Background
mitmproxy is a third-party tool that we use to record and play back page loads in Firefox to detect performance regressions.
The page load is “recorded” to a file: the page is loaded while mitmproxy is running, and the proxy logs all requests and responses made and saves them to a file.
The page load can then be played back from this file; each response and request (referred to as a “flow”) made during the recording is played back without accessing the live site.
Recorded page load tests are valuable for detecting performance regressions in Firefox because they are not dependent on changes to the site we are testing. If we tested using only live sites, it would be much more difficult to tell if a regression was caused by changes in Firefox or changes in the site being tested.
So, as we run these tests over time, we have a history of how Firefox performs when replaying the same recording again and again, helping us to detect performance regressions that may be caused by recent changes to our code base.
Mitmproxy 7 Integration
Recently mitmproxy was updated from version 6 to version 7. Several new features and breaking changes were introduced, so this required a bit more work to get our tests working with mitmproxy 7.
The most notable change is interoperability between HTTP/1 and HTTP/2. In earlier versions of mitmproxy this was not supported, so engineers on the performance team had to do some hacking to be able to record and playback tests that used both HTTP/1 and HTTP/2. Prior to this change, mitmproxy would open a live connection to determine the protocol, which we want to avoid.
We also made a number of changes to the way that mitmproxy performs when recording and playing back.
http_protocol_extractor.py detected the HTTP protocol being used when recording and saved this to a file. This information was used when playing back to set the appropriate protocol in the playback responses.
inject-deterministic.py was (and still is) used when recording page loads to avoid errors caused by non-deterministic javascript. (For example, if the name of a resource, such as an image, is based on the date and time the page is loaded, this can cause the image to not load when the recording is played back)
The biggest changes were made in alternate-server-replay.py. This file was copied and modified from an early version of mitmproxy’s server playback addon. In this file we return only the most recent flow, and will return a 404 instead of killing the flow for any request that does not have a matching response in the recording.
We have been using that file (with some modifications over time) for playing back recordings since mitmproxy version 2.0.2 (🤯) so it withstood the test of time through several versions of mitmproxy.
But, alas, all things must come to an end. This script is not compatible with mitmproxy 7, so I copied the latest version of mitmproxy’s server playback addon and made a few small changes to achieve our desired behaviors.
When playing back recordings, we only want to return the most recent flow. This enables us to record pages requiring log-in. The engineer recording the new page load has to manually log in to the site, but we only want to test the logged in site when playing back, not the login page.
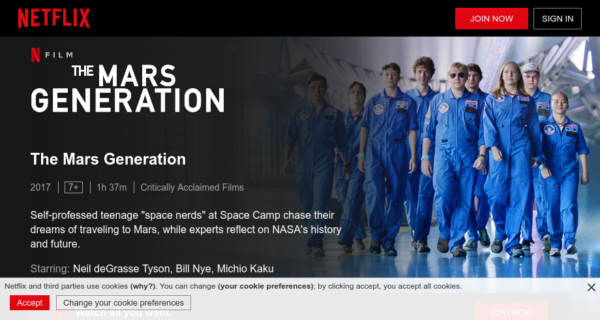
Netflix without flow order reversed
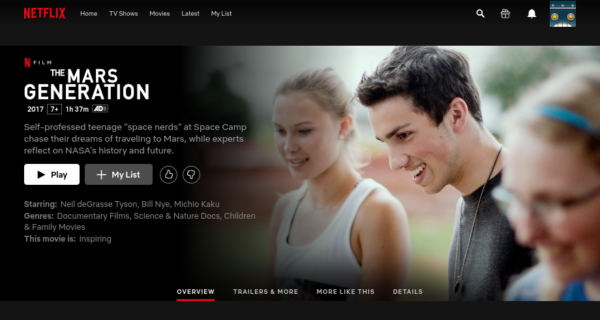
Netflix with flow order reversed shows logged in session
In previous versions of mitmproxy, we accomplished this by returning only the most recent flow in the recording file. In mitmproxy 7 I was able to achieve the same behavior by adding a new option, server_replay_order_reversed that reverses the flow order if set to true.
With the flow order reversed, I then used mitmproxy’s existing option, server_replay_nopop, so that the flow was not removed after playing, and could be replayed multiple times. Without this option, the content that was loaded was inconsistent between page loads.
The last change I made was to how the option sever_replay_kill_extra behaves. When this option is set to true, mitmproxy will kill any requests that do not exist in the recording file. As mentioned above, doing so can leave the browser still waiting for a response, causing the test to fail. Instead we return a 404 when kill_extra is set, allowing the browser to resolve these requests cleanly.
Going Forward
We plan to contribute some of this work back to mitmproxy, such as the option to reverse the flow order, and returning a 404 instead of killing unknown/extra requests.
While there are still some outstanding issues regarding the update to mitmproxy 7, as of this writing, mitmproxy 7 and a recording of amazon using mitmproxy 7 have been landed to autoland.
(And there was much rejoicing)

Thanks for reading! For more information on our page load tests and the update to mitmproxy 7, check out the resources below.
/kimberlythegeek
Related Links
- mitmproxy
- mitmproxy Blog Post on Changes in Version 7
- Page Load Test Update Tracking Doc
- Meta Bug – Required Work for mitmproxy 7 Update
No comments yet
Comments are closed, but trackbacks are open.