At Mozilla, helping users protect their privacy and ensuring that they have control over the data collected about them is a critical pillar of everything we do. It is so important that Principle #4 of the Mozilla Manifesto states, “Individuals’ security and privacy on the internet are fundamental and must not be treated as optional.” It’s also why we build tools such as Firefox Monitor, which helps users know when their data has been accessed without their permission.
There are MANY different categories of data (here’s a list of 50 distinct categories) that constitute your online self: your name, your address, the size of your paycheck. Individually they are just small data points, but collectively, they can add up to a unique individual. Obviously, you are probably more concerned with some data categories than others. You may not care if the fact that you are single or married is public information, but you probably don’t want your home address or the size of your paycheck being easily found by just anyone.
To help us understand the types of data that people like you are most concerned about, we decided to run a survey using the MaxDiff methodology. MaxDiff is a great way to take a giant list of almost anything, and ask people to rate the attributes in the list against each other. Survey participants were presented with four random attributes from our list, and asked to choose which one they are most worried about, and which one they are least worried about. In practice, it looks like this:

We then show random sets of four attributes over and over again until the user has seen each attribute multiple times, and has had the chance to rank each attribute relative to several combinations. This gives us a nice, ranked list of attributes, as well as the following information:
- How often the participant selected “Most Worried About”
- How often the participant selected “Least Worried About”
- How often the attribute was never even selected
Using this data, we got a pretty good idea of what sorts of data users were most concerned about, which gives us a starting place to build tools and education about how to protect those most vulnerable types of data.
The Survey
We ran our survey on a paid panel of people in the United States. We tried to match a balance of age and gender that mirrored the US Census, and we surveyed 1,500 participants. We plan on eventually expanding this research to other countries in the future. All respondents were shown the MaxDiff question type shown above, as well as a variety of questions around data breaches and the bad actors that they were most worried about gaining access to their data.
The Results
The top ten most sensitive types of data:
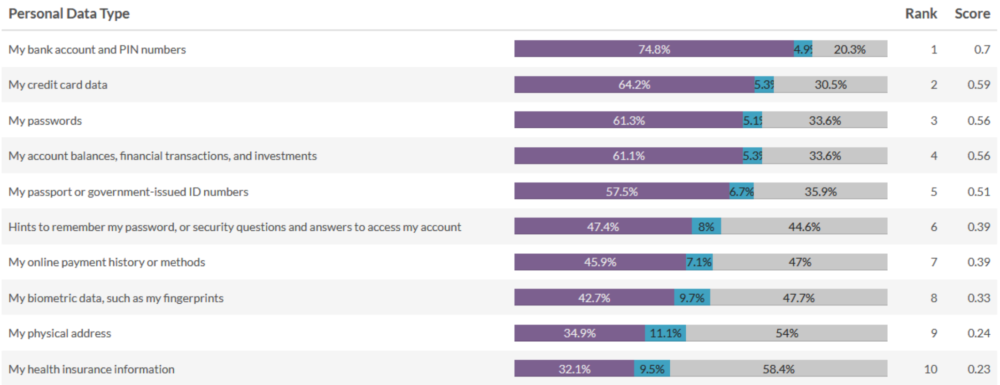
For all participants the top 10 data types from our MaxDiff question can be seen above. Some summary notes of what we find participants rated highly:
- Financial Information
- Government issued IDs
- Personal / Private information (Health, address, etc.)
This is a great exercise that lets us quantify the data and the responses to better protect users by prioritizing the data types above in our products and tools. For example, Firefox Lockbox is a project dedicated to better protecting your passwords (the 3rd most critical data-type) starting with secure, safe access to your Firefox-saved passwords on mobile.
Who are participants most concerned will gain unauthorized access to their data?
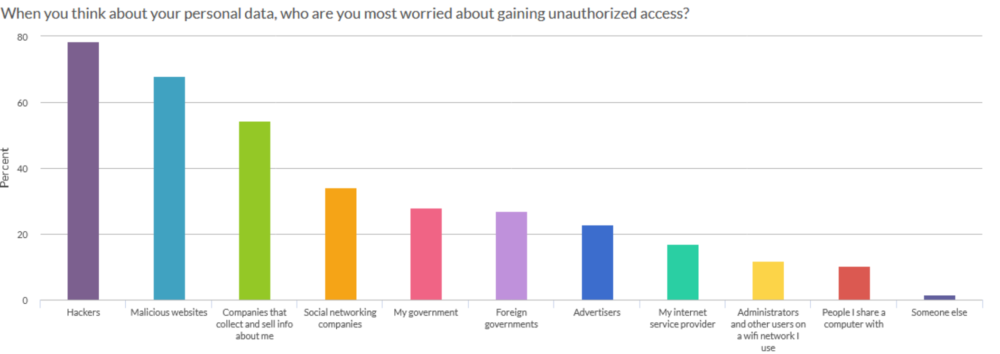
Another question we asked participants is who they are most worried about gaining unauthorized access to their data. The third top choice is “Companies that collect and sell info about me” closely followed by “Social networking companies.” Facebook Container is an awesome example of a tool that we developed that helps protect a social networking company from knowing things about you that you might not want it to know.
Something interesting to note here is 54% of respondents said they were worried about “Companies that collect and sell data about me,” but only 22.7% of respondents were worried about advertisers. This implies that there is a large portion of the population that might be OK with online advertising, if they knew that the advertising company was just that–an advertising company–and not an advertising company that also was dedicated to collecting as much information about them as possible.
These results (combined with other research) are currently being used by our Security and Privacy teams to build products that help put you more in control of what data is collected about you, and how that data is used. Look out for exciting announcements later this year, both in Firefox, and outside the browser.
I hope this dive into the user research we are doing at Mozilla was an interesting and insightful peek behind the curtain and that it highlights how we use the opinions of real people to help guide our efforts to keep the web open, safe and free.
-Tyler
Acknowledgements
Thanks to everyone who assisted both with the development and analysis of this survey, and review of this post. In no particular order; Rob Rayborn, Rosanne Scholl, Josh Gaunt, Gemma Petrie, Jennifer Davidson, Alice Rhee, Sharon Bautista and Sandy Sage.