In November there were 324 alerts generated, resulting in 54 regression bugs being filed on average 6.8 days after the regressing change landed.
Welcome to the November 2020 edition of the performance sheriffing newsletter. Here you’ll find the usual summary of our sheriffing efficiency metrics, followed by a dive into some of our other metrics. If you’re interested (and if you have access) you can view the full dashboard.
Sheriffing efficiency
- All alerts were triaged in an average of 1.1 days
- 96% of alerts were triaged within 3 days
- Valid regression alerts were associated with a bug in an average of 4.4 days
- 79% of valid regression alerts were associated with a bug within 5 days
Our performance test frameworks
This month I’m going to focus on our performance test frameworks. Our performance sheriffs currently monitor alerts for six frameworks, detailed below.
Talos
Talos is the original performance test framework for Firefox, and is still going strong today. I tried tracking down when it was introduced, but the best I could do was find where it was named, which was by Alice Nodelman in 2007 (bug 368720).
I’m not very good with project names, but in QA we seem to be in something of a greek myth kick so I would suggest ‘Talos’ after the bronze automaton that hurled rocks at unwary seamen.
Like all of our frameworks, Talos is written in Python. It is capable of measuring startup, page load, benchmarks, and much more. Unfortunately many of the Talos test owners are no longer around, which can make it difficult to troubleshoot failures and regressions. You can learn more about Talos on the project’s wiki page.
Are We Slim Yet?
Are We Slim Yet (AWSY) tracks memory usage, and was first introduced in 2012 by John Schoenick. You can learn more about AWSY on the project’s wiki page.
Raptor
Raptor was developed in 2018 as a modern solution for cross-browser page load and benchmark tests. For page loads, Raptor framework is able to replay sites recorded using mitmproxy, making it more realistic and easier to update than the Talos page load tests. In order to support running tests against other browsers it was written using a web extension. You can learn more about Raptor on the project’s wiki page.
Browsertime
This is a little misleading, as the Browsertime tests are actually run using the Raptor framework. In 2019 we started to add support for using the popular performance tool Browsertime instead of the Raptor web extension. Since then we have been gradually migrating our Raptor web extension tests to Browsertime. Integrating Browsertime provides us with valuable visual metrics (much closer to user perceived performance than the navigation timing metrics). It also gives us improved browser support by using WebDriver instead of a web extension (web extensions are not supported on Chrome for Android). The Browsertime tests are reported under a different framework to avoid confusion during the migration. You can learn more about Browsertime on the project’s wiki page.
JavaScript Shell
The JavaScript shell framework was introduced in 2018 by Andrew Halberstadt (bug 1445975) to run a variety of benchmarks against JavaScript shell builds. We enabled alerting for this framework in August 2020.
Build Metrics
Build metric is not strictly a performance framework, but the Firefox builds have various metrics that it’s important we avoid regressing such as the number of constructors, file size of the installers.
Regressions by framework
Now that I’ve introduced you to the various frameworks, let’s take a look at how many regressions each of these has found over the last 12 months. Note that I excluded the JavaScript Shell results from the following graph due to the very low number of alerts from this framework.
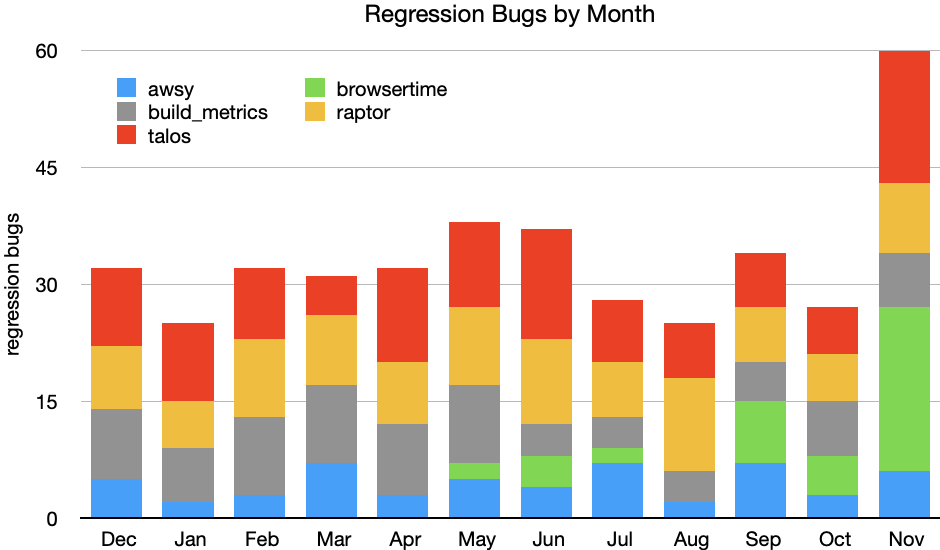
During October and November we migrated the Raptor page load tests to Browsertime on Linux and macOS hardware. Browsertime is measuring the navigation timing metrics that Raptor always has, but it also measures several visual metrics, and with more metrics we can expect more alerts. As the migration progresses we should continue to see a higher number of bugs raised from Browsertime, whilst those raised from Raptor should diminish.
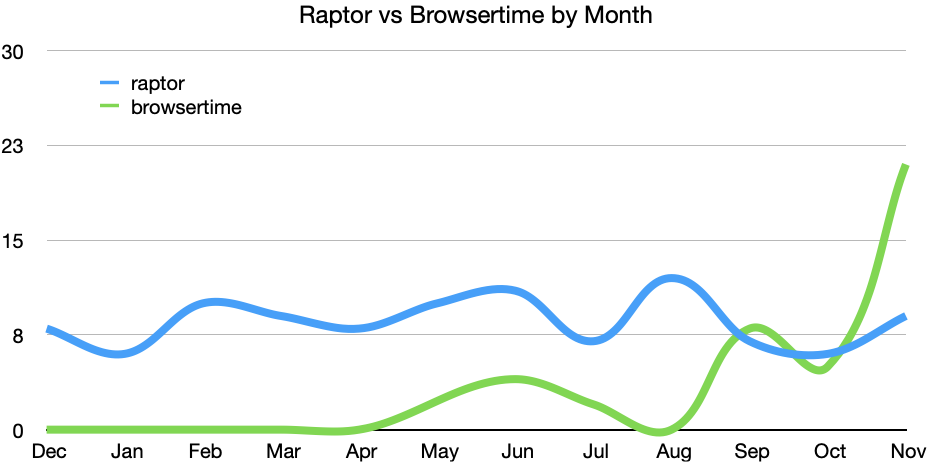
We’re currently anticipating the Windows migration to complete in January, after which we’ll move onto migrating the remaining Raptor web extension tests to Browsertime. Once complete, we’ll be able to remove all of the legacy web extension code from the Raptor framework.
Future of performance testing at Mozilla
Having so many performance testing frameworks makes it challenging for Firefox engineers to know which they should use to write a test, and which they should run when testing performance of their patches. Whilst all of these frameworks are written in Python and produce similar looking output, they have different requirements and very different command line syntax. In 2020 we have started to address this issue by introducing yet another test framework!
Don’t panic though, because the intention behind mozperftest is to eventually replace all of our other test frameworks. We already have several tests running, and we are actively encouraging all new performance tests to be written using mozperftest instead of any of the legacy frameworks listed above. If you’d like to find out more you can read the documentation, and if you have any questions you can reach out to the team in #generic-perf-tests on Matrix.
Summary of alerts
Each month I’ll highlight the regressions and improvements found.
- 😍 10 bugs were associated with improvements
- 🤐 12 regressions were accepted
- 🤩 17 regressions were fixed (or backed out)
- 🤥 2 regressions were invalid
- 🤗 2 regression are assigned
- 😨 11 regressions are still open
Note that whilst I usually allow one week to pass before generating the report, there are still alerts under investigation for the period covered in this article. This means that whilst I believe these metrics to be accurate at the time of writing, some of them may change over time.
I would love to hear your feedback on this article, the queries, the dashboard, or anything else related to performance sheriffing or performance testing. You can comment here, or find the team on Matrix in #perftest or #perfsheriffs.
The dashboard for November can be found here (for those with access).
No comments yet
Comments are closed, but trackbacks are open.