The following post is based on a talk I presented at MozFest about interviewing users.
I recently had a conversation with a former colleague who now works for a major social network. In the course of our conversation this former colleague said to me, “You know, we have all the data in the world. We know what our users are doing and have analytics to track and measure it, but we don’t know why they do it. We don’t have any frameworks for understanding behavior outside of what we speculate about inside the building.”
In many technology organizations, the default assumption of user research is that it will be primarily quantitative research such as telemetry analyses, surveys, and A/B testing. Technology and business organizations often default to a positivist worldview and subsequently believe that quantitative results that provide numeric measures have the most value. The hype surrounding big data methods (and the billions spent on marketing by vendors making certain you know about their enterprise big data tools) goes hand-in-hand with the perceived correctness of this set of assumptions. Given this ecosystem of belief, it’s not surprising that user research employing quantitative methods is perceived by many in our industry as the only user research an organization would need to conduct.
I work as a Lead User Researcher on Firefox. While I do conduct some quantitative user research, the focus of most of my work is qualitative research. In the technology environment described above, the qualitative research we conduct is sometimes met with skepticism. Some audiences believe our work is too “subjective” or “not reproducible.” Others may believe we simply run antiquated, market research-style focus groups (for the record, the Mozilla UR team doesn’t employ focus groups as a methodology).
I want to explain why qualitative research methods are essential for technology user research because of one well-documented and consistently observed facet of human social life: the concept of homophily.
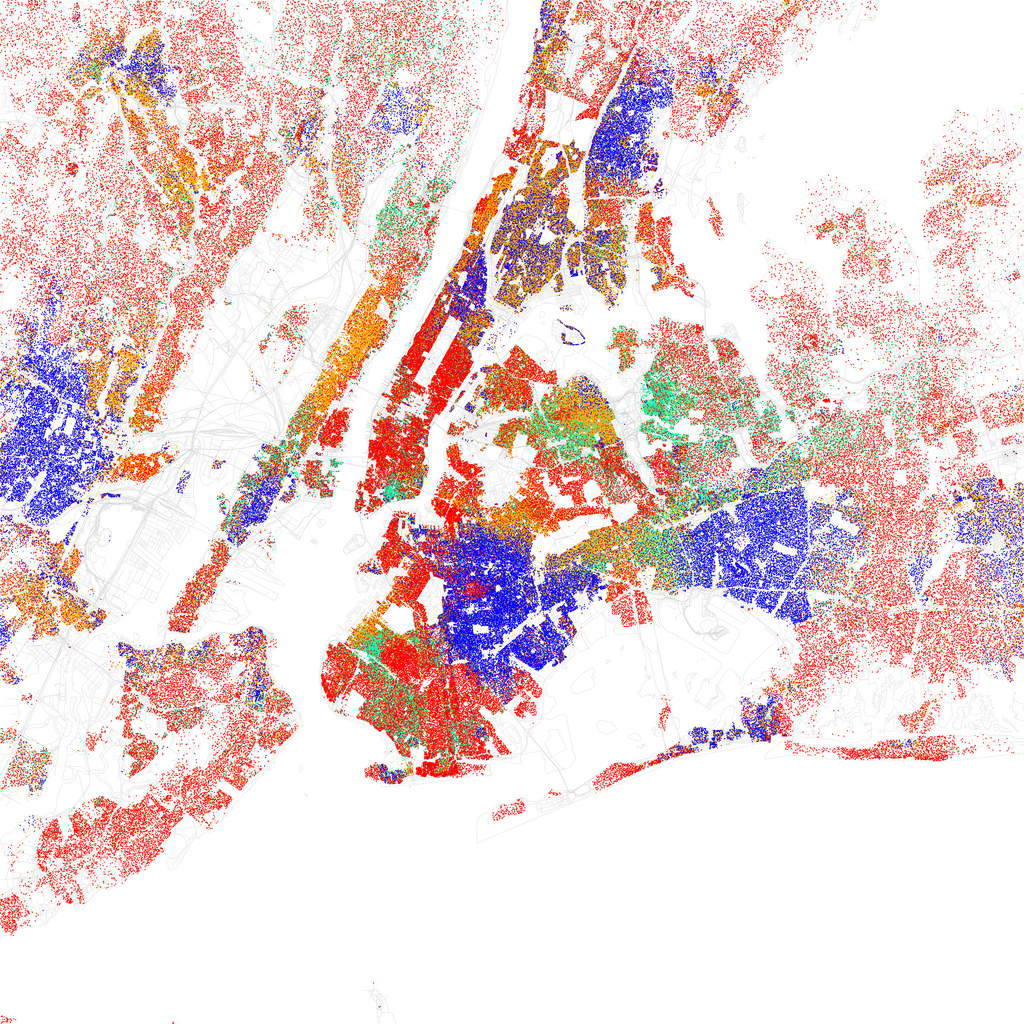
This is a map of New York City based on the ethnicity of residents. Red is White, Blue is Black, Green is Asian, Orange is Hispanic, Yellow is Other, and each dot is 25 residents. Of course, there are historical and cultural reasons for the clustering, but these factors are part of the overall social dynamic.
Source: https://www.flickr.com/photos/walkingsf/
Homophily is the tendency of individuals to associate and bond with similar others (the now classic study of homophily in social networks). In other words, individuals are more likely to associate with others based on similarities rather than differences. Social scientists have studied social actors associating along multiple types of ascribed characteristics (status homophily) including gender, ethnicity, economic and social status, education, and occupation. Further, homophily exists among groups of individuals based on internal characteristics (value homophily) including values, beliefs, and attitudes. Studies have demonstrated both status and value homophilic clustering in smaller ethnographic studies and larger scale analyses of social network associations such as political beliefs on Twitter.

Photos on Flickr taken in NY by tourists and locals. Blue pictures are by locals. Red pictures are by tourists. Yellow pictures might be by either. Source: https://www.flickr.com/photos/walkingsf
I bring up this concept to emphasize how those of us who work in technology form our own homophilic bubble. We share similar experiences, information, beliefs, and processes about not just how to design and build products and services, but also in how many of us use those products and services. These beliefs and behaviors become reinforced through the conversations we have with colleagues, the news we read in our press daily, and the conferences we attend to learn from others within our industry. The most insidious part of this homophilic bubble is how natural and self-evident the beliefs, knowledge, and behaviors generated within it appears to be.
Here’s another fact: other attitudes, beliefs, and motivations exist outside of our technology industry bubble. Many members of these groups use our products and services. Other groups share values and statuses that are similar to the technology world, but there are other, different values and different statuses. Further, there are values and statuses that are radically different from ours so as to be not assumed in the common vocabulary of our own technology industry homophilic bubble. To borrow from former US Secretary of Defense, Donald Rumsfeld, “there are also unknown unknowns, things we don’t know we don’t know.”
This is all to say that insights, answers, and explanations are limited by the breadth of a researcher’s understanding of users’ behaviors. The only way to increase the breadth of that understanding is by actually interacting with and investigating behaviors, beliefs, and assumptions outside of our own behaviors, beliefs, and assumptions. Qualitative research provides multiple methodologies for getting outside of our homophilic bubble. We conduct in situ interviews, diary studies, and user tests (among other qualitative methods) in order to uncover these insights and unknown unknowns. The most exciting part of my own work is feeling surprised with a new insight or observation of what our users do, say, and believe. In research on various topics, we’ve seen and heard so many surprising answers.
There is no one research method that satisfies answering all of our questions. If the questions we are asking about user behavior, attitudes, and beliefs are based solely on assumptions formed in our homophilic bubble, we will not generate accurate insights about our users no matter how large the dataset. In other words, we only know what we know and can only ask questions framed about what we know. If we are measuring, we can only measure what we know to ask. Quantitative user research needs qualitative user research methods in order to know what we should be measuring and to provide examples, theories, and explanations. Likewise, qualitative research needs quantitative research to measure and validate our work as well as to uncover larger patterns we cannot see.
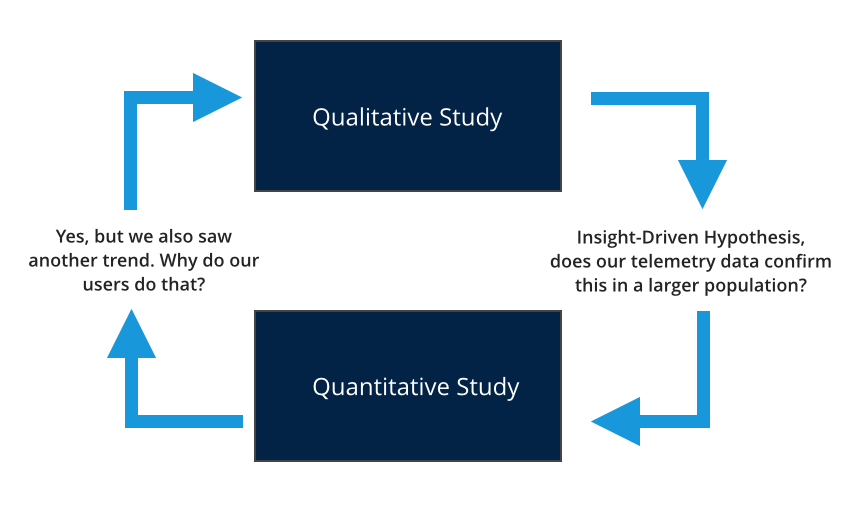
An example of quantitative and qualitative research working iteratively.
It is a disservice to users and ourselves to ask only how much or how often and to avoid understanding why or how. User research methods work best as an accumulation of triangulation points of data in a mutually supportive, on-going inquiry. More data points from multiple methods mean deeper insights and a deeper understanding. A deeper connection with our users means more human-centered and usable technology products and services. We can only get at that deeper connection by leaving the technology bubble and engaging with the complex, messy world outside of it. Have the courage to feel surprised and your assumptions challenged.
(Thanks to my colleague Gemma Petrie for her thoughts and suggestions.)
sam ladner wrote on
wrote on
Amy Santee wrote on
wrote on
Mikael wrote on
wrote on
Adam Nemeth wrote on
wrote on