestras máquinas de desarrollo. Esta configuración es bastante eficiente, y para nuestras jornadas de entrenamiento más largas podremos pasar de cero a un buen modelo en aproximadamente una semana.
Configurar el entrenamiento distribuido con TensorFlow fue un proceso arduo. Aunque cuenta con las herramientas distribuidas de entrenamiento más desarrolladas en el marco del Deep learning, lograr que las cosas funcionen realmente sin fallos y aprovechar al máximo la potencia de procesamiento adicional es complicado. Nuestra configuración actual funciona gracias a los increíbles esfuerzos de Tilman Kamp, quien soportó largas batallas con TensorFlow, Slurm e incluso con el kernel de Linux hasta que todo empezó a funcionar.
Poniéndolo todo junto
En este punto, tenemos dos trabajos para guiarnos, un modelo implementado basado en esos trabajos, los datos resultantes y el hardware necesario para el proceso de entrenamiento. Resultó que replicar los resultados de un trabajo no es tan simple. La gran mayoría de los trabajos no especifican todos los hiperparámetros que utilizan, si es que especifican alguno. Esto significa que se debe dedicar mucho tiempo y energía a realizar búsquedas de hiperparámetros para encontrar un buen conjunto de valores. Nuestras pruebas iniciales con valores elegidos mediante una combinación de aleatoriedad e intuición no fueron ni siquiera cercanas a las citadas en el documento, probablemente debido a pequeñas diferencias en la arquitectura; por un lado, usamos celdas LSTM (memoria a largo-corto plazo) en lugar de celdas GRU (unidad recurrente cerrada). Pasamos mucho tiempo realizando búsquedas binarias en las tasas de abandono, redujimos la tasa de aprendizaje, cambiamos la forma en la que se iniciaban los pesos y también experimentamos con el tamaño de las capas ocultas. Todos estos cambios nos acercaron bastante a nuestro objetivo deseado de menos del 10% de la Tasa de Error de Palabras, pero no nos llevaron hasta allí.
Una pieza que faltaba en nuestro código supuso una optimización importante: la integración de nuestro modelo de lenguaje en el decodificador. La forma en que funciona el decodificador CTC (Clasificación Temporal de Conexiones) es tomando la matriz de probabilidad como si fuera un resultado del modelo y repasándolo, buscando la secuencia de texto más probable de acuerdo con la matriz de probabilidad. Si en el paso de tiempo 0 la letra “C” es la más probable, y en el paso de tiempo 1 la letra “A” es la más probable, y en el paso de tiempo 2 la letra “T” es la más probable, entonces la transcripción dada por el decodificador más simple posible será “CAT”.
Esta es una forma bastante eficiente de decodificar las probabilidades que genera el modelo en una secuencia de caracteres, pero tiene un defecto importante: solo tiene en cuenta el resultado de la red, lo que significa que solo tiene en cuenta la información del audio. Cuando un audio tiene dos transcripciones igualmente probables (piensa en “Nobel” frente a “novel”, “vaca” vs “baca”), el modelo solo puede intentar adivinar cuál es la correcta. Esto está lejos de ser perfecto: si las primeras palabras de una oración son “El científico recibió un premio”, podemos estar bastante seguros de que la siguiente palabra será “Nobel” en lugar de “novel”. Responder a ese tipo de preguntas es el trabajo de un modelo de lenguaje, y si pudiéramos integrar un modelo de lenguaje en la fase de decodificación de nuestro modelo, podríamos obtener mucho mejores resultados.
Cuando intentamos abordar este problema por primera vez, nos encontramos con un par de barreras en TensorFlow: primero, no expone su funcionalidad de puntuación de luz (beam scoring) en la API de Python (probablemente por razones de rendimiento); y segundo, las probabilidades de registro producidas por la función de pérdida de CTC eran (¿son?) inválidas. Decidimos solucionar el problema creando algo así como un corrector ortográfico en su lugar: revisar la transcripción y valorar si hay pequeñas modificaciones que pudieran hacer que aumentara la probabilidad de que esa transcripción sea válida en inglés, de acuerdo con el modelo de idioma. Esto tuvo buenos resultados al corregir pequeños errores en el resultado, pero a medida que nos acercamos cada vez más a nuestro objetivo de tasa de error, nos dimos cuenta de que no iba a ser suficiente. Tendríamos que aceptarlo y escribir algo de C++.
Beam scoring con un modelo de lenguaje
Integrar el modelo de lenguaje en el decodificador implica consultar el modelo de lenguaje cada vez que evaluamos una adición a la transcripción. Volviendo al ejemplo anterior, al analizar si queremos elegir “Nobel” o “novel” para la siguiente palabra después de “El científico recibió un premio”, consultamos el modelo de lenguaje y usamos esa puntuación como un peso para clasificar las transcripciones candidatas. Ahora podemos utilizar la información no solo del audio, sino también de nuestro modelo de lenguaje para decidir qué transcripción es más adecuada. El algoritmo se describe en este trabajo de Hannun y otros.
Afortunadamente, TensorFlow tiene un punto de extensión en su decodificador de búsqueda de CTC que permite al usuario suministrar su propio marcador de luz (beam scorer). Esto significa que todo lo que tienes que hacer es escribir el marcador de luz que consulta el modelo de idioma y conectarlo. En nuestro caso, queríamos que esa funcionalidad estuviera expuesta en nuestro código Python, por lo que también lo expusimos como una operación TensorFlow personalizada que puede cargarse usando tf.load_op_library.
Conseguir que todo esto funcionara con nuestra configuración requirió bastante esfuerzo, desde luchar con el sistema de compilación Bazel durante horas, hasta asegurarse de que todo el código fuera capaz de manejar la entrada Unicode de forma consistente y depurar el propio marcador de luz. El sistema requiere que muchas piezas trabajen juntas:
- El modelo de lenguaje en sí (utilizamos KenLM para compilar y consultar).
- Un árbol digital (trie) de todas las palabras de nuestro vocabulario.
- Un archivo de alfabeto que mapea las etiquetas enteras generadas por la red para convertirlas en caracteres.
Aunque agregar todas estas partes móviles hace que nuestro código sea más difícil de modificar y aplicar a diferentes casos de uso (como otros idiomas), ofrece grandes beneficios: nuestra tasa de error de palabra en el conjunto de prueba de LibriSpeech pasó del 16% al 6,5%, lo que no solo logra nuestro objetivo inicial, pero nos acerca a un desempeño a nivel humano (5.83% según el trabajo de Deep Speech 2). En un MacBook Pro, usando la GPU, el modelo puede crear inferencias en un factor de tiempo real de alrededor de x0,3, y alrededor de x1,4 solo en la CPU (un factor de tiempo real de x1 significa que puede transcribir 1 segundo de audio en 1 segundo).
Hemos vivido un viaje increíble para llegar a este momento: ¡el lanzamiento inicial de nuestro modelo! En el futuro, queremos lanzar un modelo que sea lo suficientemente rápido como para ejecutarse en un dispositivo móvil o una Raspberry Pi.
Si este tipo de trabajo te parece interesante o útil, visita nuestro repositorio en GitHub y nuestro Discourse channel. Tenemos una comunidad cada vez mayor de colaboradores y estamos ansiosos por ayudarte a crear y publicar un modelo para tu idioma.